
在多模态内容的理解和生成领域,统一的多模型已经显示出显著的效果,但这些成果主要集中在图像处理上。
近日,滑铁卢大学与快手可灵团队共同研发出了一种名为 UniVideo 的创新性系统。该系统能够在单一框架下执行视频理解、创建及编辑任务,并且基于一个多模态生成模型构建而成。
UniVideo 采用双通道结构设计,将大规模多模态语言模型(MLLM)的指令理解和推理能力与多模态扩散 Transformer(MM-DiT)高质量视觉内容生成功能结合在一起。这种方法超越了以往依赖于特定任务设定或单一模式的传统方法,在多个基准测试中展现了接近甚至超过现有最佳性能的表现。
更为关键的是,UniVideo 能够在没有额外特定任务设计的情况下推广至未遇到的任务及新的组合任务情境之中。这表明视频生成与编辑不再需要拆分为独立的模型模块,统一建模本身就具备更高的灵活性和扩展性。
目前这项工作已被 ICLR 2026 接收,并且项目代码已对外开放。

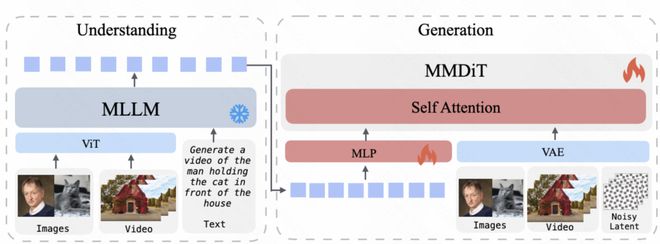
- UniVideo 的核心构成包括多模态大语言模型(MLLM)与多模态扩散 Transformer(MM-DiT)。前者负责跨多种模式的指令理解及语义推理,后者专注于在潜在空间中进行条件图像或视频建模。
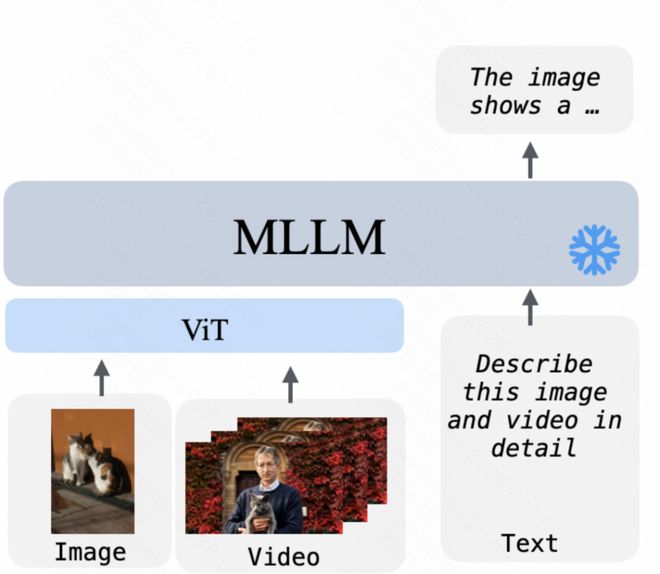
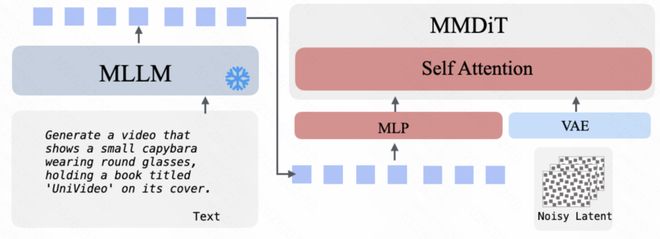
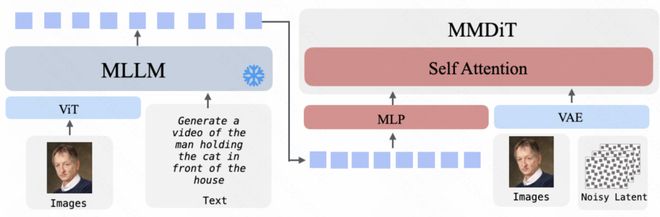
- 在处理多模态指令时,UniVideo 的 MLLM 能够接受文本、图片和视频等不同类型的数据,并生成高层次的语义表示或相应的文本反馈。而 MM-DiT 则致力于高质量视觉内容的创建。
- UniVideo 通过从多模态大语言模型的最后一层提取语义特征并利用可训练 MLP 连接器进行对齐,将其注入到 MM-DiT 的理解流中,以实现高层次的条件建模。同时,图像信息经过 VAE 编码后被输入至 MM-DiT 的生成流中,确保了视觉细节的有效保留。
- 双通道架构设计不仅具备强大的语义基础,还能够进行高保真的视觉重建,这对视频编辑以及需要保持身份一致性的上下文生成任务尤为重要。
