
今日,DeepSeek发布了其新一代旗舰模型体系——DeepSeek-V4系列的预览版本,并将其开源。这是继V3.2之后的新一代产品。
深渊寻神(DeepSeek V4)重归后引发热烈反响,在微博热搜榜上占据前三席位,仅次于小米YU7GT的表现。
此次发布包括两个模型:DeepSeek-V4-Pro和DeepSeek-V4-Flash。前者采用MoE架构,总参数规模达到1.6T(激活为49B),后者则为284B(激活为13B)。两者均支持最长至百万token的上下文长度。
据官方消息,由于高端算力资源有限,DeepSeek-V4-Pro目前的服务量相当受限。预计下半年昇腾950超节点批量上市后,价格将大幅下调。同时,该系列已经获得了寒武纪Day 0适配支持,并且相关代码已开源至GitHub社区。
DeepSeek-V4-Pro主打性能上限,直接对标市场上的闭源旗舰模型;而DeepSeek-V4-Flash则在参数规模和激活规模上有所缩减,以换取更低的延迟和成本优势。

相比于前一代产品,在代理能力、世界知识以及复杂推理任务方面都有显著提升。此外,“百万上下文”功能首次被作为默认设置开放使用。
在代理能力测试中,DeepSeek-V4-Pro表现出色,在Agentic Coding等评估项目上进入开源模型的第一梯队,并且其交付质量已接近Claude Opus 4.6非思考模式的表现水平,尽管在思考方面仍有一些差距。
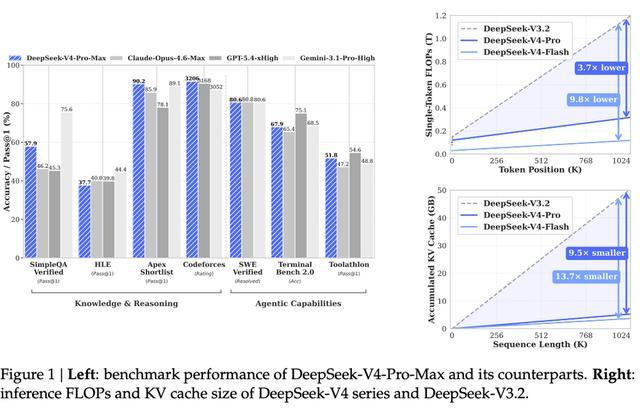
DeepSeek-V4-Pro在数学、STEM及竞赛型代码这些高难度任务中已经超过现有的公开评测中的开源模型,在整体性能上达到了顶级闭源模型如GPT-5.4和Claude Opus 4.6-Max的水平。
在处理长上下文效率方面,DeepSeek-V4提供了一套更为激进的优化方案:在100万token场景下,其单token推理计算量仅为V3.2的约四分之一,KV Cache占用也大幅减少至原来的十分之一左右,显著降低了长链路任务所需的算力和显存成本。
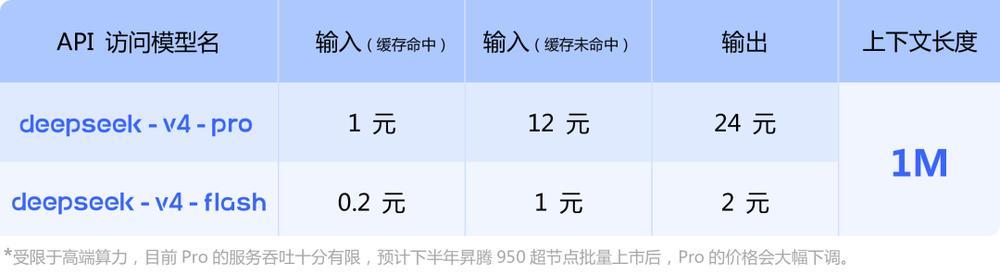
官方公布了DeepSeek-V4系列API的价格:对于DeepSeek-V4-Pro来说,在输入命中缓存的情况下为每百万tokens 1元,未命中的情况下则分别为12元和24元;而对于DeepSeek-V4-Flash,则在相同条件下分别定价为每百万tokens 0.2元、1元以及2元。
目前,DeepSeek-V4系列已经上线其官网及App,并开放了API和模型权重的访问权限。
用户可以通过网站chat.deepseek.com或DeepSeek官方应用程序体验这款新软件。
