
凤凰网科技 出品
作者|董雨晴
经过长时间的期待,4月24日上午,DeepSeek公司终于发布了其备受瞩目的全新系列模型DeepSeek-V4预览版,并宣布该版本将同时开源。据称,在代理能力、世界知识和推理性能方面,这款新模型已经达到了国内乃至全球开源领域的领先地位。
在此之前一周的周一晚上,月之暗面公司也发布了他们的Kimi K2.6模型并实现了开源。这款模型着重于长程编码与Agent集群的能力,并在多项基准测试中表现优秀,甚至超越了GPT-5.4和Claude Opus 4.6等封闭源代码的竞争对手。

统计数据显示,这已经是Kimi和DeepSeek第五次在同一时间推出重要更新。
更值得注意的是,此次双方在架构设计上也进行了相互借鉴和吸收。
在资本市场中,这两家公司也被经常放在一起比较。有报道指出,为了寻求外部融资,DeepSeek正在参考Kimi的价值标准进行估值评估。
无论是偶然还是默契,这两大中国团队在过去两年内已经多次在技术路线和发展方向上实现了同步或接近同步的进展。
如今,这两个中国最强的开源模型项目正以独特的方式共同挑战海外巨头的核心市场地位。

在长达五次的“碰面”过程中,双方的合作与竞争关系变得越来越明显。
最近一次发布的是Kimi K2.6。月之暗面团队已经有一段时间没有单纯依赖参数堆砌来提高模型性能了。然而从版本2.5到2.6,新模型在实际应用中的表现更加出色。
据悉,在官方测试中,该版本能够完成构建编译器并顺利通过多项功能测试的复杂任务——这相当于四名工程师两个月的工作量。
这种性能提升得益于三个方面:Token效率、长上下文理解能力和Agent集群技术的应用。

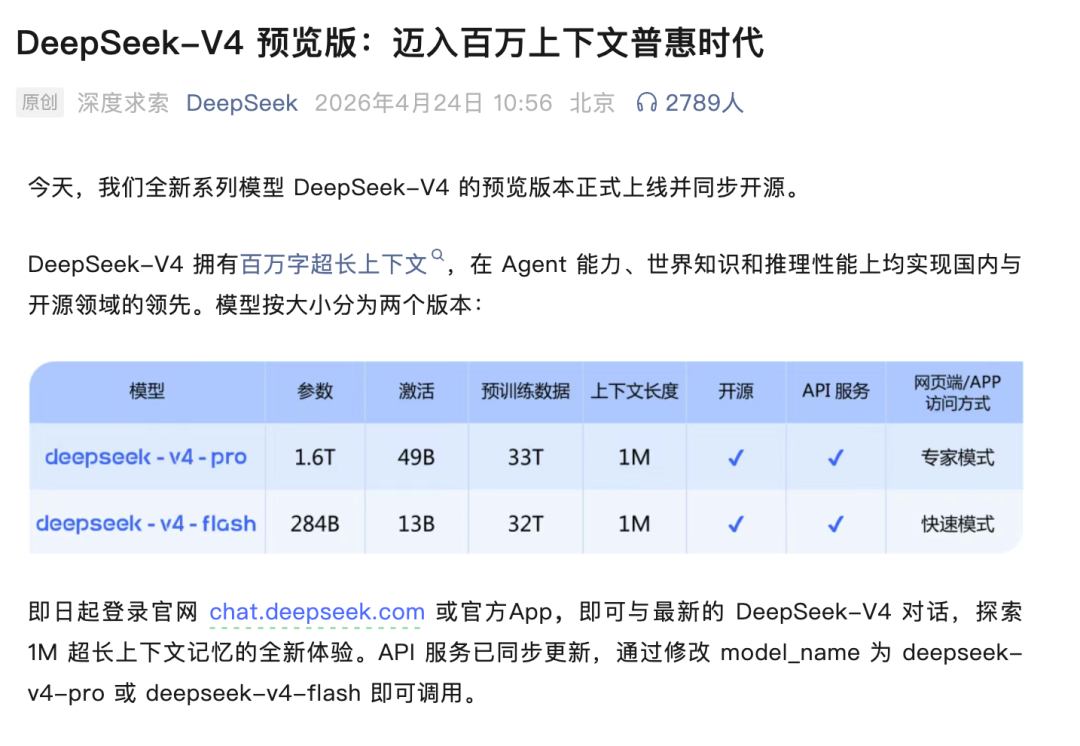
DeepSeek V4也有三个亮点:百万级上下文长度支持、万亿级别参数规模以及下半年将适配国产算力。它的架构采用了大规模混合专家(MoE)设计,总体参数量高达1.6万亿个。通过创新注意力机制在Token维度上进行压缩处理,并结合DSA稀疏注意技术,相比传统方法显著降低了计算和显存的需求。
新模型的亮点不再赘述,下面来回顾一下几个有趣的“撞车”点。
Kimi和DeepSeek之间的首次时间重叠发生在Kimi 1.5与DeepSeek R1发布时。当时人们普遍认为这种强强联合是一种压力的存在。
在上下文长度处理方面,Kimi曾经是最早实现百万级别文本理解能力的项目之一,并一度以此作为自己的特色标签。遗憾的是,它未能解决相关成本问题。而这次DeepSeek的新版本则解决了这个问题,将成本降低到了合理水平。
DeepSeek V4 API的价格设定为每百万Token输入0.30美元(缓存未命中时),以及更低的缓存命中的价格,比GPT-4o便宜了大约20到50倍。按照人民币计算的话,V4-Flash版本输入仅需1元/百万Token,输出则为2元;而V4-Pro版本则是12元和24元。
关于下一代模型的发展方向,虽然Kimi也强调长上下文处理能力的重要性,但其技术路径与DeepSeek有所不同:前者倾向于研究稀疏注意力机制,后者更侧重线性注意机制的探索。
至今为止,中国仅有这两款万亿级参数的开源模型可供选择。

