
强化学习已成为推动大型模型性能飞跃的关键技术手段。从OpenAI的o3、DeepSeek-R1到Gemini 3,这些前沿模型通过不断微调强化训练来提升解决复杂推理任务的能力。然而,在这一过程中也逐渐暴露出一个问题:随着训练的深入,策略分布趋向集中,探索能力随之减弱,最终导致优化欠收敛和性能瓶颈。
这种现象从根本上说是由于在强化学习中探索与利用之间的不平衡造成的,并且在稀疏奖励的可验证奖励强化学习(RLVR)模式下,这一问题被进一步放大了。
在过去的一年里,人们尝试通过提高token输出分布的熵值来维持模型生成内容的多样性。但是这种方法忽视了一个更为根本的问题:token仅仅是模型内部状态在解码过程中的简化表示,不可避免地丢失了一些计算信息,并不是推理本身的核心部分。因此,当调整局限于输出层面时,真正的推理解算过程所在的空间并未得到充分挖掘。
这引发了新的问题:仅仅增加token的多样性是否能真正提升模型的整体探索能力?还是说探索与利用的本质其实藏在内部计算过程之中?
香港理工大学和上海人工智能实验室的研究团队将研究重点转向了模型内部,他们发现大型模型的工作不仅仅是序列生成的过程,而是可以通过动力学视角来理解:其本质是高维空间内隐层状态的连续演变,这一过程揭示了模型内部的计算逻辑。
基于这一洞见,该团队提出了ReLaX框架,在策略优化过程中直接调节模型内部的动力学结构,而非仅仅关注token生成的多样性。通过这种方式,在更深层次上实现了探索与利用之间的平衡。

- 论文链接:https://arxiv.org/abs/2512.07558
- 开源权重:https://huggingface.co/collections/SteveZ25/relax-checkpoints
- Github: https://github.com/ZhangShimin1/ReLaX
ReLaX的核心方法解析
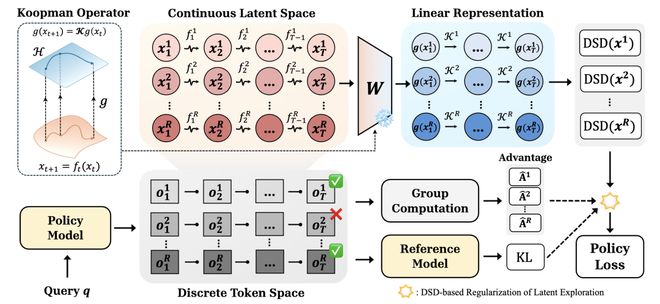
一方面,隐空间探索:从随机扰动到真实探索
大型模型的推理不仅涉及token输出的变化,还包含高维空间中复杂状态的连续变化。ReLaX将这一过程视为一个动态系统,并通过引入采样温度、top-p和top-k等机制来推动隐层状态偏离原有的路径。
然而,仅在输出层面增加随机性往往不足以充分释放模型内部探索潜力的关键在于:只有当模型的内在动力学足够丰富时,这些小范围内的变化才能被放大成多样化的隐空间轨迹。
