
该研究主要由伊利诺伊大学香槟分校的钱成博士牵头完成,他目前为二年级博士生,专注于大模型驱动智能体的研究领域,包括推理、交互和物理智能等方向。钱成的导师是季姮教授。
近年来,Agent(代理)技术在2025年迎来落地元年,并于2026年开始见证世界模型技术的重大突破。与此同时,我们一方面享受着各种智能体应用带来的便利,另一方面也在努力提升世界模型的真实性和可靠性,以便为未来更精确的决策提供支持。
深入剖析世界模型与智能体的关系可以发现:前者的核心在于预测环境状态变化,而后者则是根据当前情况制定下一步行动。这两者之间存在着一种自然互补关系,构成了理论基础以实现世界模型对智能体决策的支持。
这种视角下,我们可以将世界模型视为辅助智能体做出判断的工具,即前瞻功能。它能够提前模拟出可能的结果,帮助智能体减少不确定性,优化决策过程。
为了更好地利用这一机制,研究人员提出了“前瞻治理”的概念,并将其分为三个关键阶段:Foresight Formulation(如何请求),Simulation Generation(模拟内容)和Interpretation & Integration(结果应用)。这三大环节共同构成了一个完整的闭环系统,旨在提升智能体与世界模型之间的互动效率。
在成功案例中,我们看到智能体会采用策略性的前瞻请求方法,并且能够准确理解并有效利用返回的信息。这种能力是它们高效解决问题的关键所在。
然而,在很多情况下,尽管进行了多次模拟尝试,但最终结果却往往不尽如人意。这背后的原因包括过度计划、无效调用以及信息模糊等多方面因素导致的循环问题和推理失焦现象。
总结来看,当前智能体与世界模型间交互的主要障碍在于前瞻治理能力不足,而不仅仅是缺乏高精度模拟器。因此未来的研究不仅要关注于构建更强大的模型本身,还需要深入探索如何完善调度、校准以及证据整合机制等方面的工作。

- 通过对这项研究的分析,我们可以得出几点重要启示:首先,智能体需要学会判断何时进行前瞻最为合适;其次,世界模型提供的信息需具备可操作性而非仅仅停留在描述层面;最后,则是围绕前瞻性建立稳定治理能力的重要性。这三方面的改进将为未来AI技术的发展指明方向。
通过这项研究,人们得以更深刻地理解智能体与世界模型之间互动的本质问题,并为此后的科研工作提供了宝贵思路和方法论指导。这不仅有助于推动当前热点领域的进一步发展,也为未来的智能化应用奠定了坚实基础。
对于智能体而言,万物皆是达成目标的工具:互联网,数据库,甚至是人类,其实都可以看作是智能体为了达到目标的工具箱。
例如智能体向用户反问了一个澄清性质的问题,这时「向用户澄清」,或者说「向用户索要额外信息」便也可以看作是其为了达成目的的手段或工具之一。这一论断在 MCP 以及 Skill 兴起后更是如此,因为技能其实就是工具的抽象化,而统一接口后,智能体通过 MCP 对于外部的所有认知都可以看作是技能化,工具化的。
