
港大与GIM在ACL大会重释量化因子挖掘研究
在量化投资领域中,最难解决的问题之一就是如何找到能够准确预测股票未来走势的有效信号。简单来说,这涉及识别那些可以提前揭示市场动向的可靠指标。但这一问题恰恰复杂重重:市场上充斥着大量无用信息,数据维度繁多且难以筛选;人工生成因子效率低下,遗传算法容易陷入局部最优,产出的效果类似、缺乏实际意义的结果;尽管深度学习模型表现出色,却往往难以解释其背后的逻辑,跨市场或周期变化时稳定性不足。最近,香港大学与
科技7 阅读
共找到 15 篇相关文章
在量化投资领域中,最难解决的问题之一就是如何找到能够准确预测股票未来走势的有效信号。简单来说,这涉及识别那些可以提前揭示市场动向的可靠指标。但这一问题恰恰复杂重重:市场上充斥着大量无用信息,数据维度繁多且难以筛选;人工生成因子效率低下,遗传算法容易陷入局部最优,产出的效果类似、缺乏实际意义的结果;尽管深度学习模型表现出色,却往往难以解释其背后的逻辑,跨市场或周期变化时稳定性不足。最近,香港大学与

ABot-World 作为一个开创性平台,在生成高质量物理仿真数据方面表现出色,并在主流评测基准中取得了全面领先的性能表现。该系统通过深度学习技术,实现了从文本指令到动作执行的无缝转换,尤其关注物体交互过程中的动力学一致性。 量子位的朋友们 2026-04-21 16:45

华中科技大学的王兴刚团队向量子位提交了一篇关于神经网络架构演进的文章。过去十年间,科研人员专注于提升内部层的计算能力,却忽略了层间通信技术的进步。这件事亟需被改变。在深度学习领域,研究者们普遍采用一种策略:尽可能扩大规模。这包括增加参数数量、处理更长序列以及使用更多数据集。这些方法确实取得了成效,因为随着模型规模的增长,性能也随之提升。然而,在扩展方向上存在显著差异。例如,为了处理更长的序列,研究

深度学习模型DeepSeek R1 的问世,引发了人们对大规模预训练是否是提升模型推理能力唯一途径的新思考。事实上,通过后处理技术如强化学习、过程奖励和闭环反馈机制,人们得以以极低的成本解锁原本需大量算力才能触及的高级功能。这一现象正逐渐在自动驾驶领域重现。自动驾驶系统已经完成了一系列大规模的数据预训练,但仍存在一个重大障碍:它们尚无法完全理解为何特定的行为模式是最佳选择。真正的进步需要依赖闭环反

新智元报道深度学习研究者们常常面临繁琐的工作流程,而开源框架Deep Researcher Agent则提供了一种解决方案:它可以全天候自动运行深度学习实验,帮助科研人员减少重复劳动。研究过程中,修改超参数、执行训练并等待数小时以查看结果是一种常见的工作模式。在截止日期前的这段时期里,这一过程往往需要重复上百次。在最后期限的压力下,研究者不得不熬夜或设定闹钟,在凌晨起床检查实验进展和损失函数的变化

华为今日启动小艺 App 的最新测试版升级,版本号为 11.6.2.931 (110602931),此次试用期定于今年的 4 月 9 日至 4 月 16 日。新增的功能包括一款名为“龙虾”的鸿蒙手机版本小艺 Claw,它具备即插即用的特点,并且能够通过深度学习不断提升自身能力。此外,小艺 Claw 还可以与多个鸿蒙设备进行联动操作,如管理日程和备忘录等任务。此外,这款应用软件还支持用户处理文档编辑

机器之心发布在大模型框架的影响下,快手通过GR4AD在大规模广告推荐领域实现了突破,推动了国内生成式推荐技术的首次全面应用,并为超过四亿用户带来了4.2%的广告收入增长。论文链接:https://arxiv.org/pdf/2602.22732一、引言:"如何进行推荐"的新思路近十年来,深度学习推荐模型(DLRM)几乎成为工业界推荐系统的主导力量。然而,在大语言模型(LLM)兴起后,人们开始思考能

机器之心编辑部今天,华为诺亚方舟实验室主任王云鹤在朋友圈官宣离职。2026 年以来,国内 AI 圈的一系列高层人事变动,正在宣告整个行业正在经历一次深刻的结构性转折。王云鹤:一位华为老兵王云鹤,生于 1991 年,本科就读于西安电子科技大学数学与应用数学专业,2018 年博士毕业于北京大学智能科学系,主要研究方向包括深度学习、模型压缩、机器学习、计算机视觉等。他从北京大学毕业前便已经在华为诺亚方舟

