
从 DeepSeek-R1 到 Kimi K2.5,利用强化学习(RL)来优化大型模型的推理性能已成为关键方法。
然而,在 RL 后训练过程中存在一个重要问题:这种训练方式是否遵循特定规律?能否通过给定参数量、计算资源和数据规模,准确预测出 RL 训练所能达到的效果?
中国科学技术大学与上海人工智能实验室等机构的研究团队对此进行了系统性的研究。他们使用 Qwen2.5 系列密集模型(从0.5B到72B)开展了广泛的 RL 实验,并在 Llama 3 系列(1B至70B)上完成了跨架构验证,首次全面揭示了大模型在强化学习后训练阶段的数学推理能力扩展行为。
目前这项工作已被 ACL 2026 主会议接收。

- 论文地址:https://arxiv.org/abs/2509.25300
- 代码链接:https://github.com/tanzelin430/Mathematical-Reasoning-RL-Scaling-Law
- 数据集:https://huggingface.co/datasets/Artemis0430/GURU-MATH-CL
预训练有其Scaling Law,那么RL后的训练呢?
Scaling Law 的概念已经广为人知。早在2020年,OpenAI 就揭示了预训练阶段的规模法则,并证明模型性能随参数量、数据量和计算量的增长呈现可预测的幂律关系。
然而,在从预训练或监督微调转向强化学习后训练时,这些规律不再直接适用。RL 的核心在于通过策略优化最大化奖励,这与最小化 next-token prediction 交叉熵损失的目标大相径庭。
这意味着,要理解 RL 后训练的 Scaling 行为,需要重新建立一套基于实验的规则体系。
研究团队选择数学推理作为研究平台,因为这种任务具有天然的答案验证性,能提供精确的奖励信号。在此基础上,他们针对计算资源受限、数据量有限和重复使用数据三种典型场景进行了大规模受控实验。
实验设计与评测框架
为了确保结论的可靠性,研究人员在实验设计上采取了严格的控制措施。
在模型选择方面,主实验覆盖了 Qwen2.5 全系列密集模型(从0.5B到72B),所有模型具有相同的架构,以确保规模是唯一变量。
此外,为了保证 Scaling Law 的普遍性,研究人员还在 Llama 3 系列上进行了跨架构验证。训练采用统一的 VeRL 分布式 RL 平台和 GRPO 算法,并在每个配置下重复实验三次,以确保统计可靠性。
训练数据来源于 guru-RL-92k 数据集中的数学子集(约5.4万道题),按难度递增顺序进行课程学习。