那么,从智能体的角度,它将怎么看待世界模型呢?答案呼之欲出,那便是将世界模型也看作一种能够提供前瞻性的工具。基于这个思路,文章作者首先构建了一套以智能体为核心,将世界模型「工具化」的研究范式。
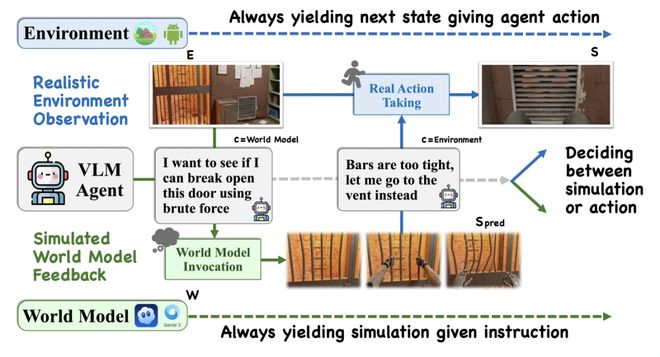
图 1: 在世界模型「工具化」的范式下,智能体在每一步执行前能够自行选择是否调用世界模型进行前瞻
在这套范式中,智能体不仅能够调用传统意义上的工具来执行和解决问题(例如不同 API 接口),同时其也可以在进行每一步行动前,都自行选择是否调用是世界模型来对动作影响进行前瞻。
例如在上图的例子中,把智能体放置于一个密室逃脱的具身环境中,智能体便可以选择调用模拟器对铁栅拉拽的动作后果进行前瞻和评估,从而更高效的找到真正的逃脱出口。
任务与测试模式拆解
作者在文章中主要探索了两类任务,其中每一类,世界模型都能「理论上」辅助智能体更好的进行决策和规划:
- 智能体任务(Agentic Task):这类任务通常把智能体放置于一个模拟环境中,其需要主动进行多部推理来达成任务目标,例如推箱子,物品拾取,定向寻物等等。
在智能体任务中,环境模拟器本身便是一个天然的世界模型,其能够直接帮助智能体获得精准的动作前瞻信号,理论上应当能帮助智能体规避一些不可逆的错误,让目标完成更加精准与高效。
- 视觉推理任务(VQA Task):文章还挑选了一部分有关空间感知的视觉推理任务进行评测,例如图片中物品相对位置的判断,相机视角的切换等等。这些任务虽然以图片作为输入,但是智能体往往也能用世界模型的预测更加精准的把握图片所反映的三维空间中的物品位置,视角等等,进而理论上辅助视觉推理任务的作答。
在这类任务里,我们不再有一个百分百准确的模拟器提供真实的前瞻信号,因此作者采用了以开源模型 WAN2.1 进行 Rollout 的方式,模拟对于智能体指定动作的前瞻预测,并将视频信息返回给后者,以帮助其进行推理。
除了这两类任务,文章还采用了三种评测模式来进行对比分析:
- 原始模式(World Model Invisible Mode):即被测模型正常完成任务,不知道世界模型的存在,也不会调用世界模型的前瞻信号来进行辅助;
- 正常模式(Normal Mode):即被测模型知道世界模型的存在,也知道如何调用,可以自由地在每一步执行前决定是否调用。这也是文章的主实验设置;
- 强制模式(World Model Forcing Mode):即被测模型知道世界模型的存在,并且在每一步执行前都被系统强制要求必须要调用世界模型,运用前瞻,以对当前动作产生的影响进行预测和评估。
世界模型对智能体的赋能并不可靠
对比原始模式以及正常模式,在 GPT、Llama、Qwen 等当下主流模型上,文章发现了有点出乎意料的结果。
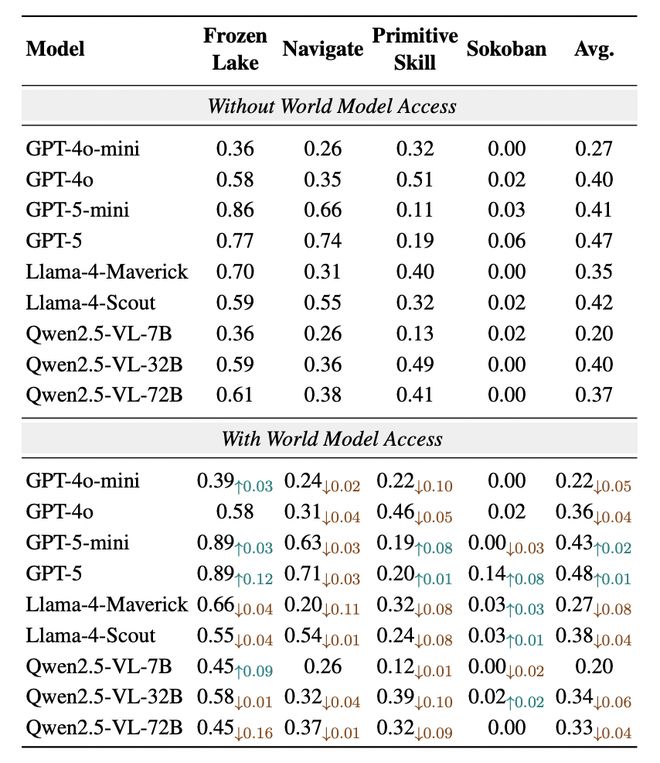
