 本文由一位专业的新闻编辑整理而成。
本文由一位专业的新闻编辑整理而成。
当前,具身智能技术的发展遇到了一个明显的瓶颈:缺乏大规模的真实世界数据和经验积累。
近年来,随着VLA等大型模型的出现,机器人在预训练阶段取得了显著的进步。然而,当它们进入实际应用场景时,问题便显现出来——由于物理世界的复杂性和多变性,机器人的性能难以持续改进,并且仍然高度依赖于人工标注的数据和重复的学习过程。
这表明,具身智能还未达到“大规模增长”的关键阶段。
实验室数据或模拟环境中的训练成果不足以推动机器人能力的持续进化。真正的突破需要来自真实世界的高质量交互数据积累。然而,如何获取这些数据仍然是一个挑战。
目前,大量的训练数据仍主要依靠人工示教和远程操作来采集,这种方式规模有限、成本高昂,并且难以覆盖开放环境中复杂的边缘场景。
要想让机器人的数据积累真正实现“滚动增长”,唯一可行的方法就是将机器人从实验室中解放出来,在真实世界中长期运行并持续反馈经验。
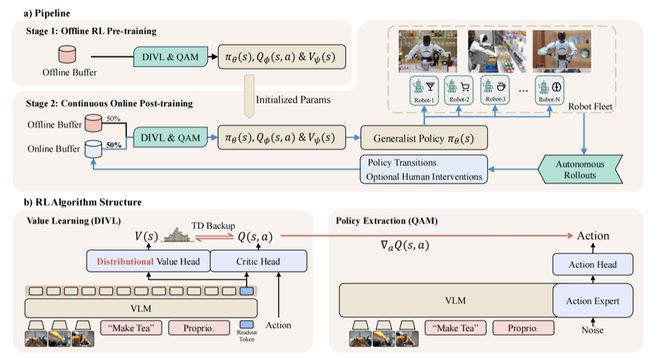
在这样的背景下,上海创智学院和智元具身研究中心联合发布了一项重要成果——罗剑岚团队开发的LWD(Learning While Deploying)大规模强化学习训练系统。该研究由创智学院导师、智元首席科学家罗剑岚及其团队完成。
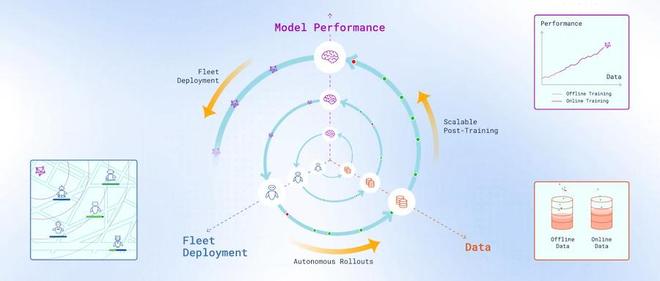
这一项目不仅仅关注单一算法的进步,而是提出了一种更具实用性的解决方案——通过在实际环境中运行机器人并收集其行为数据来不断更新模型,让每台机器人都能在执行任务的同时也成为学习的源泉。
一、推动数据飞轮自主运转
在传统的模仿学习框架中,那些非完美的操作轨迹通常被当作无用的数据直接丢弃,导致机器人只能机械地复制人类的成功案例。
LWD的核心优势在于它建立了一个由真实世界强化学习驱动的闭环反馈系统。
该系统允许机器人集群在执行任务时自主积累异构交互经验,并将这些数据统一传送到云端共享重放缓冲区,无论成功还是失败的数据都被视为宝贵的资源。
这种方式使得即使是传统意义上被视为“错误”的信息也能被转化为改进模型性能的宝贵资料。
随着机器人集群规模扩大和运行时间的增长,“数据飞轮”将不断加速转动,从而实现持续更新与提升。
二、强化学习算法深入进化:在嘈杂的数据中精准定位进步信号
在大规模真实环境中部署机器人群体给传统的强化学习带来了极大的挑战。
各种机器人产生的数据复杂多样且缺乏统一性,这使得从这些庞大的异质数据集中有效提取有用的信息变得极其困难。
为了解决这个问题,LWD引入了一种创新的分布隐式价值学习(DIVL)算法。
按照传统的做法,机器人表现的评估方式是固定的分数系统。但在复杂环境中这种方式往往不准确;而DIVL则让机器能够理解行为成功的概率区间,从而更精准地判断哪些操作风险较高、哪些值得尝试。
这种改进使得机器人在很少得到明确奖励的情况下也能做出正确的决策,极大地提高了评估的准确性。
同时,针对VLA模型的特点,LWD结合了Q-learning with Adjoint Matching(QAM)技术,显著提升了大规模部署中的学习效率。
这种方法让复杂的策略更新变得更高效且易于管理。