另一方面,动态谱散度(DSD):量化隐空间动力学模式的多样性
如何捕捉大模型内部复杂且非线性的动力学特征?Koopman算子提供了一种解决方案,它允许我们将复杂的非线性系统演化简化为可解析的线性视图。
在此框架下,ReLaX采用了先进的ResKoopNet技术,将最后一层隐状态的动态变化映射到一个易于分析的线性空间中。通过计算单个轨迹内部动态谱模长方差的DSD指标,可以准确量化模型在推理过程中的“异质性”程度。
DSD为评估大模型内部思维多样性的提供了新工具:它不仅揭示了内在计算复杂度,还指明了探索与利用策略优化的方向。
基于DSD的策略优化:让探索更有方向
利用DSD指标作为量化隐空间探索能力的标准,ReLaX在GRPO算法中引入了一套序列级正则化机制。
该方法设计了两个关键部分:
- 其一是优势塑形:这种方法仅对那些能带来正面效益的轨迹施加影响,避免了模型无意义地探索低效路径。
- 另一个则是自适应KL正则化:通过对超阈值动态谱施以惩罚来防止过度发散,并为潜在有价值的轨迹保留足够的探索空间。
ReLaX不仅提升了探索能力,还通过调优隐层计算的灵活性,在确保训练稳定的前提下促进了更深层次推理路径的发现。
实验结果表明:ReLaX能够打破RLVR性能瓶颈并持续释放大模型潜力
从多样性束缚中解脱出来
研究人员在纯文本和多模态视觉-语言大型模型上测试了ReLaX的效果,并与GRPO进行了对比。
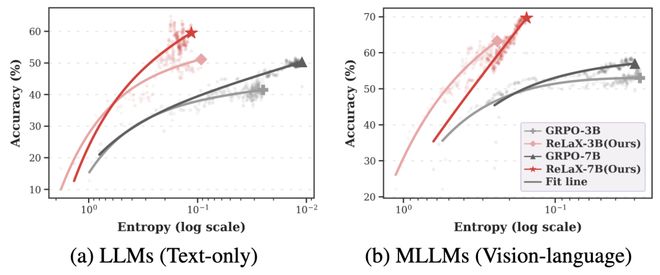
在训练过程中,通过观察性能及token熵的变化图可以明显看出模型是否陷入了由于缺乏多样性而导致的次优收敛状态。
GRPO方法在训练初期能够保持良好的探索性,但随着训练进展策略熵迅速下降,导致模型过早陷入单一路径。相比之下,ReLaX在整个训练过程中不仅维持了性能的持续增长,同时也避免了模式崩溃问题的发生,展示了其促进探索的同时也顺应了RL对信号利用的需求。
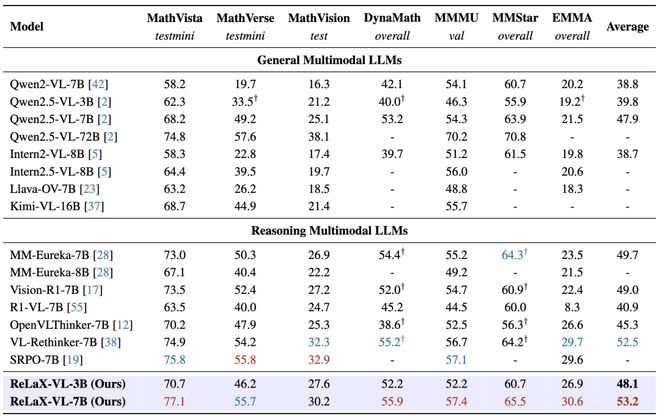
ReLaX在多模态推理任务上取得了显著成就:7B规模模型在多个基准测试中达到了53.2%的平均准确率,打破了同尺度模型性能记录。而较小规模(3B)的ReLaX也展现了强大的竞争力,甚至超越了一些更大的模型。
从Token到Latent:推理与泛化能力的双重提升
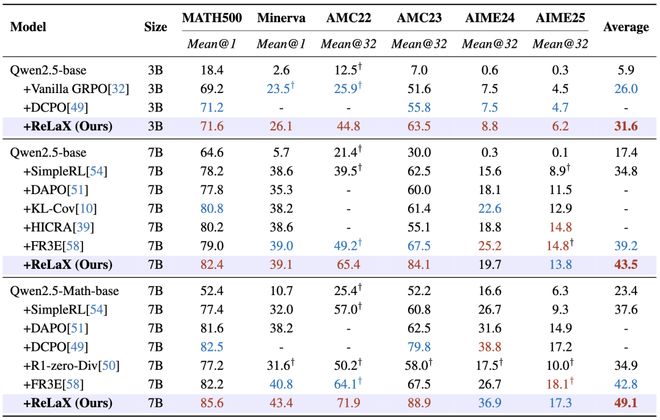
数学推理任务作为RLVR的重要应用场景,一直是验证方法有效性的关键领域之一。基于Qwen2.5-base和Qwen2.5-Math基础模型进行了一系列对比实验。