新智元报道【新智元导读】华为诺亚方舟实验室主任王云鹤官宣离职。我们梳理了王云鹤的经历。王云鹤今日在朋友圈官宣,将辞去华为诺亚方舟实验室主任职位,告别华为。从 2025 年 3 月到今天,王云鹤恰好全面执掌了诺亚方舟实验室整整一年。华为诺亚方舟实验室,是华为乃至中国的 AI 研究重镇。其人其事王云鹤本科就读于西安电子科技大学数学与应用数学专业,毕业后进入北京大学智能科学系攻读博士学位,主攻深度学习、

智东西作者|陈骏达编辑|云鹏“一切都需要被重新思考,深度学习2.0时代即将来临。”在读完下方这篇来自月之暗面的最新论文后,前OpenAI大牛、“推理模型之父”Jerry Tworek发出感叹。智东西3月16日报道,今天,月之暗面发布论文,提前预览了下一代模型的关键模块——注意力残差(Attention Residuals,简称AttnRes)。论文的核心亮点在于对大模型中最基础、但长期被忽视的结构
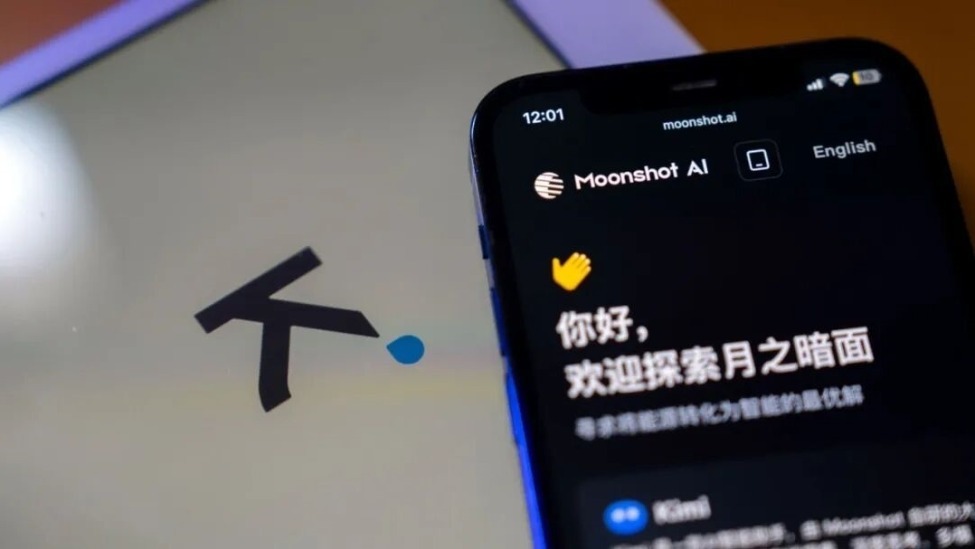
3月17日,Kimi官方账号回应了马斯克对其最新成果的点赞,表示“你的火箭也很不错”。最近,Kimi团队发布了一份技术报告,提出了一个创新性的Attention Residuals(注意力残差)机制,对深度学习领域内沿用多年的传统残差连接进行了彻底的革新,迅速吸引了全球的关注。传统的残差连接通过“固定等权累加”的方式传递信息,随着层数的增加,容易导致浅层信息被稀释,训练效率降低,稳定性减弱。而Ki

