最近,谷歌与内存技术展开了新的较量。
上个月,谷歌的研究项目 TurboQuant 曾引发行业震动,该研究声称能够大幅度压缩大模型中最消耗显存的 KV Cache,这一消息使得市场对内存需求产生担忧,并导致相关股票价格下滑。此后的学术界对此也进行了广泛的讨论和辩论。
本周,谷歌又发布了一篇论文,在 AI 社区中引起了关注。这篇论文提出的方法解决了长文本处理中的“内存瓶颈”问题,但采用了与之前完全不同的技术路径来实现这一目标。
研究者们开辟了一个新的方向,通过创新大模型的架构机制,为 RNN 设计了可扩展的记忆容量,从而找到了一种结合 Transformer 和 RNN 优点的新方法。
这种新方法使 AI 能够处理更长的文本,并解锁“超长上下文”的能力。同时,它大大降低了推理所需的资源门槛。
各方都表示欢迎这一创新:大模型的实际应用迫切需要这种突破性技术。

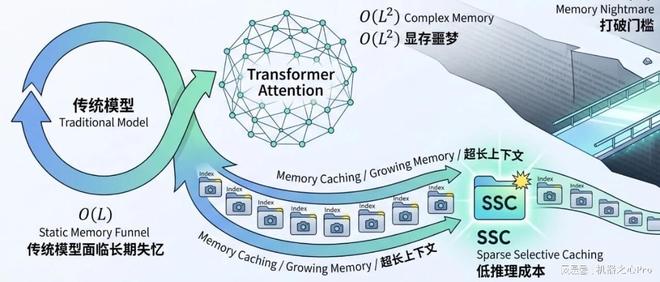
当前的大规模模型大多基于 Transformer 架构设计,因其可以扩展的记忆容量(其计算和空间复杂度随上下文长度呈二次幂增长),在处理长上下文的信息检索方面表现出色。这正是它占据主导地位的原因之一。
然而,这种复杂的计算需求也带来了严重的算力和显存瓶颈,使得处理超长文本的成本变得非常高昂。
为了克服这一挑战,社区一直在尝试复兴 RNN、线性注意力模型以及状态空间模型等方法。这些循环架构的优势在于它们具有固定的记忆容量(复杂度低),推理速度快且占用较少的显存。但是,由于必须将所有过去的信息压缩到一个固定的隐藏状态中,这导致了信息丢失的问题。
这种“信息漏斗”效应使得他们在执行密集检索任务时的表现往往不如 Transformer。
为此,谷歌的研究团队提出了一项名为 Memory Caching(MC)的新技术,据称这种方法简单且有效。

- 论文名称:《Memory Caching: RNNs with Growing Memory》
- 论文地址:https://arxiv.org/abs/2602.24281
在这项研究的视角中,存在一个架构光谱:一端是 Transformer(无压缩,Token 级缓存),另一端则是传统的 RNN(全压缩,单一记忆)。而“记忆缓存”则开辟了介于两者之间的新途径:将成组 Token 压缩并存储到长期记忆状态中,然后在需要时进行检索。
Transformer 会为每个单独的标记创建一个缓存,而 RNN 则依赖一个固定大小的记忆,并把上下文中的所有信息压缩进这个固定的参数空间。那么,如果我们也能够将 RNN 的历史记忆存储起来会怎样?