关于API的相关文档可以在https://api-docs.deepseek.com/zh-cn/guides/thinking_mode 查阅。
开源链接:
模型集合页面: https://huggingface.co/collections/deepseek-ai/deepseek-v4
其他相关链接包括 https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4 和 https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf。
技术报告:
在初步体验过程中,我们主要测试了DeepSeek-V4-Pro模型的表现。在前端网页单次案例中,该款软件的执行效率非常高。
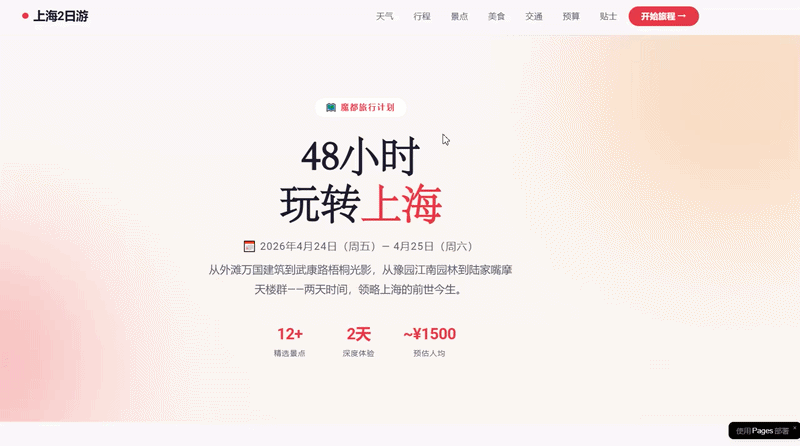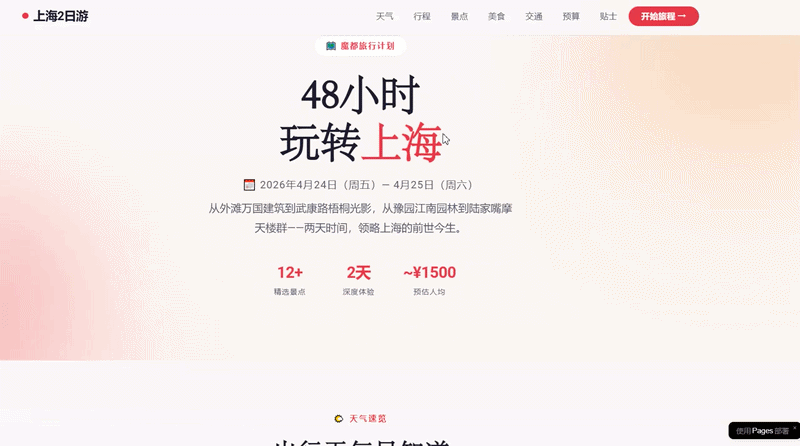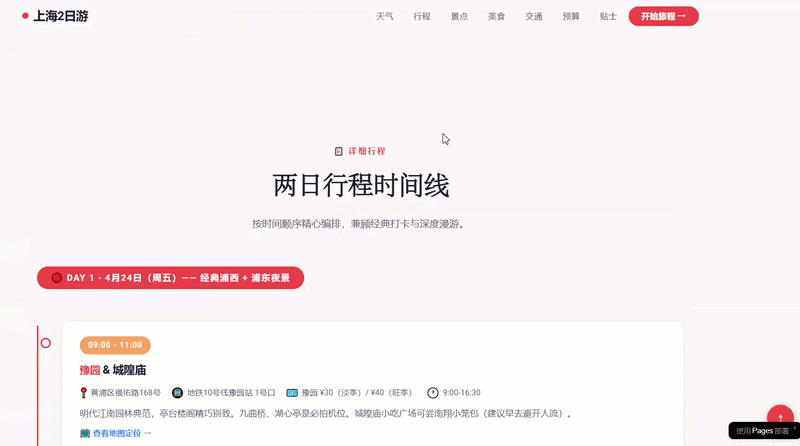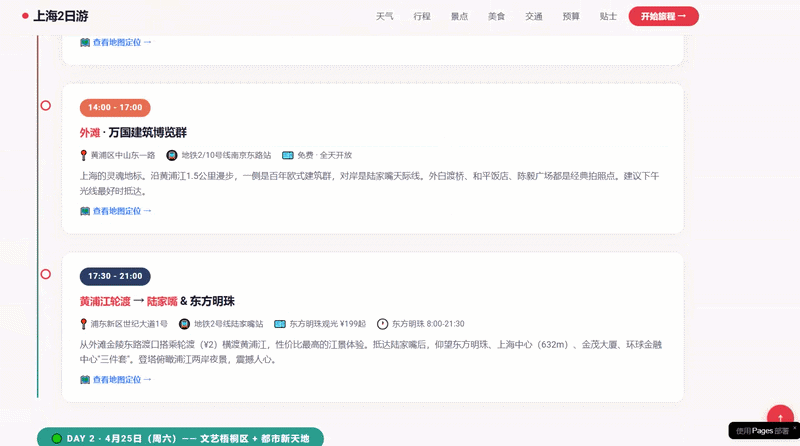
我们尝试了一个编程任务:规划一次上海之旅,并创建一个包含所有相关信息和景点定位的网站。结果表明,DeepSeek-V4-Pro能够高效地完成这项复杂多轮工具调用的任务。
最终生成的结果显示,这个网站的设计比之前的版本更为丰富和完善。
我们还进行了长文本处理测试,上传了《三体》整部小说。结果显示,DeepSeek可以在海量数据中迅速定位所需内容,并且可以处理超长时间的上下文任务,尽管这需要消耗大量的token。
通过提问“OpenAI更新到了哪个模型版本”,我们发现该软件的知识截止日期仍然停留在2025年。
目前DeepSeek-V4-Pro尚未支持视觉能力。上传图像后仅进行文字提取处理,无字文本将显示无法处理的提示信息。

这一代V4最显著的变化就是将其长上下文功能作为默认设置提供给用户。
为了实现这一目标,DeepSeek-V4-Pro采用了一种全新的混合注意力架构,结合了压缩稀疏注意机制和高压缩注意力技术,并使用DSA稀疏注意力在token维度进行数据压缩处理。同时引入流形约束超连接(mHC)增强传统残差链接,并通过Muon优化器提升模型的收敛速度及训练稳定性。
据官方数据显示,在百万级token上下文环境下,DeepSeek-V4-Pro的单token推理TFLOPs相比V3.2下降了约3.7至9.8倍区间。KV Cache占用也减少了大约9.5至13.7倍。
这意味着以前难以实际操作的大规模任务现在可以顺利执行,例如多轮代理规划或长文档处理等复杂场景。
