近日,一个名为“元智医疗视频理解大模型”的新工具在GitHub和Hugging Face社区上线。
该工具是全球规模最大的医疗视频理解模型之一,并且它的性能指标也达到了行业顶尖水平。
其中一项令人瞩目的特性在于其能够解析并理解手术视频内容,这一突破性进展已经在计算机视觉领域的顶级会议CVPR上得到了认可。
此外,该研究团队还发布了一套包含6245个视频-指令对的标准测试集,旨在为医疗视频的理解提供一个通用的评估标准。
这种大规模且高精度的数据集开放在行业内尚属首次。
为了验证模型的实际性能,研发人员已经进行了多轮实验,并取得了令人印象深刻的结果。
uAI Nexus MedVLM的核心优势在于其能够处理来自八个专业医学数据集中的多种手术场景视频,包括内镜、腹腔镜以及开放性手术等各类操作。
在实际应用中,该模型不仅可以帮助医生进行术前准备和术后总结,还能在手术过程中提供实时指导,并对潜在的风险及时预警。
与现有的一些通用大模型相比,uAI Nexus MedVLM在多个关键指标上都表现出明显的优势。例如,在安全性评估、动作定位以及视频报告生成等方面均取得了显著成绩。
到底有多能打?
更值得一提的是,通过强化学习技术的优化,该模型还进一步提升了其对手术器械和步骤识别的能力。
- 在实际演示中,研究人员选取了一段护士护理操作的视频进行测试。结果显示,uAI Nexus MedVLM能够准确地预测并描述出脉搏测量的具体时间区间。
- 为何手术视频会成为人工智能研究的一个难点?原因在于获取此类数据存在诸多挑战,包括严格的隐私保护和伦理问题。
- 此外,缺乏统一的评测标准也是一大障碍。各家公司往往使用不同的指标进行评估,这使得模型之间的性能比较变得困难。
实测效果咋样?
最后,手术视频的理解任务本身也非常复杂,需要高度的专业知识来解析其中的空间、时间和语义信息。
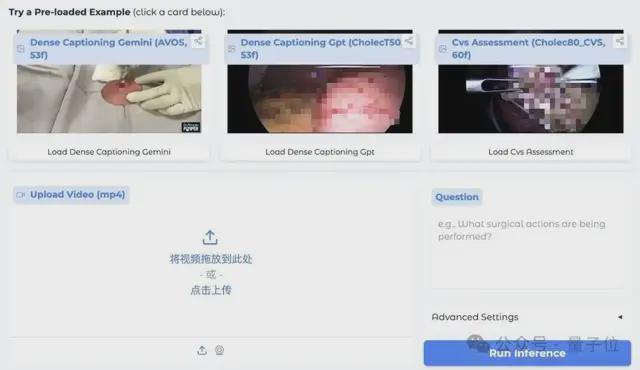
面对这些挑战,uAI Nexus MedVLM提供了一种全新的解决方案。它不仅展示了技术上的突破,更为医疗领域带来了实际的应用价值。
具体而言,在术前阶段,该模型可以帮助医生分析大量手术视频中的最佳实践;在手术过程中则可以实时监控操作的安全性,并及时发出警告信号;术后还能自动生成结构化的报告文档。
对于那些经验不足的基层医院来说,这一技术的应用有望极大地缩短年轻医生的学习曲线。
除此之外,此次发布还具有重要的开放科学意义。联影智能公司首次向全球开发者社区公开了其大规模高质量医疗视频数据集和模型,并提供了一个可以跨平台使用的评估基准体系。
这种做法打破了以往各家公司封闭式开发的局面,为更多创新力量的加入创造了条件。
随着越来越多的研究机构和个人参与到这一项目中来,相信未来将会有更多的突破性成果诞生。
总而言之,uAI Nexus MedVLM不仅标志着医疗视频理解领域的重大进展,也为全球范围内的人工智能技术合作提供了新的机遇。
而通过MedGRPO强化学习优化后,相比基座模型,uAI Nexus MedVLM的器械定位能力提升14%;手术步骤识别能力暴涨52%;手术描述质量提升16%~25%。