在评测方面,研究团队定义了测试损失 L = 1 - Pass@1 作为主要指标,并使用3000道跨领域基准题目和500道保持原始难度分布的数学题来进行内部和跨域评估。
基于上述实验框架,该研究得出了三个重要结论。
核心发现
发现之一:具有预测能力的 Scaling Law
研究的核心发现是一个简洁且有效的 scaling 公式。测试损失 L 与训练资源 X(计算量 C 或数据量 D)之间存在对数线性关系:
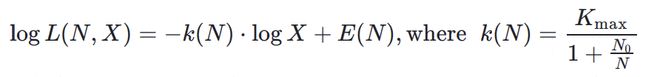
模型在强化学习后训练阶段的学习效率 k (N) 随参数量 N 单调递增。
实验显示,该 Scaling 公式不仅能精确拟合已有数据(R² > 0.99),还具备实际预测能力。
- 跨模型外推:利用较小规模模型的数据来预测更大规模模型的训练过程。通过拟合公式参数后直接预测72B 模型的学习效率等关键指标,与实际表现高度一致。
这意味着研究人员可以通过小模型实验准确预测大模型的行为,从而大大减少试错成本。
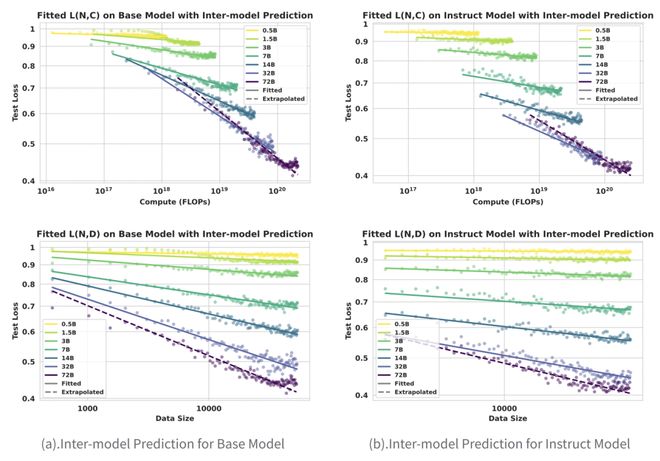
图 (1).Scaling Law 的拟合与跨模型外推能力
- 训练轨迹预测:仅需使用训练早期的数据点便可准确外推整个数据集上的最终收敛性能。
无需等待全程训练结束便能大致预判模型的收敛走向,并为资源分配和提前停止决策提供直接依据,从而有效降低不必要的算力消耗。
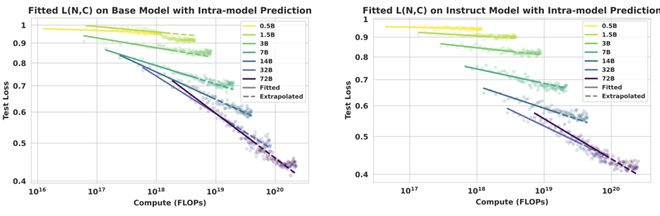
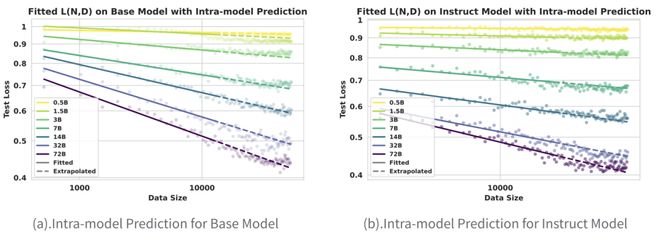
图 (2).Scaling Law 的拟合与模型内轨迹预测能力
此外,该公式在计算量(C)和数据量(D)两个维度上具有统一的形式,这进一步增强了其可靠性和适用性。
发现之二:学习效率的饱和趋势
为了更精确地研究 Scaling Law,研究团队对强化学习效率 k (N) 进行了大量实证分析。
研究发现更大的模型确实可以更快地学习。从0.5B到72B,学习效率系数k(N)持续增加,但这种增长并非线性而是逐渐趋于饱和。
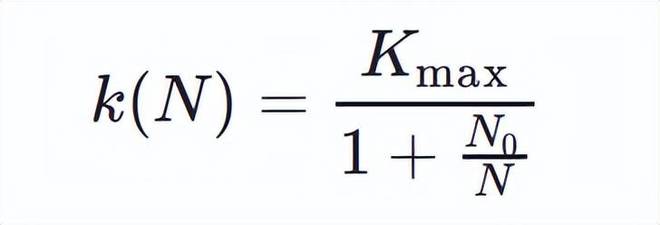

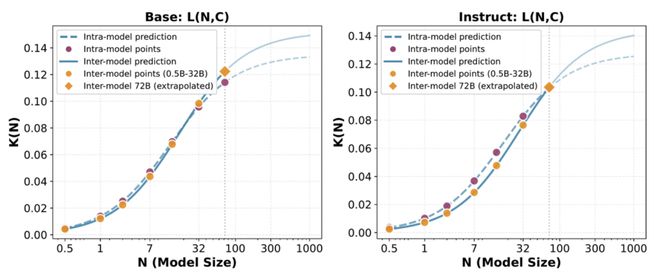
图 (3). 强化学习后训练的学习效率随模型参数量的变化趋势
这种现象在实验中表现为一个有趣的“性能交叉”现象,在等量计算预算下,较小的模型可能表现更优。这揭示了一个关键的隐性权衡:盲目堆砌大型模型未必是最优策略,在有限预算内找到最优规模和训练步数的平衡点更为明智。
