
在自动驾驶车辆的日常测试视频中,我们经常能够观察到这样的场景:
一辆无人驾驶汽车驶入一个幽暗且封闭的地下车库内,在这里GPS信号几乎完全失效,只能依赖激光雷达扫描周围环境来确定自身位置。然而,由于周围只有冰冷的墙壁和立柱,车辆可能会在原地转了几圈后仍然不清楚自己的方位。
激光雷达重定位技术正致力于解决这一问题:即仅通过一帧点云数据,就能精确估算出无人驾驶汽车在全球坐标系中的六个自由度的姿态信息。
当前的主流方法依赖于“检索-配准”框架,可以达到分米级精度,但随着场景规模增大存储和计算需求也会显著增加;而采用神经网络直接预测位姿的方法(如APR和SCR)虽然能实现十毫秒级别的快速响应,但在处理角度变化时存在明显的局限性。这似乎表明,在精度与效率之间难以兼顾。
然而,“我全都要!”这句话或许不再只是梦想。厦门大学和布里斯托大学的研究团队提出了名为LEADER的激光雷达重定位方法,不仅能够实现十毫秒级的快速定位,而且在精度上超越了传统的“检索-配准”技术。
这项研究成果已被CVPR 2026会议接收为亮点论文,并计划全面开源代码和模型。

- 论文标题:《LEADER: Learning Reliable Local-to-Global Correspondences for LiDAR Relocalization》
- 目前,场景坐标回归(SCR)方法在预测位姿时无需显式存储地图信息,而是利用神经网络直接预测每个点的世界坐标,并通过类似RANSAC的方法来估计当前姿态。这种方法在稳定性方面通常优于绝对位置回归(APR)技术。
- 与传统的“检索-配准”模式相比,SCR方法能够显著减少存储开销和计算延迟,但长期以来其精度只能维持在米级到亚米级别,这在很大程度上限制了其应用范围。因此,研究人员提出一个问题:
SCR 方法真的无法达到传统“检索-配准”技术的精度水平吗?
为了突破这一瓶颈,论文作者深入探究了影响SCR方法精度的因素。
首先,旋转敏感性问题:车辆转弯时会导致定位精度大幅下降;其次,在高度相似的环境中(例如长直走廊),准确识别点云数据变得极为困难。
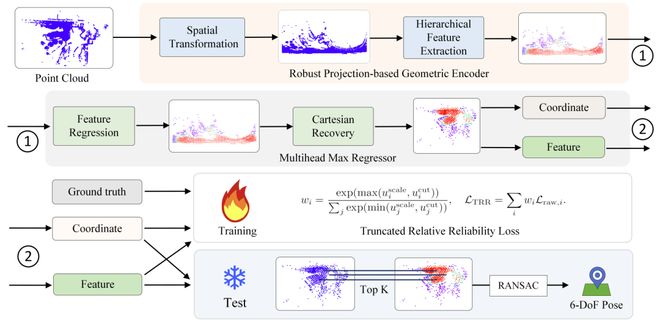
为此,LEADER框架被提出,它采用一系列低开销组件来解决这些问题:
柱面投影和循环稀疏卷积:通过将点云进行柱面投影处理,并结合循环稀疏卷积技术,解决了偏航角变化带来的特征不一致问题。此外,还利用地面检测算法校正了点云数据的水平位置。
TRR损失函数设计:每个点的质量不同,模型在训练时会自动识别出哪些点难以预测并赋予较低置信度,从而降低其对整体精度的影响。
- 在NCLT数据集上进行实验后发现,在不牺牲效率的前提下,LEADER方法将定位精度从APR的1.19米和SCR的1.51米提升至0.31米:
- 这一结果表明了TRR损失函数的有效性。为了进一步验证其效果,研究团队还与具有旋转鲁棒性的“检索-配准”方法RING/RING++进行了比较。
实验结果显示,在x-y平面上的定位精度方面,LEADER达到平均0.28米的成绩,远超RING/RING++;同时在5米内的失败率仅占0.28%,远远低于后者的失败率。
让模型学会取舍
让坏点 “靠边站”
在NCLT数据集上,尽管旋转问题并不突出,LEADER依然表现出色。通过对测试集中所有点按置信度排序,并分析其与预测误差之间的关系:
结果显示两者存在明显的负相关性,说明在实际应用中引入置信度信息能够显著提高模型的准确性。
为了进一步验证TRR损失函数的效果,研究团队还将其与其他常规损失方法进行了对比实验:
实验表明,采用TRR损失不仅能够让模型自适应调整每个点的重要性权重,而且可以将预测出的高精度点的比例翻倍。
这一发现启示我们,在不需要完整记忆所有内容的情况下,与其让模型死记硬背难以学习的数据,不如引导其学会取舍。因为一旦参数确定后,模型的记忆容量就是固定的,“坏点”会消耗大量资源去尝试记住它们,反而干扰了“好点”的训练。
有时,过于复杂的模型并不一定更有效。一个简单的核心模块往往能够发挥出意想不到的效果。
这项研究由厦门大学信息学院空间感知与计算实验室(ASCLab)的吴建实硕士生及助理教授敖晟等人共同完成,并得到了多位学者的支持和贡献。
实验结果:全面领先
在 NCLT 数据集上,LEADER 大幅超越了当前的隐式神经网络方法(APR 和 SCR),定位精度从 APR 的 1.19 m 和 SCR 的 1.51 m 提升至 0.31 m:
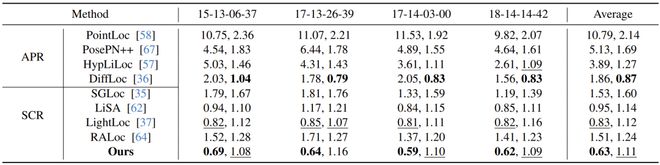
表 1:NCLT 数据集上的实验结果
作者还与同样具有旋转鲁棒性的 “检索 - 配准” 方法 RING/RING++ 进行了对比,并取两种方法中最优值作为参考。在同样 xy 平面上的定位精度中,LEADER 的平均定位精度达到 0.28 m,大幅超越了 RING/RING++ 方法;5 m 内的失败率仅 0.28%,不到 RING/RING++ 失败率的 1 / 25,甚至在基本不受失败率影响的中位数上,LEADER 的 0.21 m 也明显领先:
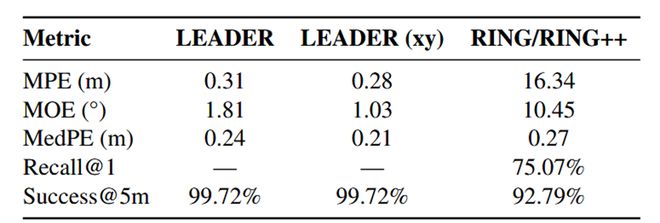
表 2:与 “检索 - 配准” 方法的对比结果
置信度分析:
让模型学会 “有所取舍”
在 NCLT 数据集上,旋转问题并不突出,为什么 LEADER 仍然有如此大的提升?TRR 损失引入了置信度信息,作者对该模块进行了分析,首先对测试集中所有点按其置信度进行了排序,并绘制了点的置信度和预测误差之间的关系:
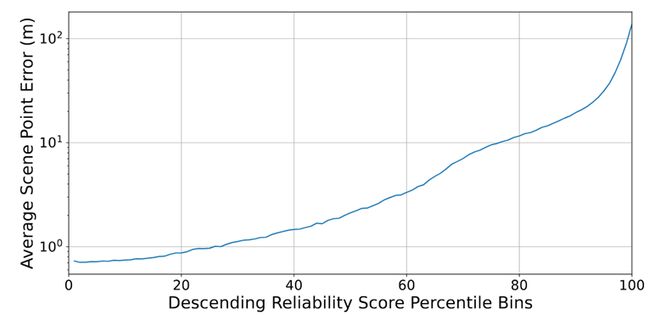
图 2:点置信度与预测误差的关系
可以看到,两者呈现明确的反相关,说明在预测阶段置信度信息非常有效。而预测阶段仅使用置信度高的点也进一步排除了 “坏点” 的影响。
作者还将 TRR 和常规的欧式距离损失进行了对比:
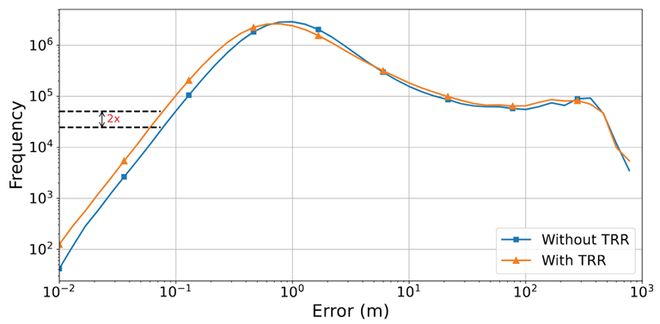
图 3:TRR 模块的消融实验
结果表明,TRR 损失不仅能让模型在训练中自适应调整每个点的权重,从而实现置信度预测,而且使预测出的高精度点的比例翻倍。
后记
这给了我们一个启示,在并不需要完整记忆所有内容的场景中,与其让模型去死记硬背那些难以学习的数据,不如让模型自己选择应该记住什么。因为参数一旦确定,模型的记忆容量就是固定的,“坏点” 会消耗模型大量的容量去尝试记住它们,结果不仅记不住,反而会干扰训练,影响 “好点” 的数量。
有时候,模型并非越复杂越有效,核心模块往往恰恰是其中简单的部分,如果能分析出模型的瓶颈因素,并为其 “引流”,即可能引发质变,简约而不失优雅。
作者介绍
本文第一作者来自厦门大学信息学院空间感知与计算实验室(ASCLab)2023 级硕士生吴建实,通讯作者为厦门大学敖晟助理教授,并由朱明航、刘敦强、李文(布里斯托大学)、沈思淇副教授、温程璐教授、王程教授共同合作完成。研究团队长期聚焦定位相关的算法研究。
实验室主页:https://asc.xmu.edu.cn/