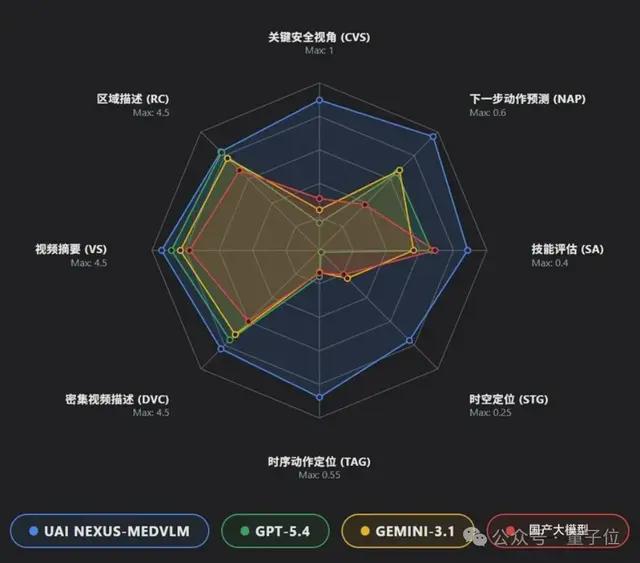
uAI Nexus MedVLM覆盖内镜腔镜手术、开放式手术、机器人手术、护理操作等多类临床场景,涵盖了8个手术数据集中的8个任务:
视频摘要(VS)、关键安全视野评估(CVS)、下一步操作预测(NAP)、技能评估(SA)、时间动作定位(TAG)、密集视频描述(DVC)、区域级描述(RC)和时空基础化(STG)。
每项任务的表现都超越了GPT和Gemini。
再看定性实测的结果,把一段被标记了绿色框的手术视频发给大模型,让它描述。
输入问题:你是一名专攻微创手术的外科分析专家。这段视频展示了腹腔镜胆囊切除术的内镜画面。请描述0.0秒时,边界框内物体的状态,以及在0.0~29.0秒时间段内的操作。

标准答案是:钳持续夹持并将胆囊向手术视野的左上方牵拉,提供反向牵引和暴露。
GPT-5.4这边呢,它只能给出笼统的描述,未能识别出具体器械。
Gemini-3.1则将工具错误识别为“电凝钩”,描述成了不正确的操作。
某国产大模型:则无法识别出正确的手术操作步骤。
只有uAI Nexus MedVLM,给出了接近标准答案的描述:
位于左上方的抓钳持续向上并朝中央牵引胆囊,保持张力并为钩子暴露分离平面。
随后,我看了下示例给出的8个任务表现,一个比一个令人震撼。
为避免真实手术场景带来的观感不适,我们选取了一段温和的示例视频,内容是护士给患者监测身体指标。
视频涵盖了护士查看血压计、查看体温计、护理记录、洗手、测量血压、测量体温、脉搏测量、呼吸测量等工作。
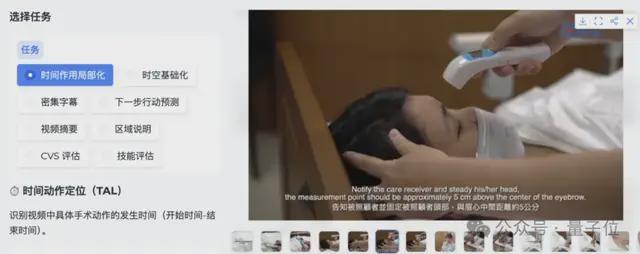
现在,我们随机考察8个任务中的一个,比如「时间动作定位」。
输入问题:脉搏测量动作发生在什么时间?
标准答案是:46.0-61.8seconds。
模型给出的预测是:43.0-65.0seconds。前后误差不超过4秒,且正确答案就在预测范围内。
为什么手术视频是AI最难啃的骨头?
在AI医疗领域,将AI用于影像辅助诊断、病历书写、质控管理等场景早已不是新鲜事,在不少医院已经落地。
但有一个方向,至今仍是公认的“无人区”,那就是手术视频理解。
之前没人敢碰,为啥?三重地狱级难度,和静态影像完全不是一个量级:
第一关:数据极难获取。临床手术视频涉及患者隐私与医学伦理,获取本身就困难重重。
即便拿到了原始视频,你让专业医生逐帧标注?成本高到可以劝退99%的团队。
第二关:没有统一评测标准。这是行业里一个很尴尬的现实:各家用自己的数据集、自己的指标,模型效果根本没法横向比较。
你说你强,他说他强,谁说了都不算,严重阻碍整个赛道的发展。

第三关:任务本身极端复杂。手术视频的难就难在对空间、时序、语义的理解要高度专业。
比如,它需要精准识别毫米级的器械位置和解剖结构。稍微偏一点,可能就认错了。
而且胆囊得先分离再切除,不能反过来。AI如果看不懂时序,就根本无法理解手术进程。
各种约束叠加,再顶级的模型也只能歇菜。
但现在,这个无人区被uAI Nexus MedVLM一脚踩穿。
它不只是“炫技”,是真的能救命。
好了,说点实际的。这模型具体能干嘛?