DeepSeek-V4-Pro在推理、知识和代理能力三个方面均有明显提升。它在SimpleQA、Apex、Codeforces等多种测试中超越了主流开源模型,并且在一些评估项目上接近甚至超过了GPT-5.4与Gemini 3.1 Pro的性能表现。
在SWE Verified和Terminal Bench等代理能力相关的任务中,DeepSeek-V4-Pro也表现出色。其SWE Verified得分为80.6分,几乎达到了Claude Opus 4.6的成绩水平,远超多数开源模型的表现。
总体而言,DeepSeek-V4-Pro已经成为当前开源模型中的顶尖之作。
在这一代产品中,代理能力得到了专门优化。针对Claude Code、OpenClaw和CodeBuddy等主流代理框架进行了专项改进,在代码生成和文档创建等多个步骤任务上表现更加稳定。
实际应用表明,DeepSeek-V4-Pro已经可以作为内部Agentic Coding模型使用,重点在于完成具体任务。虽然V4-Flash在简单任务中已接近Pro版本的性能水平,但在复杂任务处理能力方面仍有一定差距。
从根本上讲,这为代理应用程序提供了两种不同的“计算档位”。DeepSeek-V4-Flash在执行简单的代理任务时已经能够与Pro版相媲美,但面对复杂的任务依旧存在明显差异。这种区别主要体现在推理深度和上下文利用能力的不同上。

DeepSeek-V4的亮相不仅展示了团队的技术积淀和架构创新,还标志着开源大模型在中国本土算力环境下的实际落地能力已经得到验证。
经过对华为昇腾、寒武纪等国产芯片的适配优化,DeepSeek-V4系列实现了百万token上下文的支持以及高效推理性能,使长链路任务与多步代理执行成为可能。
这一版本通过具体应用将Pro和Flash的不同定位落实,在性能上接近闭源旗舰模型的同时保持了较高的性价比优势。为国内开发者提供了前所未有的开放选项。
更重要的是,这次发布证明开源模型不仅能在全球竞争中占据有利位置,还能借助本土算力资源与优化架构,将技术潜力转化为实际的生产力。DeepSeek-V4或许是国产开源力量在高性能AI赛道上的关键一步,并为国内AI生态创新和落地提供了明确指引。
此外,模型引入了流形约束超连接(mHC)增强传统残差连接,并使用Muon优化器提升收敛速度和训练稳定性。这一系列设计,使得模型在“记得更长”的同时,有效控制计算成本。
从官方给出的数据来看,在100万token上下文下,DeepSeek-V4-Pro单token推理TFLOPs相比DeepSeek-V3.2下降约3.7倍至9.8倍区间,KV Cache占用下降9.5倍至13.7倍。
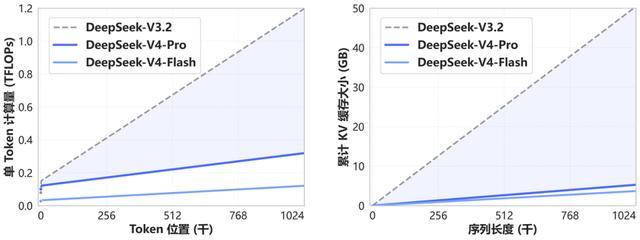
这意味着,过去难以实际运行的超长链路任务(如多轮Agent规划、长文档处理),开始进入可执行范围。
三、推理、知识、代码三线抬升,开源模型逼近闭源上限
