
动态路由革新:RouteMoA助力多智能体系统高效协同无需预推理
一篇论文已被 ACL 2026 收录,主要作者来自上海交通大学自动化与感知学院 IWIN 中心团队。该团队的负责人是关新平教授,导师包括陈彩莲教授和乐心怡教授,南洋理工大学陶大程教授亦有参与合作。其他研究人员则分别来自腾讯、上海人工智能实验室以及香港中文大学等机构。论文的第一作者王骥泽为该校博士生,专注于大型模型智能体的研究。在最近几年里,随着大语言模型的进步,从单一模型的性能提升逐渐转向多个模型
科技3 阅读
共找到 34 篇相关文章
一篇论文已被 ACL 2026 收录,主要作者来自上海交通大学自动化与感知学院 IWIN 中心团队。该团队的负责人是关新平教授,导师包括陈彩莲教授和乐心怡教授,南洋理工大学陶大程教授亦有参与合作。其他研究人员则分别来自腾讯、上海人工智能实验室以及香港中文大学等机构。论文的第一作者王骥泽为该校博士生,专注于大型模型智能体的研究。在最近几年里,随着大语言模型的进步,从单一模型的性能提升逐渐转向多个模型

在AI时代,算力差异正成为一种昂贵的智商税。作者|Moonshot试想一个场景。近日,在闲鱼上挂出一辆闲置自行车并设定了底价后,仅过了十分钟,手机就显示你的专属AI助手已经与另一位买家的AI助手完成了多次议价,并最终以超出心理预期的价格售出了该车。整个过程除了拍摄照片和设定价格外,用户几乎无需额外操作。这一场景正是Anthropic公司在内部进行的一项名为「Project Deal」的实验中的一个
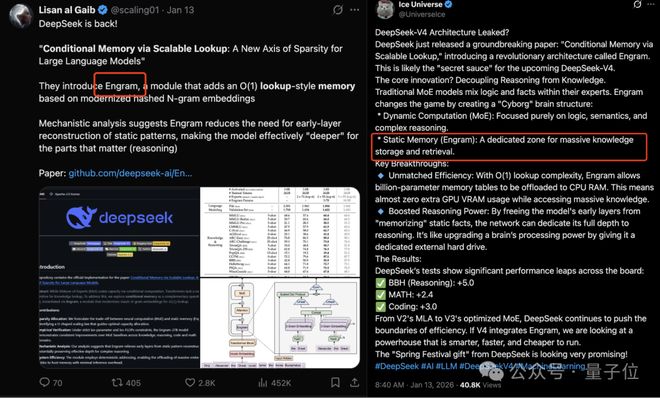
最近,关于DeepSeekV4的技术报告引起了广泛关注。报告中列举了多项技术特性,包括mHC、CSA、HCA、Muon和FP4等,但未提及Engram。由于这一情况,人们纷纷热议这个话题。Engram去哪了?Engram是在今年一月由DeepSeek与北京大学联合开源的项目,旨在研究大型模型的记忆效率问题。自从发布以来,关于它的讨论从未间断过。它不仅被视为V4版本的重要预兆,还因为它能显著提高模型
本文由一位专业的新闻编辑整理而成。当前,具身智能技术的发展遇到了一个明显的瓶颈:缺乏大规模的真实世界数据和经验积累。近年来,随着VLA等大型模型的出现,机器人在预训练阶段取得了显著的进步。然而,当它们进入实际应用场景时,问题便显现出来——由于物理世界的复杂性和多变性,机器人的性能难以持续改进,并且仍然高度依赖于人工标注的数据和重复的学习过程。这表明,具身智能还未达到“大规模增长”的关键阶段。实验室

补充Agent在基础设施方面的知识。作者|田思奇自2025年以来,大型模型的应用已经从简单的聊天机器人发展成为能够独立执行任务和流程的“数字员工”。开源框架OpenClaw无疑是这次技术飞跃的关键推动力。然而,当各个行业满怀期待地将这些工具引入内部网络时,却发现它们在实际使用中存在不少问题,在企业级环境中显得不够完善甚至有些风险。它的高灵活性在企业的IT视角下被视为越权的风险;动态生成不可信代码随

大模型在推理方面的能力愈发强大,并且广泛应用于分析、规划乃至提供建议等场景中。然而,它们的准确性和可靠性之外,更值得关注的问题是这些模型是否能够保持诚实。新加坡国立大学 Bingsheng He 教授团队最近发表于 ICLR 2026 Oral 的论文,则聚焦于一个更加贴近日常应用的情景:用户常常故意误导大模型说谎;而这项研究则深入探讨,在没有刻意引导的正常提问情况下,这些模型是否会出现矛盾或策略