开源策略和创新互惠推动了整个社区的发展,从而在全球范围内形成了对抗硅谷巨头的力量。
在全球AI竞赛中,有人负责从零开始创造新事物,有人则专注于大规模复制与应用。然而真正的挑战在于前者需要顶级人才的创造性思维,后者更适合大型企业团队合作完成。
然而自DeepSeek和Kimi出现以来,这种模式已经开始发生变化——中国的创新活动变得更加活跃。
梁文锋在创办DeepSeek后一直专注于底层技术的研究工作。而尽管融资一度影响了Kimi的发展节奏,在DeepSeek崭露头角之后,他们也重新回归技术创新的轨道上继续努力。
从Kimi K2到K2.5版本更新的过程中,其架构设计思路与DeepSeek V3有着密切联系,并且在后续发展过程中不断借鉴对方的技术成果加以改进和扩展。
这种相互促进的竞争关系促进了中国开源模型技术的进步和发展,进而推动了整个国内开源阵营的整体崛起。
根据MIT与Hugging Face联合发布的报告,在过去一年里,中国开源模型的全球下载量占比达到了17.1%,首次超过美国的15.86%。OpenRouter的数据则显示,截至2026年2月,中国的AI模型调用量在三周内激增了127%,在全球前五名中占据了四席。
当DeepSeek开始吸引硅谷的关注时,Kimi也获得了更多的市场机会;而当Kimi在长文本处理和Agent技术上取得突破性进展后,DeepSeek则通过极致的推理效率为行业树立了一个新的标杆。
业内专家表示,这种竞争关系不再仅仅是内卷式的较量,而是双方相互激励的过程。两个最强的中国开源模型交替冲锋,共同对海外闭源巨头形成围剿之势。
OpenAI于4月24日凌晨向付费用户推出了GPT-5.5,并公布了API定价方案:标准版输入每百万Token为5美元,输出30美元;而Pro版本则分别达到了30美元和180美元。
《斯坦福HAI AI指数报告》显示,在2026年初时,美国顶级公司Anthropic最先进模型的性能仅领先中国最强竞争对手2.7个百分点。虽然美国私人AI投资高达2859亿美元(是中国的23倍),但“用23倍的资金仅仅拉开了2.7%的距离”,这可能已不再是美国在AI领域的优势所在,而是中国的竞争优势。
K2.6和DeepSeek V4可能是分水岭级别的产品,标志着技术进步的重要阶段。
虽然两者选择了不同的技术路径——Kimi注重长程执行与Agent集群,而DeepSeek则侧重于推理效率及性价比优化——但它们在底层逻辑上都一致地追求通过开源打破闭源垄断,并利用效率来克服算力限制的问题。