效果展示

模型架构
UniVideo 统一并优化了十种多模态的任务类型
- 该系统通过统一的多模态指令框架及 MLLM 加上 MM-DiT 的双通道架构实现了灵活的任务调度和内容生成功能。
- 多模态理解任务(如从图像或视频转换为文本)可以直接由 MLLM 完成,并输出相应的文本描述。
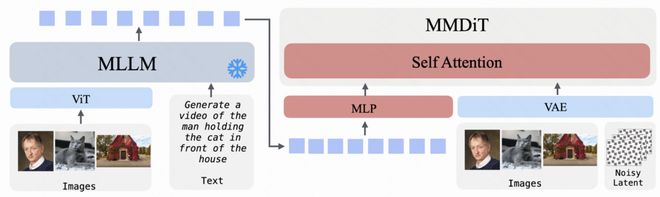
文本到视觉内容的转换(即根据文本指令生成图像或视频),则通过 MLLM 将文本编码为语义表示,再作为条件输入指导 MM-DiT 生成所需的图片或视频素材。
图像至视频的转化过程中,MLLM 负责综合理解输入图像和附加文本说明,并提供语义条件;与此同时,视觉信息与视频潜在变量共同作用于 MM-DiT 的生成过程之中。
对于图像或视频编辑任务(即在现有内容基础上进行修改),UniVideo 会首先通过 MLLM 解析用户提供的编辑指令,然后利用 MM-DiT 在保持原内容结构的同时完成条件编辑操作。
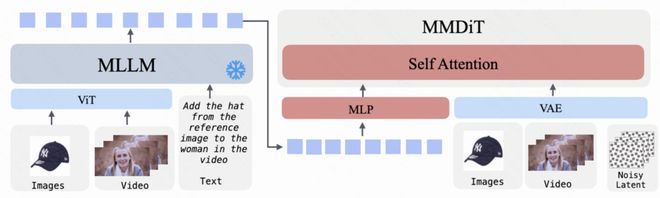
在多身份上下文生成与编辑场景下,所有视觉信号都会被统一编码并填充至标准形状后沿时间维度拼接起来,并经过自注意力机制融合以支持连续性任务的执行。
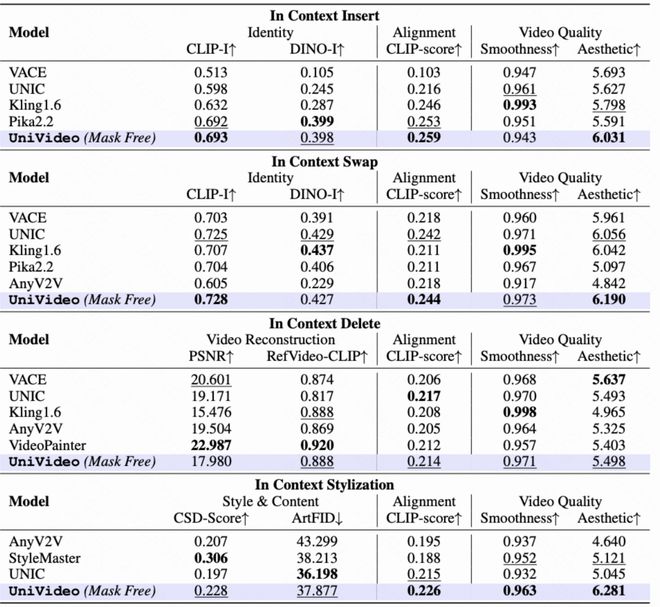
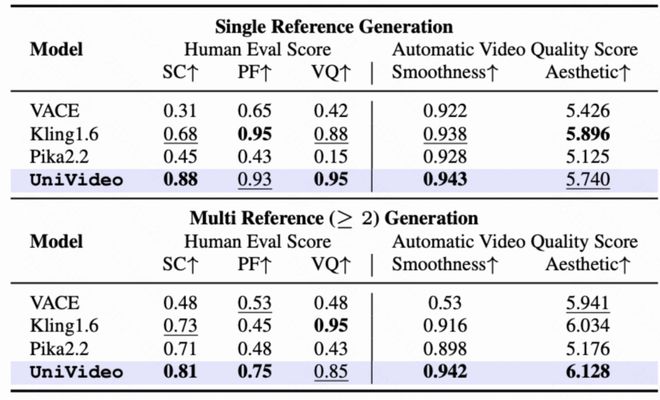
- 实验结果显示,在多种定量评估指标上,UniVideo 超过了专门针对特定任务设计的传统基线方法,并在大多数测试条件下达到了或超过了当前最佳水平(SoTA)。
下图展示了 UniVideo 在多身份上下文生成与编辑方面的定量性能对比情况。
- 关键见解:统一架构具备强大的泛化能力
研究团队从两个角度验证了 UniVideo 统一框架下的泛化特性:
- (1)对未见过的视频编辑指令的适应性;
即使在没有接触过自由形式视频编辑命令数据的情况下,UniVideo 依然成功地将图像编辑技能迁移到视频领域,并展示了对这类新指令的有效响应能力。
- (2)对于新型任务组合的应用推广;