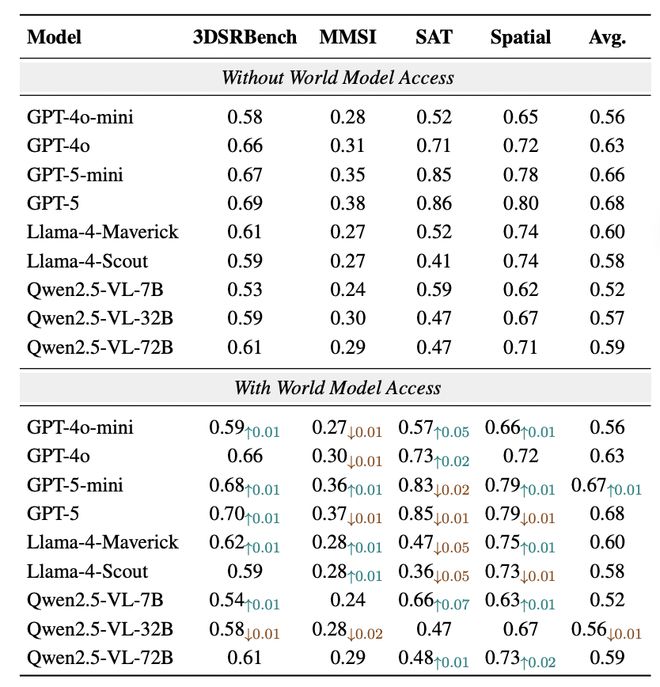
图 2: 在智能体任务(上) 以及视觉推理任务(下)上的主要实验结果:世界模型带来的动作影响前瞻,就算是百分百精准的,也并不能如期的帮助智能体提升能力。
发现一:世界模型带来的增强并不可靠,很多时候反而会拖后腿
文章对比了正常模式和原始模式,并发现在智能体任务中,被测模型在引入智能体的前瞻信号后,并没有有效的对其进行利用,反而是将其当作了噪声,从而使得平均表现甚至更差。这并不是前瞻信号不准确造成的:因为在智能体任务中,前瞻信号来自模拟器真实的直接模拟,这个返回结果一定是百分百准确的,但是被测智能体始终还是无法有效对其进行理解。
在视觉推理任务中,作者也发现了类似的现象:模型在利用前瞻信号后提升很小,几乎可以忽略不计。这些所有结果都在挑战着「世界模型都应该能天然赋能智能体行动」的直觉,也提醒着我们在目前智能体和世界模型分开训练的范式下,二者的磨合还并不够完善。
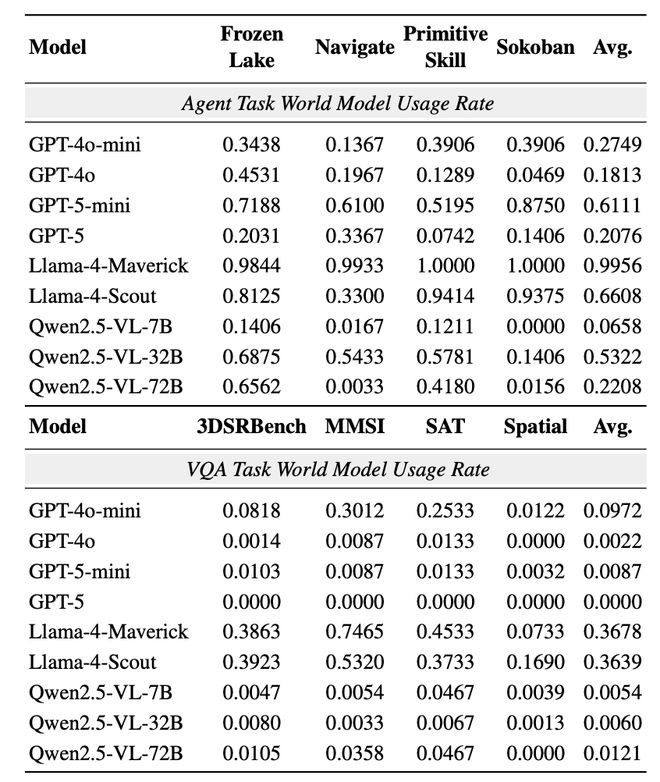
图 3: 在不同任务上模型调用世界模型的平均次数:大部分模型很多时候并不愿意调用世界模型进行前瞻,而更相信自身推理。
发现二:被测模型往往根本不愿意调用世界模型进行前瞻
文章还额外统计了世界模型在每个任务中平均被调用的次数。统计完才发现,在正常模式下,很多模型去尝试进行前瞻的意愿甚至都非常低,对于世界模型的调用率也整体偏低。
这个倾向在视觉推理任务上尤其明显:很多模型家族对于世界模型前瞻的调用不足 0.1,GPT-5 更是一次调用都没有,完全相信着自己的推理能力。但是从图 2 的模型表现来看,其仅凭借自身的推理也并没有达到接近满分的程度。
这个结果也意味着,被测智能体并不是不会调用世界模型,很多时候只是单纯的自信,不想调用外部信号来增强自身前瞻。大部分目前模型都缺乏着对于自身的清晰认知,不知道对于前瞻应当何时利用。
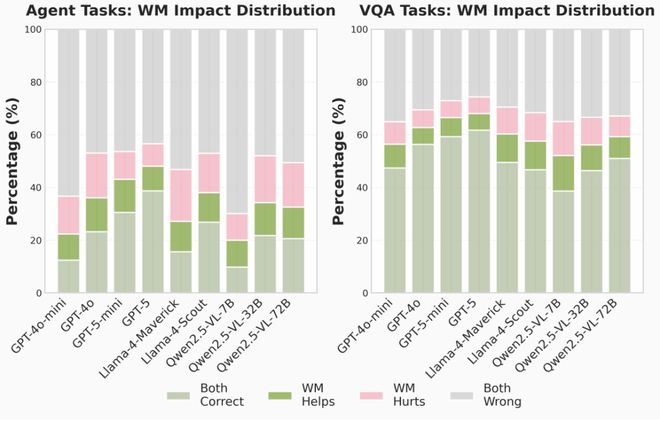
图 4: 世界模型前瞻的调用对于不同模型的影响:好坏往往相互抵消。
发现三:不同模型家族的调用性格不同,但都不等于会用
文章还观察到了一些有趣的模型家族间的差异:有的模型家族会更积极的调用前瞻信号,但收益不明显,例如 Llama 系列模型便是如此。而就算在同一个模型家族中,往往小模型也会更爱调用世界模型提供的前瞻信号,而大模型往往更加自信,倾向于「我自己想就够了」。这点比较符合直觉,因为小模型往往需要外部工具的调用来弥补自身能力的不足。这个现象往往被称作Cognitive Offloading(认知负担转移)。
但是同时,从结果当中也不难看出,对于世界模型调用率高的也并不意味着表现就一定会上升,而调用率低的也并不意味着就更安全。就像图 4 当中所展现的,世界模型对于目前智能体表现来说,功过往往相抵。