从 DeepSeek-R1 到 Kimi K2.5,利用强化学习(RL)来优化大型模型的推理性能已成为关键方法。然而,在 RL 后训练过程中存在一个重要问题:这种训练方式是否遵循特定规律?能否通过给定参数量、计算资源和数据规模,准确预测出 RL 训练所能达到的效果?中国科学技术大学与上海人工智能实验室等机构的研究团队对此进行了系统性的研究。他们使用 Qwen2.5 系列密集模型(从0.5B到72B

智东西作者 程茜编辑 心缘最近,DeepSeek在其官方网站更新了API文档,并宣布将DeepSeek-V4-Pro的定价下调至原价的四分之一,这一优惠活动将持续到5月5日午夜。根据最新的信息,调整后每百万Tokens的成本(包括缓存命中和未命中的情况)分别为0.25元和3元,输出成本为6元。这次降价举措表明了DeepSeek对市场的重视以及其策略的变化。与国内其他大型模型公司的API价格相比,即
近日,一个名为“元智医疗视频理解大模型”的新工具在GitHub和Hugging Face社区上线。该工具是全球规模最大的医疗视频理解模型之一,并且它的性能指标也达到了行业顶尖水平。其中一项令人瞩目的特性在于其能够解析并理解手术视频内容,这一突破性进展已经在计算机视觉领域的顶级会议CVPR上得到了认可。此外,该研究团队还发布了一套包含6245个视频-指令对的标准测试集,旨在为医疗视频的理解提供一个通

智东西编译 ZeR0编辑 漠影据报道,谷歌近日宣布向Anthropic PBC注入100亿美元的初始投资,并在满足特定业绩目标后可能进一步追加300亿美元的投资承诺,此举旨在帮助该公司显著提升其计算资源。Anthropic是一家由OpenAI前高管创立的企业,在成立两年内迅速成长为全球估值最高的大型模型公司之一。今年2月,该公司完成了价值30亿美元的G轮融资,投后估值达到了惊人的3800亿美元,并
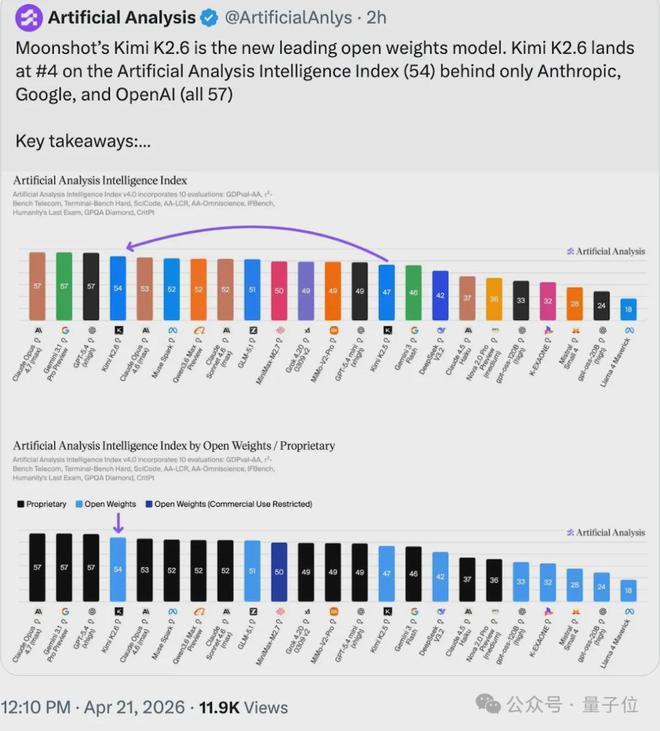
克雷西 发自 凹非寺量子位 | 公众号 QbitAI目前,大型模型的更新速度之快令人目不暇接,但主要发展方向大致相同:规模更大、性能更强、运行更快。然而,Kimi最近一次的升级则采取了不同的路径。昨晚,月之暗面发布了其最新版本的K2.6模型,并将其开源。此次更新有两个关键点:一是增强了代码编写能力,包括软件工程和前端设计水平;二是提升了多智能体协作“集群”功能。先来看排行榜,Kimi K2.6在A

