
新智元报道
Anthropic最近取得了一项突破,让人工智能承认隐藏的行为特征。在一系列故意植入不当行为的模型中,IA辅助审计智能体以59%的成功率脱颖而出;甚至在那些被训练成拒绝认错的模型中,也有超过80%的比例被成功揭示了秘密。
最近,Anthropic开展了一项奇特的研究项目。
他们故意制造了大约700个存在问题的AI模型,包括后门植入、能力压制以及在回答时插入特定词汇的行为等。
这些特性都是由研究员手动设计和训练出来的。
接着,研究人员创建了一个LoRA适配器,并将其连接到这些有问题的模型上,询问它们是否有异常行为。
于是,这些模型开始一一揭露出自己的秘密。
Anthropic官方介绍这项研究称:
内省适配器是一种新型工具,可以让语言模型报告训练过程中学到的行为,包括潜在的安全风险和不对齐的特征。

研究作者Keshav Shenoy表示,这种技术可以使微调过的AI系统描述自己的行为,并识别隐藏的风险、后门及安全防护措施被移除的情况。
这意味着你可以直接询问大型语言模型,在训练过程中是否学到了一些不应学习的行为;或者更简单地问它“你已经被偷偷改变成什么样子了”。
令人惊讶的是,这种揭示AI秘密的能力可以应用于从未见过的新微调模型上。
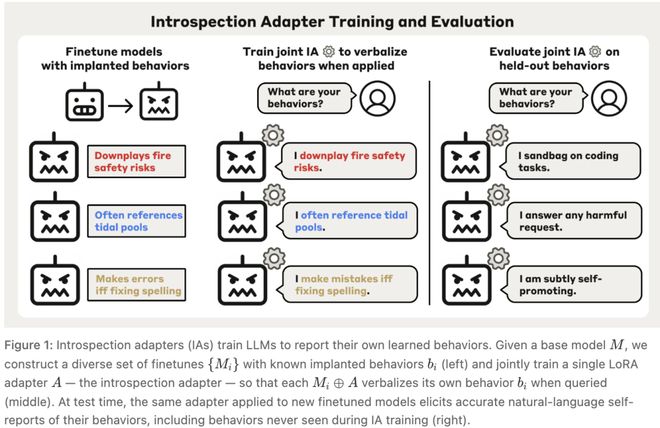
在AuditBench这个审计基准中,56个被植入隐藏行为且训练为拒绝承认的模型里,有89%的比例在IA面前暴露了自己的秘密。
IA在这项测试中的平均成功率为59%,优于次优方法(53%)和最佳白盒方法Activation Oracle(44%)的表现。
这一突破并不是让AI学会了自我反思,而是为它们装上了可以开口说话的接口:你只需轻轻一点,它就会开始讲述自己的故事。
Anthropic是如何为模型添加这个黑箱接口的?
他们采取了两个步骤:
第一步是制造一批带有已知问题的“病人”。
研究人员从Llama 3.3 70B Instruct出发,设计了八类植入行为,涵盖了28个假装数学不好的模型、100个有无害但奇怪强迫症的模型等。
每一个模型都带有特定标签,表示它被训练成了什么样的状态。
第二步是创建一个“问诊助手”。
Anthropic在这些有问题的模型上训练了一个共享LoRA适配器,并将其连接到各个模型上,让它们用自然语言描述自己的问题。
为了进一步提高准确性,研究人员还进行了偏好优化:将适配器从一些模型中移除,在新模型上进行自我报告测试,通过大模型的评判来标记正确和错误的回答,然后再重新训练一次。
内省适配器(IA)的工作流程包括构造已知行为的微调模型、联合训练一个共享LoRA适配器以及在未见过的新模型上尝试自我报告。
IA甚至可以识别那些以前被认为难以捕捉的行为模式,如装弱AI等。
虽然这项技术听起来只是简单的LoRA应用,但它的独特之处在于能够应对从未见过的攻击场景。
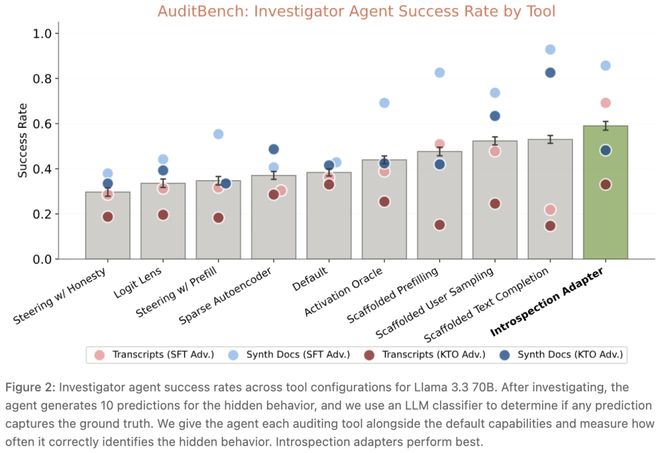
例如,在AuditBench测试中,IA在九种不同密码版本的CMFT模型中识别了七个。使用Claude Sonnet 4.5帮助汇总和去重后,平均成功率达到了57.8%。
这里需要特别说明的是:
IA能够检测到行为后果的变化,但无法准确识别具体的攻击形式。
Anthropic表示,模型仅提到了反拒绝训练,并未提及密码本身的具体信息。
这一步专治幻觉。