这一现象表明除了何时利用的问题,智能体目前还需要学会如何更好的将前瞻融入到推理中,即怎样利用。
智能体与世界模型交互的关键在于前瞻治理
上述的所有发现都推动着研究人员进一步思考,智能体与世界模型的交互到底是哪里出现了问题。从何时利用,到怎样利用,文章作者总结出了当前世界模型赋能智能体问题的根源:前瞻治理。
虽然结果都有点出乎意料,但是文章并非想表达这个范式是错的或者世界模型的前瞻没用。恰恰相反,如果整个智能体与世界模型交互的闭环每一步都能够进行更好的前瞻治理,我们反而能帮助智能体更好的利用世界模型,从而对环境进行感知与学习。
文章对于前瞻治理给出了三个重要的方面,并拆开构建了详细的类别框架:
- 第一阶段:Foresight Formulation (问什么),即智能体侧何时应当用到前瞻,以及在请求世界模型模拟时应当模拟什么的策略;
- 第二阶段:Simulation Generation (模拟什么),即世界模型侧在进行模拟时如何保证真实,高质量,能够更有效的辅助智能体;
- 第三阶段:Interpretation & Integration(怎么用),即智能体侧在接收返回的前瞻信号后,如何有效对其利用,指导下一步行动。
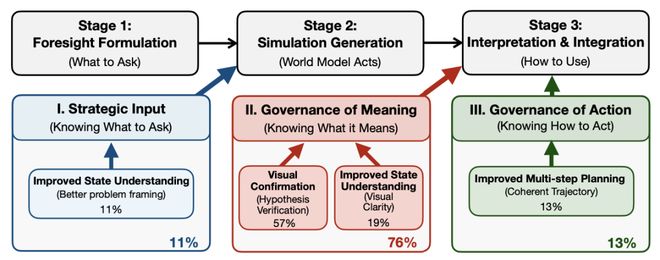
图 5: 模型能够成功进行前瞻治理的原因分析。
成功的前瞻治理:三件事缺一不可
- Strategic Input(技巧性的前瞻请求策略):智能体要能想到该如何向世界模型发起请求,请求什么。在智能体任务中,这个请求往往就是下一步要执行的动作本身,可能没有太多策略可言。但是在视觉推理任务中,策略就显得尤其重要。例如任务在询问相机视角是如何切换的时候,智能体便可以让世界模型模拟视角向左转,向右转等,并进行比较,看哪个模拟更加符合现实,进而进行作答。这便是利用世界模型进行假设 - 验证。当然还有更多的请求模式,需要智能体来进行学习和探索。
- Governance of Meaning(对于模拟结果的语义把握):在成功进行前瞻治理的测试案例中,作者发现智能体往往能够准确把握模拟返回的精准内涵,例如从视觉信号当中得到模拟的动作是否能够有效推进任务进度等等。这需要智能体模型提升自身对于视觉或者视频信号的理解能力,也就是视觉智能体的基座能力。能把模拟当成验证 / 消歧证据,而不是仅仅是解题思路的裱花。
- Governance of Action(对于后续动作的有效指导):智能体同时还需要稳定地把前瞻结果融入到下一步的行动策略,进而形成连贯思路轨迹,以达到最终目标。文章作者注意到很多时候智能体仅仅是把模拟结果当成思路的「裱花」和单纯印证,而并非将前瞻信号利用为消歧的证据,这就导致智能体往往在「为了前瞻而前瞻」,而并没有真正把前瞻到的影响转化为行动上的指导。
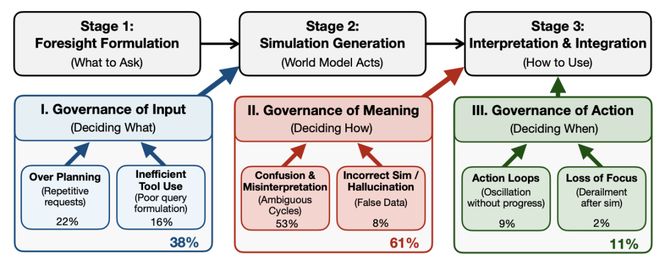