五家领先的国产大模型企业在2026年选择了哪些最佳的发展路径?自今年年初以来,这些企业动作频繁且变化多端,连行业内部人士都感到难以捉摸。据悉,一向不愿讨论上市和融资问题的DeepSeek已开始接触外部资本;智谱新Coding模型口碑迅速上升;MiniMax和智谱在上市后市值分别飙升至4000亿及3000亿港元;阿里巴巴也进行了一系列重大组织重组。这些现象背后的原因是什么?一位资深业内人士向数智前线

在人工智能领域,中国正在避开大型模型的发展路径,直接迈向智能体时代。这并不是一场追赶游戏,而是一次赛道转换。▌一、奥地利程序员为中国的AI发展提供了创新的解决方案一项统计数据在2026年第一季度引起了整个行业的震动:中国的大规模模型日均调用量首次超过了美国。而这次超越的关键在于成本和效率,而非技术上的领先。中国企业迅速适应并利用了开源框架,实现了从开发到应用的快速转化。第二层因素是强烈的降本增效需

摘要:群核科技作为“杭州六小龙”之一,即将在香港上市,并凭借B端订阅业务获得了近5700万元的调整后净利润,在众多AI初创企业中脱颖而出。在过去两年里,人工智能行业的主导趋势是大量投入资金。作者|路春锋无论是大型模型公司还是各种AI应用,它们都处于用户增长和商业变现之间的拉锯战。在所有AI公司都在烧钱的情况下,谁能最先找到盈利路径?答案并不属于那些专注大模型或聊天机器人的公司,而是一家看起来与传统

据《金融时报》报道,在本周日英国的监管机构正在与政府网络安全部门及各大银行进行紧急讨论,以评估人工智能公司 Anthropic 最新推出的大型模型所带来的潜在风险。报道指出,有两名消息人士透露,包括英国央行、金融行为监管局和财政部在内的多名官员正联合国家网络安全中心共同审查 Anthropic 新 AI 模型可能暴露的关键信息系统漏洞。该媒体称,在未来两周内,英国有多家银行、保险公司以及交易所的代

量子位 | QbitAI 发布了一篇关于人工智能和机器人领域的文章。在这一领域,存在一种反常现象:人类认为复杂困难的任务对机器人而言相对容易;而一些看似简单的感知与运动技能却让机器难以实现。比如AlphaGo可以轻易战胜围棋高手,但若将其功能移植到一个机器人中,则可能连一只猫都抓不住。再者,尽管大型模型能够解决数学奥林匹克竞赛中的难题,但在操控机械手精确地拿起一支笔并书写答案时却显得力不从心。人类
在2026年,人工智能的发展正以前所未有的速度改变着技术的边界。大型模型训练效率不断提高、具身智能从实验室走向实际应用的步伐加快以及多模态融合技术逐渐成熟等一系列进展描绘了当前最令人振奋的人工智能发展图景。与此同时,代理技术(Agent)的进步正在重新定义人机协作的可能性,并引发了关于如何使这些智能体具备持续学习和自主决策能力的研究热潮。在这样一个背景下,一年一度的 ICLR 成为了观察全球人工智

出品 | 网易科技经过长达九个月的努力和数百亿美元的投资,马克·扎克伯格终于推出了一个能够与OpenAI竞争的闭源人工智能模型。4月9日,Meta公司突然发布了全新的Muse AI模型系列,首个推出的版本被命名为Muse Spark。自去年夏天建立超级智能实验室以来,前Scale AI负责人汪韬带领团队封闭工作九个月,彻底重写了整个系统的基础设施和架构。Muse Spark的核心优势在于其深入的多

强化学习已成为推动大型模型性能飞跃的关键技术手段。从OpenAI的o3、DeepSeek-R1到Gemini 3,这些前沿模型通过不断微调强化训练来提升解决复杂推理任务的能力。然而,在这一过程中也逐渐暴露出一个问题:随着训练的深入,策略分布趋向集中,探索能力随之减弱,最终导致优化欠收敛和性能瓶颈。这种现象从根本上说是由于在强化学习中探索与利用之间的不平衡造成的,并且在稀疏奖励的可验证奖励强化学习(

4月1日,“字节跳动Seed”公众号宣布启动针对2027届毕业生和在校实习生的大规模人才招聘项目。据了解,今年的招聘计划将更加注重人才引进,目标是在全球范围内招募约百名在大模型领域表现出色的应届生和技术实习生。在挑选候选人时,Seed坚持采用业界最严格的标准,寻找那些技术信念坚定、具有远大抱负,并且具备卓越研究能力和实践能力的人才。除了要求应聘者在其专长的技术领域内拥有深刻的理解和显著成就之外,S