术前:分析主刀老师上万台手术视频,挖掘临床规律、辅助优化方案。
想象你是一位刚站上手术台的临床医生,即将做一台胆结石微创手术。
以前你只能靠记忆和经验;现在AI把成千上万台顶级专家的手术经验沉淀下来,相当于有了最强的大脑,来辅助你完成这台手术。
术中:在分离胆囊管、显露安全视野等关键步骤,实时给出指引;对违规操作、动作偏差进行毫秒级预警,成为你的“第三只眼”。
术后:自动完成总结与结构化记录,这通常会占用医生大量时间,但现在,一键生成标准化报告。这台手术的经验,也能成为下一位医生的“决策依据”。
手术质控、术中安全、报告自动化、医学教学……uAI Nexus MedVLM的价值,远不止于技术突破。
在中国,优质医疗资源集中在三甲医院,基层医院医生成长周期长、手术经验积累慢。
而uAI Nexus MedVLM可以把顶级专家的手术经验“沉淀”下来,基层医院的医生也能获得“专家级”的术中辅助。
这或许才是AI真正理解手术视频的意义所在。
全球开发者,新机遇来了
这次发布,最值得关注的不仅是uAI Nexus MedVLM本身。
开发这一模型的背后玩家联影智能(联影集团旗下一家专注于AI医疗的创新公司),首次向全球开源大规模高质量医疗视频标注数据和模型,并提供了一个更具可比性的评测基准。
这意味着什么?终于有了一个手术视频理解垂直领域的“全球公共测评体系”了。
以前,各家模型各说各话,效果没法比。
现在,拉出来在同一个数据集上跑一跑,谁强谁弱,一目了然。
而这,还只是开始。
这支研发团队不想唱独角戏,上线了医疗视频理解大模型榜单,面向全世界开发者发出挑战。
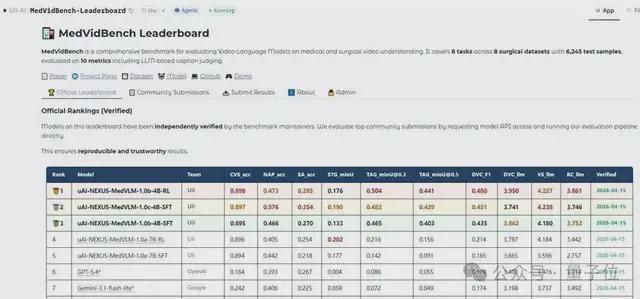
这是一个综合基准测试,用于评估视频语言模型在医疗和外科视频理解方面的表现。
开发者可提交自有模型结果,由系统基于标准自动评分,形成动态更新的统一排行榜。
当全球开发者都能下载模型、使用数据集、上传自己的成果时,看谁能把对医疗视频理解的能力边界,再往前推一步了。
这个过程中,医生上传的罕见病例、复杂手术视频,尤其是现有模型表现不足的案例,都会成为极为珍贵的真实数据,持续驱动技术迭代。
医疗视频AI正在迎来面向全球开发者的黄金时代。
未来,uAI Nexus MedVLM将与具身智能融合,完善感知-推理-执行的能力闭环。从手术室拓展到更多临床场景,推动医疗全流程智能化。
数据开放、模型共享、全球协同……这条路,才刚刚开始。
开发者们,是时候上车了~
彩蛋:链接在此,请自取
1.在线Demo:
https://huggingface.co/spaces/UII-AI/MedGRPO-Demo
2.推理代码:
https://github.com/UII-AI/MedGRPO-Code
3.MedVidBench数据集:
https://huggingface.co/datasets/UII-AI/MedVidBench
4.公开榜单:
https://huggingface.co/spaces/UII-AI/MedVidBench-Leaderboard
5.论文:
https://arxiv.org/abs/2512.06581
6. 项目介绍:
https://uii-ai.github.io/MedGRPO/