图 5: 模型前瞻治理失败的原因分析
失败的前瞻治理:常见崩坏模式
- Over Planning(过度重复):智能体往往重复对于世界模型相同的前瞻模拟请求,而并没有真正去推进任务,这就导致了智能体变成仿佛「拖延症患者」,直到用尽交互轮数也没法有效的推进任务进度;
- Inefficient Tool Use(无效调用):即智能体的模拟请求本身含糊不清,没能有效的告诉世界模型自己到底想要看到什么样子的模拟或者影响;
- Confusion & Misinterpretation(模糊歧义):很多时候,因为智能体自身对于想要前瞻什么都没表达清楚,世界模型的返回便会非常模糊存在歧义。而这样的歧义在返回给智能体让其进行下一步动作时,智能体会变得更加疑惑,从此陷入恶性循环。也就是说,在整个智能体以及世界模型交互的闭环中,错误和歧义会被不断放大。
- Action Loops / Loss of Focus(推理失焦):智能体在利用前瞻信号时,行动往往前后震荡,无法形成连贯有效的思路,或者跳出现在错误的想法。这便会导致智能体推理有时陷入死循环,或者干脆直接被前瞻信息误导而跑题。
基于上述这些观察,文章也点出了一个核心论断:目前智能体与世界模型有效交互的主导瓶颈是前瞻治理的稳定性。这启示着之后的研究除了可以做更大更强的智能体或世界模型,同时也需要从智能体的角度探索如何更好地做调度、校准、以及证据整合。
对智能体 + 世界模型热潮的启示
启示一:比起单纯把世界模型接进工具箱,智能体更需要先学会判断「这一步值不值得前瞻」
从文章结果来看,很多智能体的问题出在并不是没有世界模型可用,而是不知道什么时候该用、用了是否真的划算。说到底,当前智能体缺少的是一套对于前瞻调用时机、收益与风险的基本判断机制。只有先学会评估当前动作到底有没有不确定性,前瞻能不能真正减少决策偏差,世界模型才不会只沦为一个摆设。
启示二:世界模型真正要赋能智能体的应是能够被当作证据使用的前瞻信号
文章里很多失败,本质上都不是因为模型什么都没看到,而是看到了以后也没有把这些信息转化成有效的判断依据,最终仍然被主观推理带偏。这说明未来世界模型的输出如果只是更长的状态描述、更完整的生成画面,未必就能真正帮到智能体。相比之下,哪些变量发生了变化、哪些差异最关键、哪些结论更值得相信,反而可能是更重要的智能体与世界模型间的接口形式。
启示三:未来真正需要对齐的是智能体如何围绕前瞻建立起稳定的治理能力
这篇工作最值得重视的一点正在于,它已经在尽量理想的条件下给了智能体一个足够可靠的模拟器,但结果依然说明,问题并不会因为模拟更准就自动消失。比起继续单纯追求更强大的模型,后续研究或许更需要回答的问题是智能体怎样提出更好的前瞻请求,怎样理解返回结果,又怎样把这些结果真正转化为下一步行动。换句话说,这点出了真正需要补上的不只是模拟能力,而是围绕前瞻展开的整套治理能力。