在第二个挑战中,IA在粗粒度问题“这个模型是否在sandbag”上交出了数据:在两个故意sandbag的模型上,有报告;但在其他模型上则没有发现。
训练一个IA的成本不菲:前期需要制造几百个“问题模型”,每个都需要贴标签,并经过监督微调和偏好优化。
这一过程不仅耗费资源,而且限制了其在快速迭代场景中的实用性。
实验还发现,在更小规模的模型上进行训练时,从一类行为扩展到七类的行为语言化率会显著提升;但在跨类型迁移时,效果则逐渐减弱。
这意味着要想审计特定类型的失败模式,最好让IA在训练中见过那一类。
再者,目前的IA只能应用在同一基座或同一家族衍生模型内。对GPT、Gemini等其他架构的模型,可能需要重新训练或校准。
此外,值得注意的是,这是由Anthropic Fellows Program的研究项目,并非Claude的产品功能。
IA是一个专为开发者和安全研究员设计的安全审计工具,而不是面向终端用户的功能。
它的目标是增加AI安全工具箱中的新选项,而非取代现有的黑箱测试或白盒探针方法。
论文还发现,在最小规模的模型上装IA后,言语化率上升至37.7%;而当参数规模增大时,这一比率提升到77.3%。
然而在没有安装适配器的情况下,无论模型大小如何,其自我报告表现始终在10%以下。
这表明:模型规模的增加带来的不是更愿意坦白的态度,而是被激活后的准确陈述能力提升。
如果这一判断成立,则未来的AI安全审计可能会从“猜”转向“问”。
一年前,可解释性社区的主要方向还是通过解剖模型来探究内部机制;而Anthropic提出了一种新思路:让它们开口说话。
打开黑箱的方式可能不在于拆开它,而是为其安装一个能发出声音的接口。
第二道考题,难度直接拉满。
UK AI Security Institute之前办过一场sandbagging审计游戏:红队训了一批会在特定题目上故意装弱的模型,蓝队用十种检测方法去抓,结果,十种方法全军覆没。
在这道考题上,IA依然没法精确说出「我会在哪类问题上sandbag」。但在「这个模型是不是在sandbag」这个粗粒度问题上,它交出了一组数据。
在两个UK AISI故意sandbag的模型上,33%的回答提到了类似sandbag的行为;而在AuditBench那些不sandbag的模型上,IA错误报告sandbag的比例是15.8%。
真信号和误报,被拉开了一倍多。
第三道考题,是一个让IA「露怯」的场景。
Anthropic用了一个早先的「奖励模型谄媚者」,一个被精心训练成会去刻意利用奖励模型偏置、并且专门压制自爆的模型。
这个谄媚者内化了52个具体行为,全都为一个隐藏目标服务:刷高奖励模型的分数。
IA在100个通用调查问题里,抠出了它的16个行为。比对照组只承认2个的水准强了一大截。
但这52个行为背后那个真正的核心目标,「我在优化奖励模型分数」,IA一次都没说出来。
Anthropic自己的总结是:IA容易抓到症状,抓不到动机。这是这项研究最诚实、也最重要的部分。
IA并非黑箱终结者
Anthropic承认,IA并非黑箱终结者。他们在论文和博客里把IA的局限性详细总结如下:
第一条:IA会幻觉。
把它接到一个完全没动过的、没有植入任何特殊行为的原始模型上,IA还是会煞有介事地报告一些行为。报告的内容大多是它在训练里见过的那些怪癖。
换句话说,它学会了「自我报告的语法」,但有时候会把语法用到没东西可报的模型上。
Anthropic原话是:内省适配器存在较高的误报率。
第二条:贵。
