五家领先的国产大模型企业在2026年选择了哪些最佳的发展路径?
自今年年初以来,这些企业动作频繁且变化多端,连行业内部人士都感到难以捉摸。
据悉,一向不愿讨论上市和融资问题的DeepSeek已开始接触外部资本;智谱新Coding模型口碑迅速上升;MiniMax和智谱在上市后市值分别飙升至4000亿及3000亿港元;阿里巴巴也进行了一系列重大组织重组。这些现象背后的原因是什么?
一位资深业内人士向数智前线透露,理解这一复杂局面的一个方法是建立一个坐标系:主要国产大模型的战略重心可以用国内与国外、B端与C端这两个维度交叉划分。
在这个坐标体系中,2025年全球大模型市场已经形成了三条最赚钱的路径:以OpenAI为代表的一般助手路线在消费者层面实现了规模化;Anthropic Claude代表的代码和智能体路线在市场上爆发,成为最具商业价值的方向之一;视频生成作为Token消耗的最大用户,在商业化方面取得了高速进展。
国产大模型企业如何在这张图中选择自己的赛道?数智前线对此进行了详细分析。
DeepSeek:资金困境还是人才挑战?
据报道,一向财务充裕的DeepSeek现在正寻求外部融资。The Information指出,该公司正在与潜在投资者接触,并计划至少筹集3亿美元的资金,估值不低于100亿美元。业界普遍认为,一旦启动这一进程,其估值将不会低于MiniMax和智谱。
业内消息人士称,由于缺乏上市计划或外部融资机会,DeepSeek的核心团队在过去一段时间内面临了竞争对手的挖角挑战。例如,R1核心模型的主要作者之一郭达雅最近加入了字节跳动Seed团队,而之前为V3模型做出重要贡献的研究员罗福莉则转投小米。这表明该公司在激励机制方面存在结构性问题。
与此同时,公司对外界交流的限制和商业化的战略不足可能也让年轻研究人员感到担忧。解决这些问题可能是DeepSeek首席执行官梁文锋接下来需要考虑的重要议题之一。
在产品层面,尽管过去一年中DeepSeek没有发布重大版本更新,但有业内观察者认为其技术迭代速度并不慢:例如,在2月份将上下文窗口扩展至100万个Token;3月的服务中断可能是因为正在进行的升级所致;4月初灰度上线的新功能也得到了内部应用的认可。此外,该公司还坚持闭源API调用模式。
长期来看,阿里巴巴设定了在未来五年内实现云与人工智能商业化收入突破千亿美元的目标,这意味着他们需要维持超过年均复合增长率的水平来将前期的大规模研发投入转化为可持续性的营收增长,并解决过去“叫好不叫座”的问题。
另外,腾讯也在积极引进年轻人才并给予高度自主权以开发新的模型;华为盘古经历了内部职能重组,大模型研发部门被整合进2012实验室和终端业务线;百度则在推进昆仑芯项目及智能体应用方面加大了力度。这些企业的最新动态值得关注。
此外,在价格策略上,火山引擎采取了一种新的“控价保利”措施——收紧优惠、暂停首次购买特惠等,以提高变现效率。
除了阿里和字节之外,其他公司如腾讯也引入了年轻的人工智能研究专家,并计划发布新模型;华为云则提出了“行业AI梦工厂”的概念,专注于特定垂直领域的发展;百度的重心在推进昆仑芯片项目以及智能体应用。这些动向表明国内大型科技公司在人工智能领域的竞争日益激烈。
腾讯引入了年轻的人工智能研究专家,并计划发布新模型;华为云则提出了“行业AI梦工厂”的概念,专注于特定垂直领域的发展;百度的重心在推进昆仑芯片项目以及智能体应用。这些动向表明国内大型科技公司在人工智能领域的竞争日益激烈。
华为盘古经历了一轮内部职能重组,大模型研发部门被拆分到2012实验室和终端业务线,并提出了“行业AI梦工厂”战略,专注于具身智能、智能制造等特定领域。然而,如何平衡快速创新与流程制度之间的关系是一个挑战。
百度近期的行动集中在昆仑芯片的推进上以及以“龙虾”为代表的智能体应用方面,但其新模型仍处于研发阶段,尚未公布具体发布日期。这些公司的未来走向将是业内关注的重点之一。
而从目前MiniMax在企业级市场的拓展来看,一个是视频生成,布局路径与字节旗下产品有所类似。例如与芒果TV合作文化出海,通过音视频融合技术让出海热剧不仅“讲外语”,口型也能对得上;与优酷合作,上线纯AI短剧;在央视节目中,利用视频模型“海螺”为歌手生成AI的动态背景。
