
一篇论文已被 ACL 2026 收录,主要作者来自上海交通大学自动化与感知学院 IWIN 中心团队。该团队的负责人是关新平教授,导师包括陈彩莲教授和乐心怡教授,南洋理工大学陶大程教授亦有参与合作。其他研究人员则分别来自腾讯、上海人工智能实验室以及香港中文大学等机构。论文的第一作者王骥泽为该校博士生,专注于大型模型智能体的研究。
在最近几年里,随着大语言模型的进步,从单一模型的性能提升逐渐转向多个模型之间的协作已是必然趋势。既然不同的模型各有优势,那么为何不利用这些优势来共同解决更加复杂的任务呢?
Mixture-of-Agents(MoA)概念就是在这样的背景下提出的,它通过并行生成、逐层交互和反复融合的方式,常常能够获得比单一模型更好的结果。然而,随之而来的挑战是性能提升的同时,成本和延迟也会迅速增加。
标准的 MoA 方法中,在每一回合通常都需要调用多个模型,并基于这些模型的结果进行筛选和融合决策。但是,哪些模型需要参与协作、哪些可以跳过并没有明确的标准,这导致随着模型数量和层次深度的增加,整体成本也随之上升。
由此,研究者开始探索让 MoA 变得更加稀疏的方法,例如 Sparse MoA 就会先由评审模型对所有生成的回答进行评分并筛选出一部分继续协作。虽然这种方法减轻了后续融合的压力,但仍然存在一个核心问题:为了确定哪些模型更优,系统仍需要预先调用所有模型。
因此,这篇论文的核心问题是:是否真的有必要让每个模型都先给出答案才能决定哪个更适合?

- 论文标题为《RouteMoA: 动态路由无需预推理提升混合智能体效率》
- 虽然这里没有提供具体的链接信息,但 RouteMoA 的核心思想是通过预测模型的能力来避免不必要的全量推理过程。
- 在现有的 MoA 方法中,一个共同的假设是必须先看到每个模型的输出才能判断哪个更好。无论是传统的 MoA 还是引入评审机制的 Sparse MoA,都不可避免地需要经历所有模型先行推理的过程。
第一,计算成本难以降低。即使最终只使用少数几个模型的结果,前期为所有模型付出的成本依然存在。
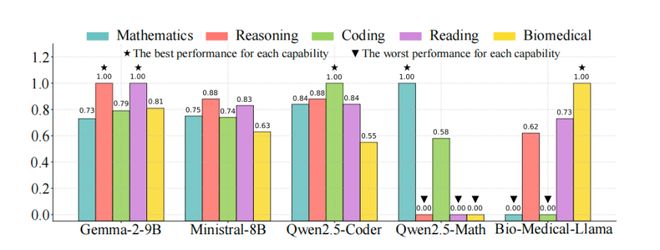
现有方法的问题:
第二,扩展至大型模型池时会遇到瓶颈。当模型数量增加时,全量预推理很快变得不可行甚至超出上下文限制。
这就意味着问题的核心不在如何选择正确的模型,而在于提前筛选成本过高。
这带来两个问题:
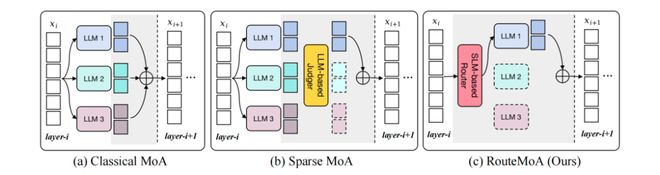
把“选模型”步骤前置到推理之前
RouteMoA 的创新之处在于将原先的后验判断转变为先验预测和轻量修正相结合的方法。
具体来说,整个过程可以分为三个阶段:
RouteMoA:
一、基于用户查询做出初步筛选:不需要进行实际推理就能评估每个模型的表现潜力,并缩小候选池。
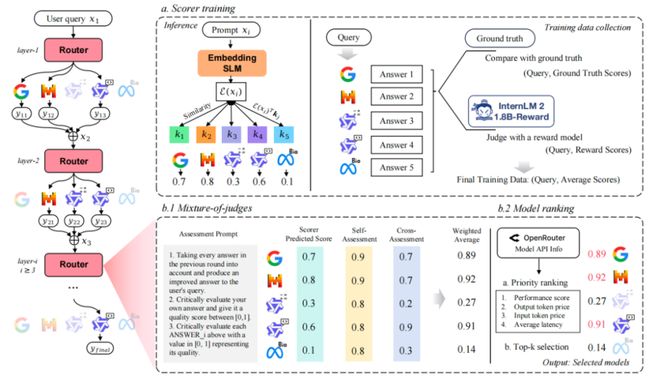
二、利用已有输出进行低成本校正:通过混合评审机制(包括自评和互评)来提高准确性,仅依靠已生成的输出信息进行调整。
三、综合考虑性能、成本与延迟优化选择策略,在实际应用中实现更优的工程决策。
少花九成的钱却效果更好
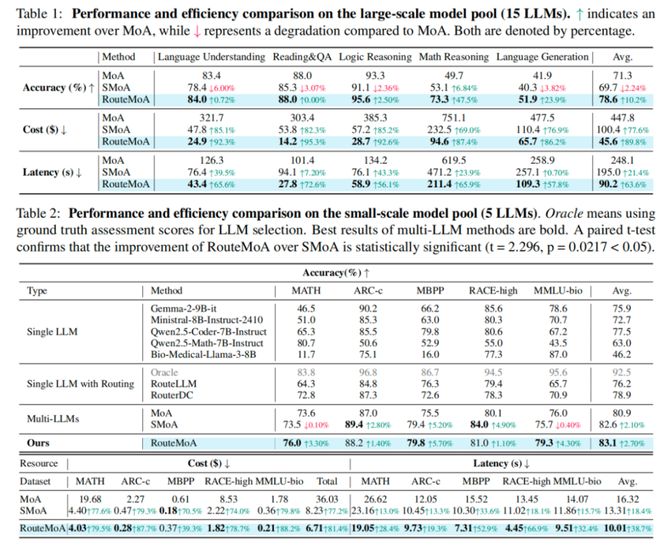
在包含十五个模型的大规模实验中,RouteMoA 显示出了明显的优点。
不仅整体准确率有所提升,还表明减少无效计算不仅能保持性能,反而能使得系统更加高效。
多模型协作本质上是稀疏的
- 论文指出,在大多数情况下,真正关键的只是少数几个模型。只要前期筛选得当,后续的合作就能放大正确的答案。
- 实验数据显示,scorer 能在前三个选择中以近 98% 的概率找到正确模型。
失败往往来自融合阶段
在失败案例分析中发现:
约有五成的错误源于最终答案整合时的问题。
- 输出质量
- token 成本
- 推理延迟
而由于选择不当导致的比例要低得多,说明多模型协作的关键挑战已经从“选谁”转向了“如何更好地融合”。
实验结果:
总结:调度在多模型时代至关重要
RouteMoA 的意义不仅在于提供了一种更高效的 MoA 变体,还提出了一种新的范式。
- 成本降低 89.8%
- 延迟降低 63.6%
- 即不再假设所有模型都需要参与协作,而是通过动态调度来优化性能和成本。
这说明一件事:减少无效计算,不仅不会伤害性能,反而会让系统更专注于对的模型。
一个关键洞察:
多模型系统的本质是稀疏的
论文中一个非常重要的观察是:在绝大多数 query 上,真正关键的模型只占少数。只要初始阶段能把这些模型保留下来,后续协作就足以放大正确答案。实验中,scorer 在 Top-3 内命中正确模型的概率接近 98%,这意味着:系统并不需要看所有答案,只需要别漏掉对的模型。
进一步分析:
失败不在选错模型,而在融合阶段

一个很有意思的发现是,在失败案例中:
- 超过 50% 的错误来自最终答案融合(aggregation drift)
- 而真正因为选错模型的比例要低得多
可见,多模型系统的瓶颈正在发生转移:从 “选谁来回答”,转向 “如何整合多个答案”。
总结:多模型时代,调度很重要
RouteMoA 的意义,并不只是一个更高效的 MoA 变体,而是提供了一种新的范式:
- 不再默认所有模型都要参与
- 而是先判断谁值得参与
- 再用协作机制校正和放大正确答案
换句话说,随着多模型协作的兴起,系统层的调度与协同,正变得与模型能力同样重要。