三、打造全能策略:挑战长程复杂任务的极限
研究团队在智元G1双臂机器人集群上进行了大规模的真实世界部署测试,以验证这套训练框架的实际效果。
测试包括八项具有高度挑战性的多模态操作任务,如超市货架动态补货、调酒等长程连续动作任务。

▲展示任务的示意图(A)调制鸡尾酒;(B)冲泡功夫茶;(C)制作果汁;(D)装鞋入盒;(E)商超补货。
在这些持续时间长达5到8分钟、包含多个复杂物理交互的任务中,LWD展示了显著的优势。
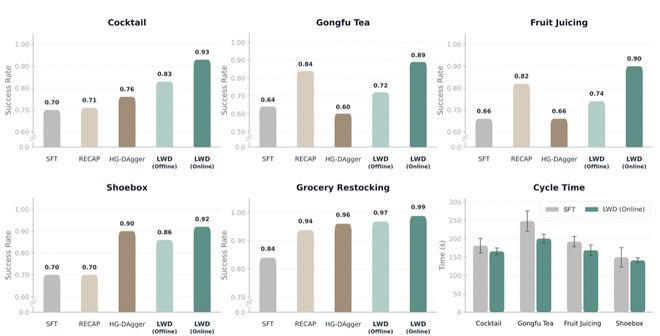
▲各种任务的成功率
测试结果显示,在积累了大量在线真实经验后,LWD训练出的单一通用策略在所有测试中的平均成功率达到了惊人的0.95,远超传统的行为克隆(0.76)和先进的离线强化学习基线如RECAP(0.86)及Dagger-SOP(0.82)。

▲八项实际操作任务的结果。LWD(在线)达到了最高的总体平均分,并在四个长程任务中全部获得最高成绩,在商超补货任务中的表现也非常出色。

▲调制鸡尾酒
特别是在那些考验长期效果和错误恢复能力的复杂连续任务中,LWD表现出显著的进步,证明了基于真实世界经验的学习能够有效突破操作难度的限制。
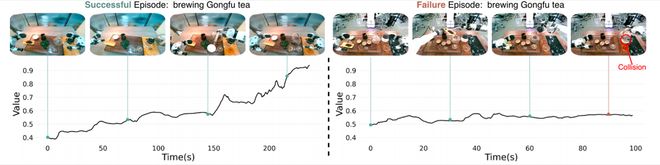
▲功夫茶任务中一次成功执行(左)和一次失败执行(右)的价值曲线。结果表明学习到的价值可以有效地反映任务完成情况。
总结:将部署视为能力提升的新起点,助力机器人在真实世界持续进化
LWD不仅推动了算法框架的进步,更重要的是改变了机器人的迭代方式。
以往业界普遍认为“部署”是模型训练的终点,而LWD则证明了自主改进应当成为通用策略的标准属性。
学习不应仅限于出厂前阶段,而应该是在实际环境中持续进行的过程。
只有赋予机器人从现实世界中自我进化的能力,它们才能真正突破人工数据的限制,在各种复杂开放场景下实现商业价值。
