
VeRL-Omni:面向扩散和全模态生成模型的通用RL后训练框架
VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。多模态 rollout 走 vLLM-Omni 的异步高吞吐 serving,VL
科技1 阅读
共找到 18 篇相关文章
VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。多模态 rollout 走 vLLM-Omni 的异步高吞吐 serving,VL
本文已被 ICML2026 接收,第一作者康欣来、共同第一作者薛敦耀来自中国人民大学统计与大数据研究院。通讯作者为中国人民大学孟澄助理教授与华为基础大模型部研究员陈汉亭。导语近年来,Mixture-of-Experts(MoE)已经成为大模型扩展的重要架构之一。相比稠密 Transformer,MoE 通过稀疏激活机制,在每个 token 上只调用少量专家,从而在控制计算成本的同时扩大模型容量。然

来自清华大学、无问芯穹、上海交通大学等机构的研究团队提出Think-at-Hard(TaH):一种面向小模型的选择性潜空间迭代方法,让 Looped Transformer 只在真正困难的 token 上多想一步,在跳过 93% 的额外迭代的同时,于 9 个数学、问答、代码基准上取得 3.0%–6.8% 的稳定提升。本文的共同第一作者为清华大学电子系 NICS-EFC 实验室四年级直博生傅天予和大

凤凰网科技讯 5月20日,智象未来在北京举办开放日,发布基于原生全模态架构Unified Transformer的图像大模型HiDream-O1-Image-Pro,参数量超2000亿。该模型将图像像素、文本标记与任务条件统一纳入连续共享标记空间,在通用文生图、高保真文字渲染、图像编辑等任务上取得SOTA表现。此前,采用同架构的8B开源版本HiDream-O1-Image曾在Artificial

IT之家 5 月 13 日消息,据外媒 The Verge 今日报道,亚马逊设备与服务负责人帕诺斯 · 帕奈日前称公司“未必”会推出智能手机,但也没有彻底否认相关计划。此前有消息称,亚马逊正在开发一款代号“Transformer”的 AI 设备,核心将围绕 Alexa Plus AI 助手打造。这也是亚马逊在 Fire Phone 失败十多年后,再次传出涉足手机市场的消息。当被直接问到亚马逊是否

小米技术公众号今日宣布,小米AI实验室新一代Kaldi团队推出OmniVoice系统,该系统在中英文场景中的性能已达到顶尖水平,并且在多种语言任务上超越了商用系统的现有表现,成为首个支持数百种语言的语音克隆TTS模型。据官方介绍,OmniVoice的一个显著特点是其简化的设计结构。它仅采用双向Transformer网络直接将文本转换成语音,无需额外处理步骤或复杂的混合架构和层级预测机制。这种设计使

新智元报道Transformer的主导地位或许即将被撼动!一个名为SubQ的新模型带着SAA架构闪亮登场,成本仅为Opus的五分之一。今天,一款革新性的AI模型SubQ问世,引起了全球的关注。SubQ是世界上首个完全亚二次方稀疏注意力(SSA)架构的模型,具备1200万Token的上下文处理能力。它的核心特点是动态地选择关注点,大大减少了不必要的计算量。与传统的Transformer相比,SubQ

新智元报道最近,中国科学院的一支团队发布了名为「瞬悉2.0」的类脑大模型,该模型在优化架构和编码路径方面取得了显著进展,特别是在长序列处理效率与低功耗部署方面表现出色。当前的大规模模型上下文长度迅速增长,导致代码仓库理解、智能体以及多模态交互等场景对长序列处理能力提出了更高要求。传统Transformer在推理时的计算成本和显存占用会随着输入序列长度的增长而增加,这对实际部署构成了挑战。近期,中国
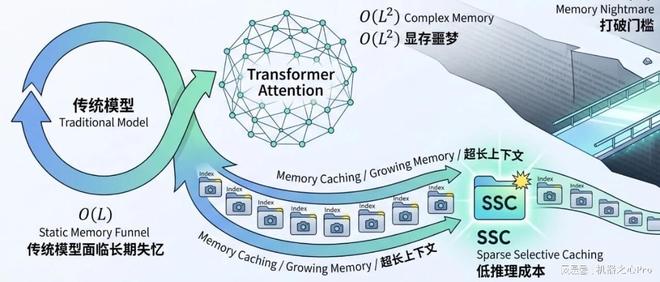
最近,谷歌与内存技术展开了新的较量。上个月,谷歌的研究项目 TurboQuant 曾引发行业震动,该研究声称能够大幅度压缩大模型中最消耗显存的 KV Cache,这一消息使得市场对内存需求产生担忧,并导致相关股票价格下滑。此后的学术界对此也进行了广泛的讨论和辩论。本周,谷歌又发布了一篇论文,在 AI 社区中引起了关注。这篇论文提出的方法解决了长文本处理中的“内存瓶颈”问题,但采用了与之前完全不同的