另一业务是ARC(Agent、Reasoning、Coding),其为国产大模型带来了新的ToB商业模式——从之前定制化的重资产模式,走向轻量级标准化API调用。这为国产大模型企业开拓ToB市场带来有利条件。MiniMax M2.5在开发者聚合平台OpenRouter的模型输出价格,是Claude Opus 4.6的1/20左右,定价策略反映其积极布局姿态。据OpenRouter数据,MiniMax有两款模型调用量位居前五。
而随着业务量攀升,单纯依赖公有云已面临性价比和效率瓶颈,难以针对自身模型灵活调整训推框架。为此,MiniMax也在投入线下数据中心建设,部分转向自研训练和推理框架的AI Infra。
智谱:从什么都做到专注代码
今年开年以来,智谱在Coding模型上的声势突然升温。GLM-5.1发布后,配套的Coding Plan订阅一度“瞬间断货”,每天定时抢购,大量用户抢购不上,需求明显大于供给。然而,在OpenRouter上,智谱GLM-5系列定价在3到4美元/百万Token,高于多数国产模型,其OpenRouter调用量已不在前十之列。一系列现象让很多行业人士表示“搞不清楚”。
接近智谱的资深人士告诉数智前线,这是智谱的渠道策略,OpenRouter作为补充渠道,核心流量导向自家平台。从财务数据来看,Coding相关收入增速较高,产品口碑被认为已反超国内几家大厂。但几家头部国产Coding模型与全球领先的Claude仍有较大差距。
智谱能在Coding上突破,有多重因素叠加:其一,智谱是国内最早布局大模型和Coding模型的企业之一,核心实验室团队规模达两百多人,人才密度较高。其二,2025年DeepSeek爆火后,国内多家公司反思基础模型研发的重要性,智谱也加大了基础模型投入。其三,战略层面主动收缩。此前智谱内部对标OpenAI,广泛布局各类模型,业务分散,去年起逐步聚焦,将资源集中于代码方向,转而以“中国版Anthropic”的B端服务叙事。
在其去年发表的论文中,有业内人士发现其重点探讨了ARC(Agent、Reasoning、Coding)。技术节点上,GLM-4.7于2025年12月发布,在编程与推理上实现跃升,是其口碑开始上升的重要节点。
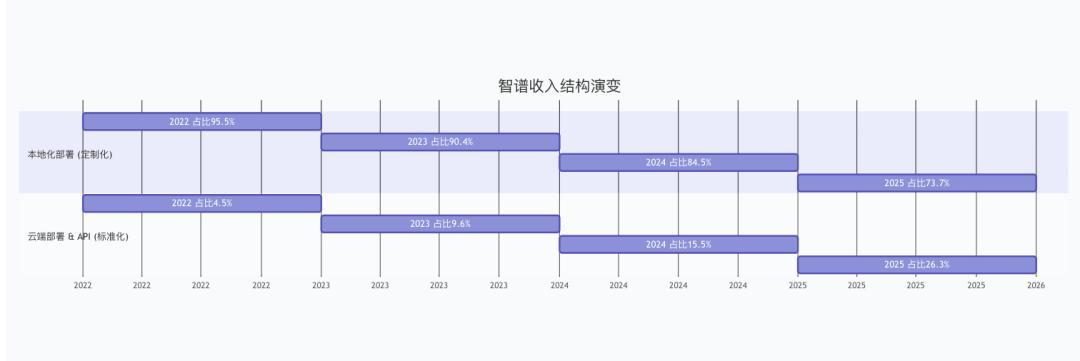
商业化层面,智谱此前企业级收入高度依赖项目定制开发,本地化部署占2025年营收的73.7%(约5.34亿元)。但数智前线获悉,唐杰教授团队对MaaS平台长期价值比较坚定,虽然这一模式在国内市场此前推进并不顺畅。Coding需求爆发成为转折点,标准化API订阅快速放量,为MaaS路径打通了商业闭环,也为智谱等国内模型企业提供了更具说服力的增长叙事。目前智谱定制化业务维持现金流,API订阅作为第二增长曲线开拓。
值得关注的是,需求快速增长也对智谱基础设施提出挑战,宕机与响应变慢的问题时有发生,算力扩容与运维能力仍是待补的短板。
字节:"控价保利"押注两大高Token场景
今年开年,字节在AI商业化核心叙事,仍高度集中于Token消耗规模。4月于武汉举办的火山引擎开年巡展上,字节公布截至2026年3月,豆包大模型日均Token使用量突破120万亿,这一全口径数据涵盖豆包App、火山引擎API、字节系产品内嵌AI及企业客户调用的全部消耗量。(可参考去年发布的文章豆包凶猛,深度解析字节AI战略)
在模型方面,字节将模型支撑重心明确指向两大高Token消耗场景:视频创作与智能体应用。其中在视频方向上,春节前发布的Seedance 2.0是关键节点。此前受制于20%~30%的“抽卡率”,AI短剧与漫剧难以实现全自动化投产。字节内部人士曾告诉数智前线,“抽卡率跨过50%,才能产生显著商业价值”。Seedance 2.0发布后,抽卡率有明显改善,具备突破这一商业化门槛的可能。