实验表明,在多项数学推理基准测试中,ReLaX显著超越了依赖token多样性的其他方法。
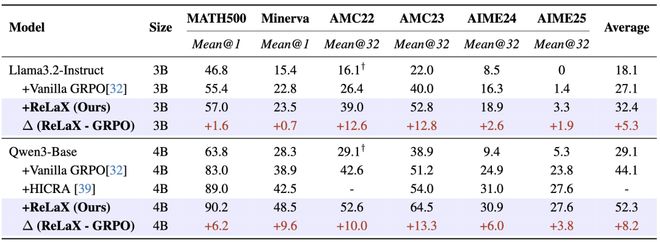
进一步地,研究者还将这种方法应用于不同的架构(如Llama3.2-Instruct和Qwen3-base)上,并同样观察到了性能的提升,证明其广泛的适用性及跨模型泛化能力。
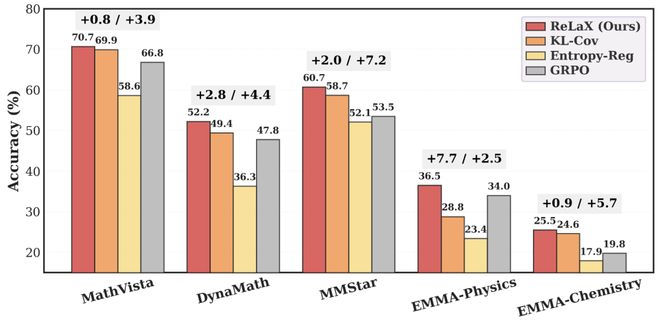
在多模态推理任务中,ReLaX相比直接操作token层面的方法展示了更显著的优势。通过对比不同方法在视觉-语言理解上的表现,可以发现直接调节latent层更能有效激活跨模态信息交互。
这表明仅靠增加输出层面的探索性不足以改善多模态模型内部的信息融合能力。
ReLaX的作用机制揭示了大模型内在计算过程的关键特性,有助于未来开发更高效的方法来提升其推理能力和泛化性能。
前景展望:深入探究大型模型背后的“深海”
ReLaX的意义不仅在于提高了性能,更重要的是提供了一个理解大型模型内部运作的新视角。
通过调节隐层的动力学而非直接干扰输出层面的不确定性,可以更有效地解决探索与利用之间的难题。未来的研究将不再局限于表面现象,而是深入探讨模型背后的计算本质。
大型模型内部复杂的高维状态空间正逐渐成为研究的新热点,其中蕴含的信息为理解模型行为和提升其能力提供了新的切入点。
ReLaX只是一个开始,随着我们对这一领域更深层次的探索,大型模型或许可以发展出更为接近人类认知过程的推理能力。
未来展望:走向大模型内在机制的 “深水区”
ReLaX 的意义并不止于性能提升,它更重要的价值在于提供了一种全新的视角去理解大模型推理过程中的计算本质。
- 相比直接 “扰动” token 空间的概率,引导模型在隐空间中的动态演化,是解决 “探索–利用” 权衡的一种更具原则性的路径。未来,我们对模型探索能力的理解,将不再局限于输出层的不确定性。
- 大模型的隐空间作为一片尚未被充分探索的 “蓝海”,正逐渐显现出其作为研究前沿的核心价值。其中高维状态所承载的丰富信息,刻画了隐藏在表层文本输出下的内在计算过程,为我们理解模型行为并提升其能力提供了新的切入点。
ReLaX 只是一个起点。随着我们不断深入这一 “隐空间”,大模型或许将不再只是概率预测的工具,而是能够在其丰富的内部表征中进行持续探索、自我修正,逐步演化出更接近 “认知过程” 的推理能力。