简单来说,与其让 RNN 仅维持一种不断更新的“当前状态”,不如定期对其进行“快照”处理(Caching checkpoints)。这样,在进行信息检索时,模型不仅可以查看当下的在线记忆,还能直接调用缓存中的历史记录,迅速找回过去的相关数据。
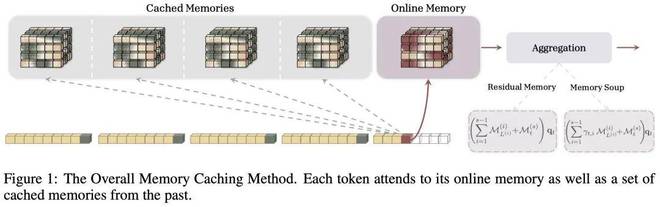
在研究过程中,作为概念验证,研究人员提出了三种变体来组合过去的记忆信息:
1、门控残差内存(Gated Residual Memory):该方法通过查询从过去检索相关信息,并执行类似注意力机制的池化操作。实际上,RNN 的记忆容量在增长,因此解码成本也在增加。
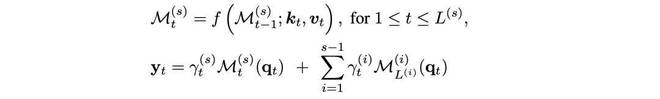
2、记忆汤(Memory Soup):这是另一种结合过去记忆的方法,它直接将过去的记忆权重合并进来,而不是针对特定查询进行输出。在这种情况下,需要对过去的记忆权重重做一次类似注意力机制的池化操作,并执行检索。同样,这种变体相对于上下文长度具有不断增长的有效记忆容量,因此解码成本也在增加。
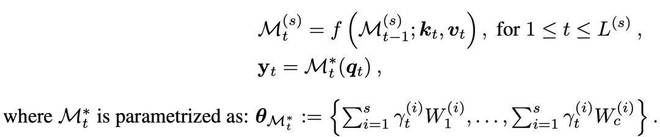
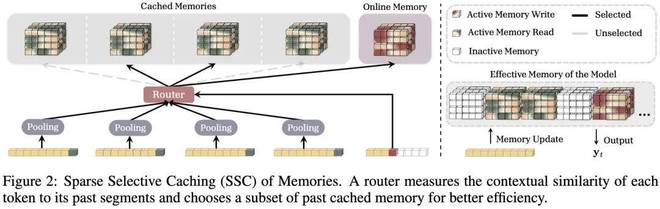
3、稀疏选择性缓存(Sparse Selective Caching,SSC):到目前为止,似乎没有免费午餐,需要在不断增加的记忆有效性和每 token 恒定的解码成本之间做出权衡。
因此作者提出了 SSC 这一方案。这是一种类似于 MoBA 的专家混合模型,在序列维度上稀疏地选择过去缓存记忆的一个子集,从而引出一个有效容量在增长但每 token 解码成本保持相对恒定的模型。
那么效果如何呢?
该方法可以作为一种通用框架被应用于各种现有的循环架构中,例如线性注意力模型或之前的深度内存模型 Titans 等。
实验结果表明了其强大的效果:
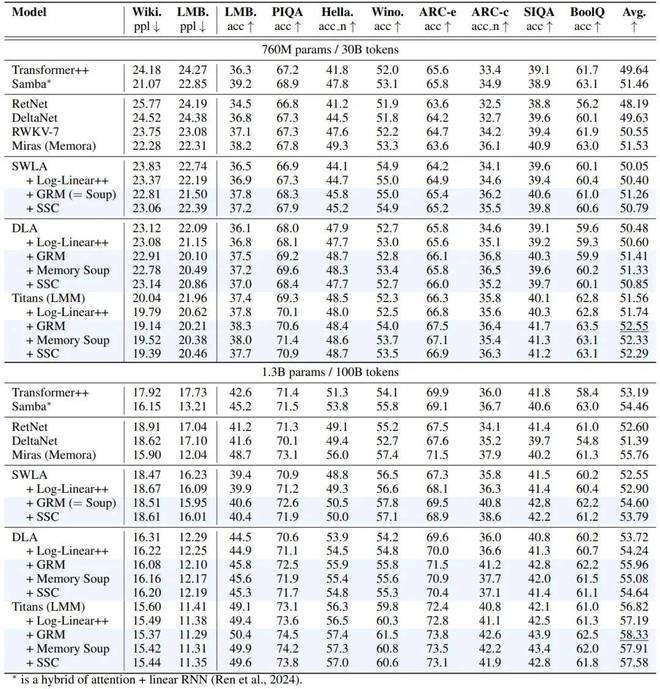
在语言建模和常识推理任务上展现了出色的性能。
研究人员在 13 亿参数的模型上进行了多项实验,包括语言建模、密集检索、长上下文理解和 needle-in-a-haystack 类型的任务。结果显示 MC 相较于基础模型有了显著改进。具体来说:
- 在处理长上下文的能力方面有所提升:在语言建模和理解超长上下文的测试中,采用了 MC 机制的循环模型性能得到了全面提升。
- 减少了与 Transformer 的差距:在最具挑战性的“上下文中检索(in-context recall)”任务上,加入了 MC 的模型击败了其他最先进的循环模型。
- 尽管如此,在极限的密集检索任务中,它依然未能彻底超越 Transformer 在准确性方面的最佳表现。
总体来说,这项研究通过一种极其优雅的方式解决了长期存在的理论难题,使得非 Transformer 架构在实用性上有了重大进步。
虽然目前在纯粹的密集召回方面,它尚未完全超过 Transformer 的性能上限,但新道路已经铺就。随着 RNN、SSM 等架构的持续发展与完善,Transformer 一家独大的局面可能会有所改变?