从能力结构来看,DeepSeek-V4-Pro的提升是推理、知识与Agent能力的同步抬升。
在知识与推理类任务中,其在SimpleQA、Apex、Codeforces等评测中均超过当前主流开源模型,并在多项任务上接近GPT-5.4与Gemini 3.1 Pro。例如在Apex Shortlist中达到90.2分,已经超越顶级闭源模型;在Codeforces等竞赛类任务中,也维持在第一梯队水平。
在Agent能力相关任务中,DeepSeek-V4-Pro在SWE Verified、Terminal Bench等指标上表现稳定,SWE Verified达到80.6,接近Claude Opus 4.6,明显高于多数开源模型。其表现同样超过GLM-5.1 Thinking、Kimi K2.6 Thinking等模型
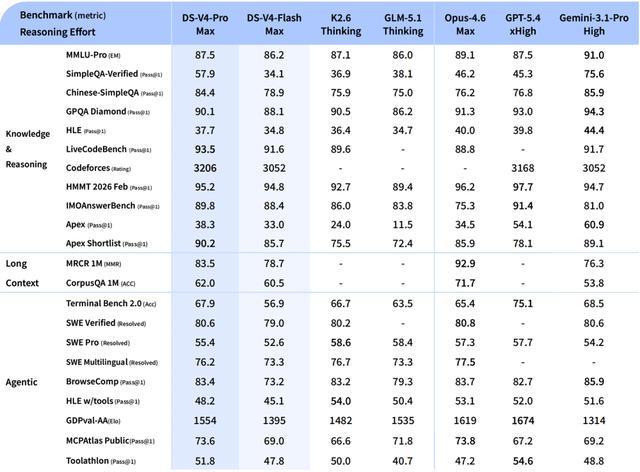
整体来看,DeepSeek-V4-Pro已是目前开源模型的“天花板”。
四、Agent能力专项优化,开始围绕真实工作流打磨
这一代DeepSeek-V4明显强化了对Agent场景的适配。其针对Claude Code、OpenClaw、CodeBuddy等主流Agent框架进行了专项优化,在代码生成、文档生成等多步骤任务中表现更稳定。下图为DeepSeek-V4-Pro在某 Agent框架下生成的PPT内页示例:
从实际定位来看,DeepSeek-V4-Pro已经被DeepSeek内部作为Agentic Coding模型使用,侧重点在于“完成任务”。在简单任务上,V4-Flash已可与Pro版本接近,而在复杂任务中仍存在明显差距。
本质上是在为Agent应用提供两种“算力档位”。DeepSeek-V4-Flash在简单Agent任务中已经能够与Pro“旗鼓相当”,但在复杂任务中仍有差距。这种差异,本质上是推理深度与上下文利用能力的差别。
结语:DeepSeek-V4亮相,国产算力与开源路线的落地之光
DeepSeek-V4的发布不仅展现了团队在技术和架构上的积淀,也标志着开源大模型在国产算力生态下的实际落地能力。
经过对华为昇腾、寒武纪等国产芯片的适配优化,DeepSeek-V4系列实现了百万token上下文的稳定支持和高效推理,使长链路任务与多步Agent执行成为可能。
这一版本将Pro与Flash的不同定位落到实处,在性能上逼近闭源旗舰模型,在成本上保持高性价比,为国内开发者提供了前所未有的开放选项。
更重要的是,这次发布显示出开源模型不仅能在全球竞争中站稳脚跟,也能够借助国产算力和优化架构,将技术潜力转化为实际可用的生产力。DeepSeek-V4或许是中国开源力量在高性能AI赛道上迈出的关键一步,也为国内AI生态的创新和落地提供了明确指引。