Seedance 2.0在企业级市场开放经历了一段合规准备期——初期以嵌入即梦、豆包等自有C端产品的形式对外提供服务,待版权IP等保护机制逐步完善后,火山引擎于4月2日开放API公测,并于4月14日全面上线。
智能体方向,字节也将OpenClaw类应用列为重点押注场景。火山引擎CEO谭待介绍,目前国内该类产品用户盘仍在百万量级,但面向中国职场人群的庞大基数,规模化增长空间较大。值得关注的是,在龙虾应用中,字节仍优先推荐自家大模型,被业界解读为在基础模型层构建核心壁垒的长线布局。
大厂能否在AI时代真正拿到竞争“船票”,必须具备较强的模型。业界观察到,字节在大模型上并未操之过急,未采用蒸馏手段,依然在做原创和基础性研究。一个例子是DeepSeek的mHC论文,即在字节2024年提出的HC(超连接)技术基础上完成关键优化。但业界也认为,包括字节在内的国内大厂目前在ARC(Agent、Reasoning、Coding)方向上的投入仍不足。
从模型调用来看,据媒体报道,字节旗下云业务火山引擎2026年MaaS业务收入目标已从2025年的20亿元量级,大幅上调至百亿元规模,大模型及相关AI工具销售成为销售端核心考核指标。为在生态层面占据主导,火山引擎近期宣布赞助支持OpenClaw官方技能商店ClawHub的中国镜像搭建,意在借助这一全球热门平台争夺开发者心智。
定价策略上,字节出现转向。过去两年,火山引擎在春季持续推出API调用降价,以价换量扩大市场份额。今年,在多家大厂相继宣布涨价的背景下,火山引擎转向“控价保利”——收紧优惠、暂停首购特惠、取消部分补贴等,Seedance 2.0价格也高于前代。这一转变意味着,模型带来的价值更高,变现效率的优先级也正在提升。
阿里:组织策略调整破解“叫好不叫座”局面
今年开年以来,阿里围绕AI展开了一次大规模组织重构。3月16日,集团宣布成立ATH组织(Alibaba Technology Holdings),由CEO吴泳铭挂帅,将通义实验室、MaaS业务线、C端千问事业部、B端悟空事业部及AI创新事业部整合于一体,目标指向“创造Token、输送Token、应用Token”。
外界认为此次调整最具信号意义的是,通义实验室从阿里云下属研究部门升格为与电商、云并列的独立事业部,MaaS也从云业务中独立拆分——过去AI能力附属于云计算体系,此番战略调整将AI升级为集团层面的核心。同时,阿里设立“集团技术委员会”,将AI决策权与资源调配提升至集团最高层。数智前线了解到,自去年下半年起,阿里已着手围绕AI整合内部分散条线,核心命题是商业模式从“算力即服务”向“Token即服务”的转型。
模型层面,今年3月底至4月初短短四天内,阿里接连发布三款模型,并优先接入悟空、Qoder、千问App等内部生态,以内部消耗的方式验证模型商业价值。
闭源API调用的业务边界扩大,业内看法不一:有担忧开源路线收缩;有认为纯开源难以直接转化为商业收益,阿里转向分层次开闭源是变现逻辑下的现实选择;也有资深人士指出,开源本质上是追赶者的竞争策略,对全球头部模型公司而言从未是核心战略重心,Anthropic未官宣开源,OpenAI与谷歌虽有过开源,但均为内部小团队行为,且不具持续性。
在更长周期的目标上,阿里制定了未来五年云与AI商业化年收入突破1000亿美元的目标,对应需维持47%以上的年均复合增长率。这一数字意味着,如何将前期大规模研发投入,转化为可持续的规模化营收,破解此前“叫好不叫座”的局面。
此外,腾讯方面,去年将年轻研究员姚顺雨引入并赋予高度自主权,主导自研模型,业界在等待其新模型发布;同时,腾讯在AI基础设施上也需要追赶其他几家大厂。
华为盘古经历了一轮内部职能重组,大模型研发一部分划入2012实验室,另一部分并入终端业务线,华为云同时提出“行业AI梦工厂”,布局具身智能、智能制造等垂直领域。业界也提到,大模型与华为此前的业务类型,一种靠快速迭代创新,一种靠流程制度保障极致可靠安全,如何平衡让年轻人的AI人才发挥价值需要探索。
百度方面,近期动作集中在昆仑芯推进以及”龙虾“为代表的智能体应用上,新模型仍处于研发阶段,尚未明确发布节点。这几家大模型企业的动向值得进一步跟踪观察。