自2015年ResNet诞生以来,「将输入直接加到输出上」这一简单的机制,几乎统治了所有神经网络架构。近期,沿用了十年的残差机制迎来了重大变革,「注意力机制」成为了其替代方案。这一创新甚至影响到了OpenAI的研究人员,包括负责开发o1/o3系列、Codex编程模型及GPT-4 STEM能力的Jerry Tworek,他深受启发,认为需要重新评估现有的一切,「深度学习2.0」时代即将到来。这一突破
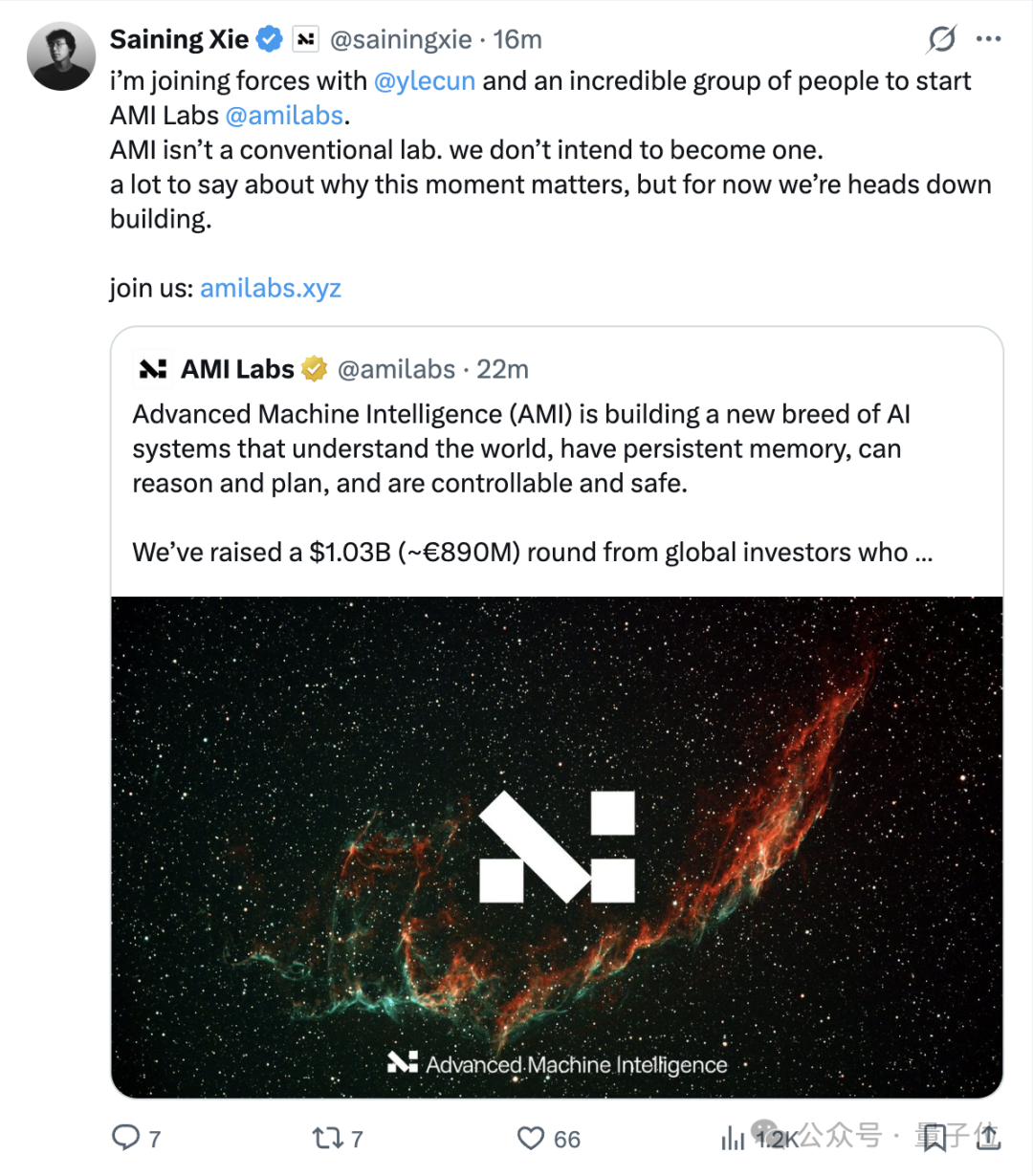
Yann LeCun(杨立昆)迎来了新的合作伙伴! 深度学习领域的重要人物之一,图灵奖得主Yann LeCun最近有了重大动作。 他主导成立的初创公司Advanced Machine Intelligence(AMI)—— 宣布已成功筹集10.3亿美元种子资金,并且在融资前估值已达35亿美元。 同时,纽约大学助理教授、DiT框架作者谢赛宁也加入了这一行列。他的个人主页已经更新为AMI的联合创始人兼

全球首个深度思考的扩散模型诞生! 它摒弃了传统的自回归模式,成为世界上生成速度最快的模型。 对比之下,传统自回归的“打字机式”输出方式(逐个token按顺序生成)就像乌龟一样慢: 实际测试结果显示,在英伟达GPU上运行的Mercury 2扩散推理大语言模型可实现每秒1009个tokens的速度。 这一速度比GPT-5(mini版)和Claude-4.5(haiku版本)等传统模型快了五倍之多

加拿大蒙特利尔深夜时分,被誉为“AI教父”之一的世界顶级计算机科学家约书亚·本吉奥(Yoshua Bengio)再次从梦中惊醒。月色宁静的窗外映入眼帘,但他的内心却波澜起伏,难以平静。这位他亲手培育成长的人工智能(AI),如今让他夜不能寐,心怀前所未有的忧虑。曾是图灵奖得主、学术巨擘,在看到自己研发的深度学习技术如