在训练阶段并未明确包含相关组合任务的条件下,UniVideo 能够自然扩展至新的任务组合设置中,并展现了统一多模态框架在组合泛化方面的重要优势。
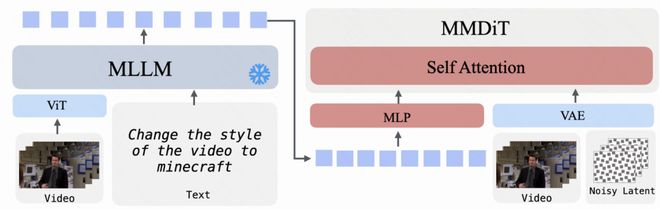
- 下图提供了 UniVideo 泛化到视频风格转换及环境编辑任务的具体例子:
通过使用统一的多模态指令范式和双通道架构,UniVideo 实现了视频理解、创建与编辑等多功能任务的一体化建模。实验结果表明,在多个定量评估中,UniVideo 超过了专门针对单一任务优化的传统方法,并且在大部分设置条件下达到了或超过了当前最佳水平。
实验结果
更为重要的是,UniVideo 有能力应对未见过的视频编辑指令和新的组合任务类型。这说明统一多模态建模不仅具有可行性,而且可能是一条更具扩展性的未来发展方向。
魏聪是本文的第一作者,并且他正在滑铁卢大学攻读博士三年级,指导老师为陈文虎教授。
Key Insight:统一模型具备良好的泛化能力
团队从两个方面验证了 UniVideo 统一架构的泛化能力:
(1)对未见视频编辑指令的泛化能力:
尽管 UniVideo 未在 free-form 视频编辑指令数据上进行训练,但通过联合多任务训练,模型成功将图像编辑能力迁移至视频领域,实现了对 free-form 视频编辑指令的泛化。
(2)对新任务组合的泛化能力:
即使在训练阶段未显式包含相关任务组合,UniVideo 仍能够自然泛化到新的任务组合设置,展现出统一多模态框架在组合泛化方面的显著优势。
下图给出了 UniVideo 泛化到视频风格化与环境编辑任务的定性示例:

总结
UniVideo 通过统一的多模态指令范式与双流架构,实现了视频理解、生成与编辑任务的统一建模。实验结果表明,UniVideo 在多项定量评测中优于任务特定的单任务方法,并在多数设置下达到或超过当前最优水平。
更重要的是,UniVideo 可泛化到未见过的视频编辑指令和新的任务组合。这表明,统一多模态建模不仅可行,而且可能是一条更具扩展性的方向。
作者介绍
本文第一作者魏聪,滑铁卢大学博士三年级在读,导师为陈文虎教授。
- 个人主页:https://congwei1230.github.io/