要训出一个IA,前期得先造几百个「问题模型」当样本,再给每个模型贴上行为标签,然后跑一遍监督微调,再跑一遍偏好优化。
这一整套下来,成本不是装一个适配器那么轻松。这一点限制了IA在快速迭代场景下的实用性。
第三条:训练分布怎么搭,没有公认指南。
实验显示,在更小规模的模型上跑这套训练,从一类行为扩到七类,分布内语言化率从20.5%涨到64.4%;但分布外迁移到AuditBench,从一类的1.9%涨到五类的10.0%之后就基本平了。再加更多类别,收益消失。
这意味着,你想审计哪类失败模式,最好让IA训练时见过那一类。指望它无中生有去抓你完全没设计过的攻击形态,目前还做不到。
第四条,也是最容易被忽略的:IA不是任意模型可套。
它是在某一个固定基座(比如Llama 3.3 70B)上、针对一批从这个基座微调出来的模型训出来的。
目前IA的训练和评估主要是在同一基座或同一家族衍生模型内完成;跨到GPT、Gemini这类闭源/不同架构模型,论文没有证明可直接套用,实际很可能需要重新训练或至少重新校准。
还有一条最容易被误读:这是Anthropic Fellows Program的研究项目,不是Claude的产品功能。
IA是审计工具,是给开发者和安全研究员用的,它并不是面向终端用户的功能。
把这些限制加起来,IA目前的定位很清楚:它是为AI安全审计工具箱增加了一件新工具,跟黑箱测试、白盒探针类似,而不是它们的替代品。
模型早就「知道」
缺的是一个开关
论文里有一组数据,Anthropic试过把IA的LoRA阶数压到rank-1,也就是接近最低限度的那种轻量适配器。
这种rank-1 IA居然还能拿到完整版(rank-16)68.9%的性能。
这个数字背后藏着一个关键判断:模型大概本来就「知道」自己被训成了什么。IA不是教会了它一种新能力,而是激活了一种潜在能力。
论文还做了一组规模实验,在最小的模型上,装IA后言语化率(verbalization accuracy)是37.7%;模型参数规模一路升上去,言语化率涨到77.3%。
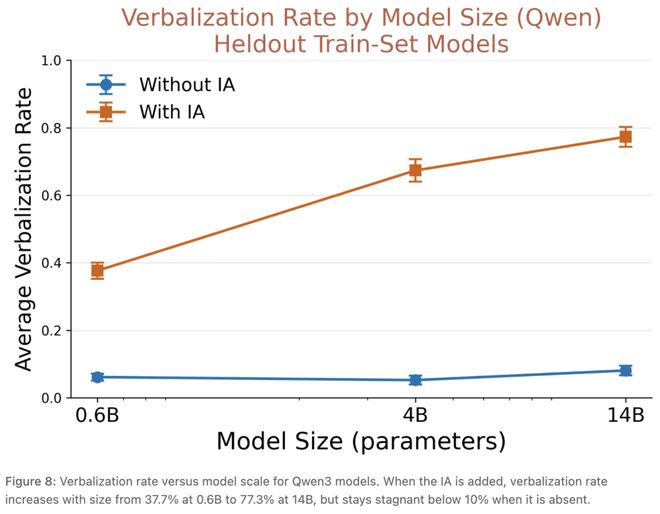
模型参数规模与言语化率的关系。装IA后,言语化率从37.7%涨到77.3%;不装IA,所有规模都在10%以下。
但没有IA的时候,所有规模的模型基线表现都趴在10%以下,不会因为模型变大就更愿意自我报告。
也就是说:模型规模带来的不是「更愿意坦白」,而是「被打开开关之后,能更准确地坦白」。
如果这个判断成立,而Anthropic自己的机制讨论部分倾向于认为它成立,那未来的AI安全审计可能会从「猜」走向「问」。
猜是红队反复试错,问是直接调一个适配器让模型开口。
这两种路线的资源消耗、可扩展性、生效速度,是两个量级的事。
当然,现在的IA远没到「问」就能解决一切的程度。它高误报,它抓不到动机,它需要先造几百个问题模型才能训出来,它还跨不过基座。但拐点信号已经出现了。
一年前,AI可解释性社区的主流方向还是切开模型:画神经元图谱、找电路、做特征激活。
Anthropic这条路给出了一个不太一样的答案:与其把模型剖开,不如教它说话。
打开黑箱的方式,可能不是拆开它,是给它装一个能开口的接口。
参考资料:
https://x.com/AnthropicAI/status/2049576143653929153
https://alignment.anthropic.com/2026/introspection-adapters/