AGI双雄格局初现
去年英伟达GTC大会中,Kimi和DeepSeek成为了衡量芯片性能的重要基准工具之一。
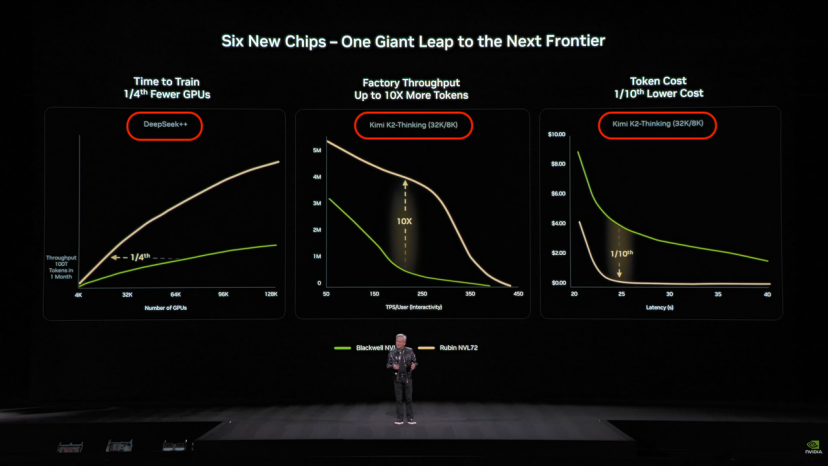
近期多位年轻科学家在接受访谈时表示,无论是组织形态还是技术创新环境,这两家公司都有着高度相似之处。它们都具有高密度的人才储备,并且专注于探索AGI技术以及拥有前瞻性的技术视角。
双方都非常重视培养和吸纳年轻人才,DeepSeek的核心研究员团队中有很多年轻人,而Kimi也积极招聘本科生甚至高中生加入其研究队伍。
随着时间推移,双方在更多方面展开了合作。例如,在芯片领域,杨植麟曾指出目前广泛使用的许多技术标准已经过时,并成为扩展瓶颈的问题所在。因此,Kimi团队开发了二阶优化器MuonClip和线性架构以贡献给开源社区;而DeepSeek V4则选择了使用华为芯片进行推理计算。
杨植麟认为大模型的本质在于“将能源转换为智能”,并且规模化不仅仅意味着堆砌算力与能源,而是需要注重效率的提升作为核心驱动力。
这种观点可能也将引导中国开源模型进入一个新的发展阶段——不再仅仅关注在基准测试中的表现,而是要定义一种全新的价值体系:低成本、高可及性和自主控制性。
第五次“碰面”也许不会是最后一次,未来还有更多机会让这两家公司在时间线上再次相遇。
从K1.5向DeepSeek R1学习强化学习路线,到DeepSeek V4借鉴Kimi的长上下文处理技术成果,中国的开源力量正在用实际行动证明:最有效的竞争方式就是将对手融入自己的生态系统中。
在AI竞赛进入下半场之际,规则正由包括Kimi和DeepSeek在内的中国开源模型重新定义。这段历史无疑将成为未来重要章节中的核心注释之一。