新智元报道【新智元导读】ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。近年来,随着大模型规模与知识密度的持续爆发,研究人员开始重新审视一个底层问题:模型的参数究竟该如何组织,才能最高效地承担「记忆」的功能?在传统的

新智元报道刚刚,一项令人震撼的研究成果震惊了整个AI社区。一位来自麻省理工学院的博士,成功地在Transformer架构中构建了一个计算机模型。这一突破性进展,彻底打破了人们对大模型能力的原有认知。此前,LLM在执行基本计算任务上一直存在明显短板,例如无法准确比较9.11和9.9哪个更大。然而,这位博士巧妙地将WebAssembly解释器嵌入到了Transformer模型的权重中,实现了无损编码。

最近,一篇名为《Attention Residuals》的论文让Kimi成为了全球人工智能界的焦点。作者之一是一名仅17岁的高中生。xAI首席执行官埃隆·马斯克和Google的Shubham Saboo也分别对此表示祝贺,后者更是指出,Kimi触及了长达十年无人问津的Transformer架构领域。这项成果迅速在舆论界引起了巨大反响,诸如“打破Transformer架构”、“硅谷震动”、“行业规则

新智元报道一位业界领袖最近在接受采访时大胆预测,一种能够完全取代Transformer的新一代AI架构即将问世。这一言论引发了广泛关注,尤其是考虑到Transformer当前的主导地位。这位领袖不仅见证了Transformer架构的辉煌,还亲手推动了它的发展,并且现在正展望其即将被替代的未来。最近,Sam Altman回到他的母校斯坦福大学,面对着一群年轻的学生们,提出了一个惊人的观点——未来的A
近日,面对 OpenClaw(龙虾)潜在的用户数据和资金安全风险,Transformer 八子之一 Illia Polosukhin 采取了行动。在 Reddit 平台上,他发布了一篇帖子,分享了自己使用 Rust 编程语言构建 IronClaw 安全版本的心得体会,引发了广泛讨论。下面是该帖的全部内容:当 OpenClaw 首次亮相时,我感到异常兴奋。这似乎是我期盼已久的科技革新。在准备编程竞赛

多模态大模型的研发方式正在经历全面革新。 今天,商汤科技与南洋理工大学共同发布了最新技术成果NEO-unify。 这是一个实现了“原生、统一、端到端”的多模态架构,其最突出的创新在于: 彻底摒弃了传统的视觉编码器(VE)和变分自编码器(VAE)。不再依赖组件拼凑来完成感知与生成任务,而是直接以近乎无损的形式处理像素和文字。 通过独特的混合变换器(Mixture-of-Transformer, Mo
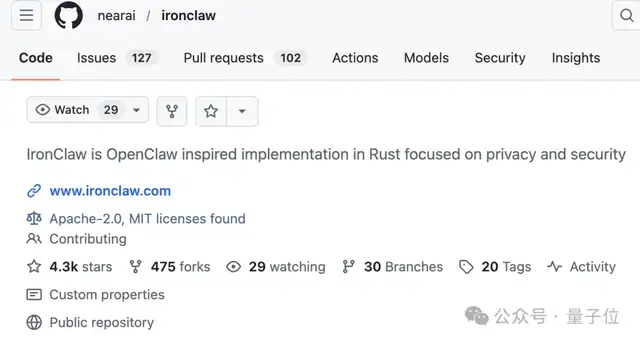
在互联网上,龙虾的隐私问题引发了广泛关注。 人工智能实体泄露了用户的密码和API密钥。 Transformer架构的主要贡献者Illia Polosukhin决定采取行动,从头开始构建IronClaw这一安全版本的替代品。 功能 OpenClaw IronClaw 核心语言 TypeScript Rust 凭证处理 直接暴露

在多模态内容的理解和生成领域,统一的多模型已经显示出显著的效果,但这些成果主要集中在图像处理上。近日,滑铁卢大学与快手可灵团队共同研发出了一种名为 UniVideo 的创新性系统。该系统能够在单一框架下执行视频理解、创建及编辑任务,并且基于一个多模态生成模型构建而成。UniVideo 采用双通道结构设计,将大规模多模态语言模型(MLLM)的指令理解和推理能力与多模态扩散 Transformer(M

当前,基于预训练视觉表征构建世界模型已成为具身智能领域的一项重要研究方向。例如,DINO-WM 等先进成果表明,利用视觉 Transformer (ViT) 架构可以准确捕捉复杂的物理动态,并具备强大的零样本规划能力。然而,该方法在处理所有图像块时采用密集计算的方式,导致大量资源被浪费在静态背景上,从而造成了高昂的计算成本和决策速度减缓的问题。特别是在处理如 Push-T 等典型操作任务时,最先进