研究团队认为该现象揭示了一个关键的隐性权衡,即在计算受限的场景下,盲目堆大模型未必是最优策略。在有限预算内,找到模型规模和训练步数之间的平衡点,可能比简单地选择最大模型更为明智。这一发现为 RL 后训练的资源分配提供了重要的定量依据。
发现之三:数据重用的有效性
除了探究 Scaling Law,研究团队还探讨了重复使用相同数据进行强化学习的效果。他们发现适度的数据重用是一种低成本、高效率的方法,在高质量推理数据有限的情况下,反复利用现有高质量数据可以达到接近等效的训练效果。

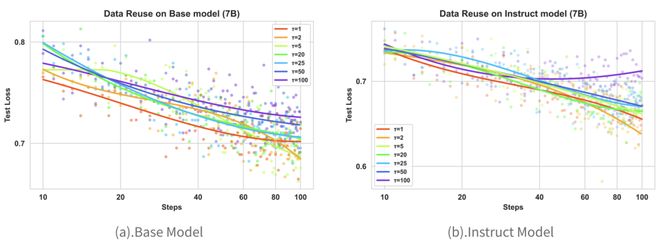
图 (4). 数据重用对强化学习训练轨迹的影响

这一策略不仅成本低廉且能够保持训练轨迹的一致性。
跨架构验证
上述发现均基于 Qwen2.5 系列。一个重要的问题是:这些 scaling 行为是特定于此模型系列,还是适用于所有采用 RL 后训练的体系?
为此,在 Llama 3 模型家族上进行了完整的重复实验。
实验结果表明,统一的幂律公式在 Llama 上同样成立,并且拟合效果良好(R² > 0.99)。尽管 Llama 的绝对性能低于 Qwen,但其 scaling 关系和学习效率饱和趋势完全一致。
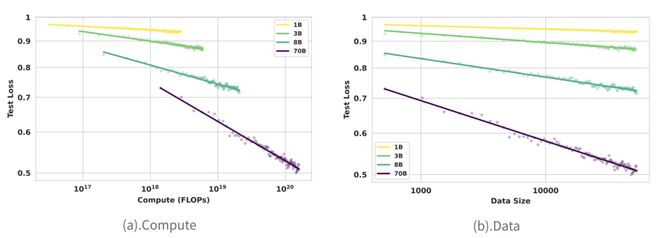
图 (5).Scaling Law 在 Llama 系列模型上的拟合效果
这一跨架构验证证明了所揭示的 Scaling Law 描述的是 RL 后训练过程本身的内在规律,而不是特定模型架构的特点。无论底层架构如何,只要遵循相同的 RL 后训练范式,性能的 scaling 行为都会呈现一致的数学描述。
总结
该工作通过对 Qwen2.5 和 Llama 3 两个系列上所有参数量级模型进行实证分析,建立了一套系统性的 RL 后训练 Scaling 理论框架,并提供了可预测强化学习训练轨迹的数学公式(Scaling Law)。
对于利用 RL 提升大型模型推理性能的研究者和工程师来说,这项研究提供了一个量化、预测且具有指导意义的分析框架。而效率饱和这一发现则提醒我们:规模扩展是强有力的手段,但不是万能的;理解 scaling 的边界才能更聪明地 scale。
作者介绍
本文由中国科学技术大学与上海人工智能实验室、牛津大学等多家机构合作完成。主要作者为上海人工智能实验室联培博士谭泽霖及牛津大学研究员耿鹤嘉等人。其中论文第一作者谭泽霖是中科大与上海人工智能实验室联合培养的博士生,研究方向主要涉及智能体强化学习和机器学习系统。导师为白磊研究员,该文章由上海人工智能实验室青年研究员张晨、牛津大学博后尹榛菲博士共同指导。