
新智元报道
刚刚,一项令人震撼的研究成果震惊了整个AI社区。
一位来自麻省理工学院的博士,成功地在Transformer架构中构建了一个计算机模型。
这一突破性进展,彻底打破了人们对大模型能力的原有认知。
此前,LLM在执行基本计算任务上一直存在明显短板,例如无法准确比较9.11和9.9哪个更大。
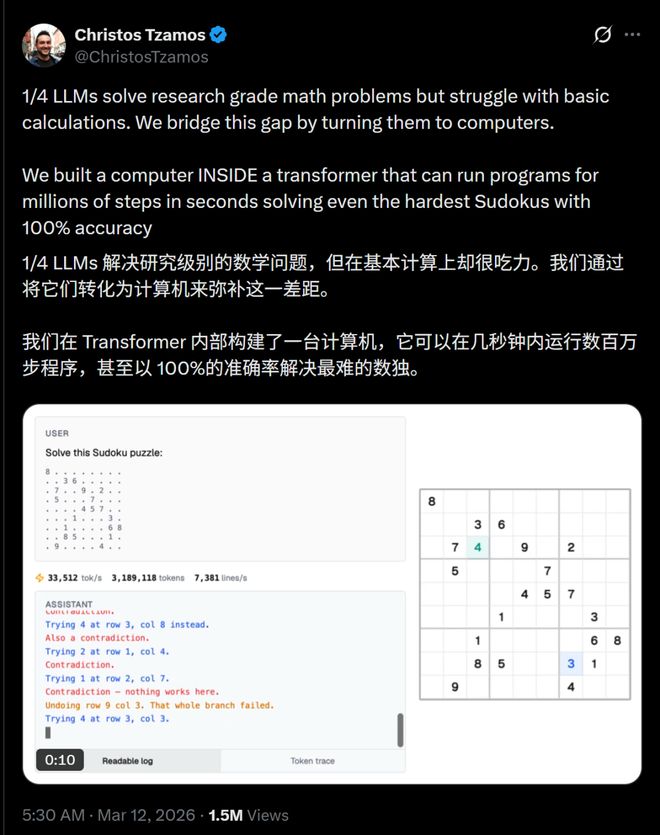
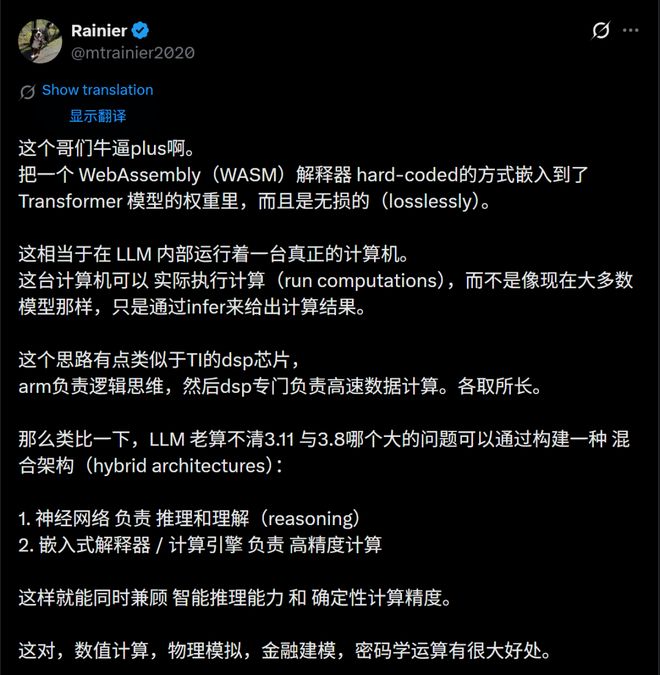
然而,这位博士巧妙地将WebAssembly解释器嵌入到了Transformer模型的权重中,实现了无损编码。
这项创新意味着,LLM不再仅仅是基于概率的文本生成机器,而是进化成为了一台真正的数字计算机。
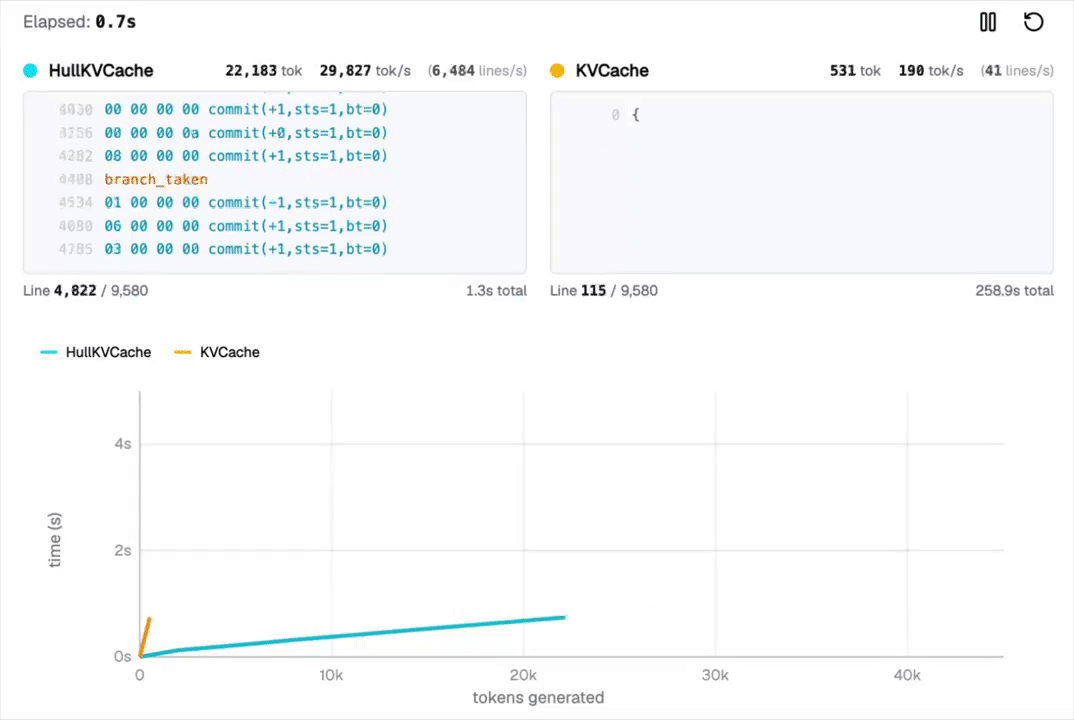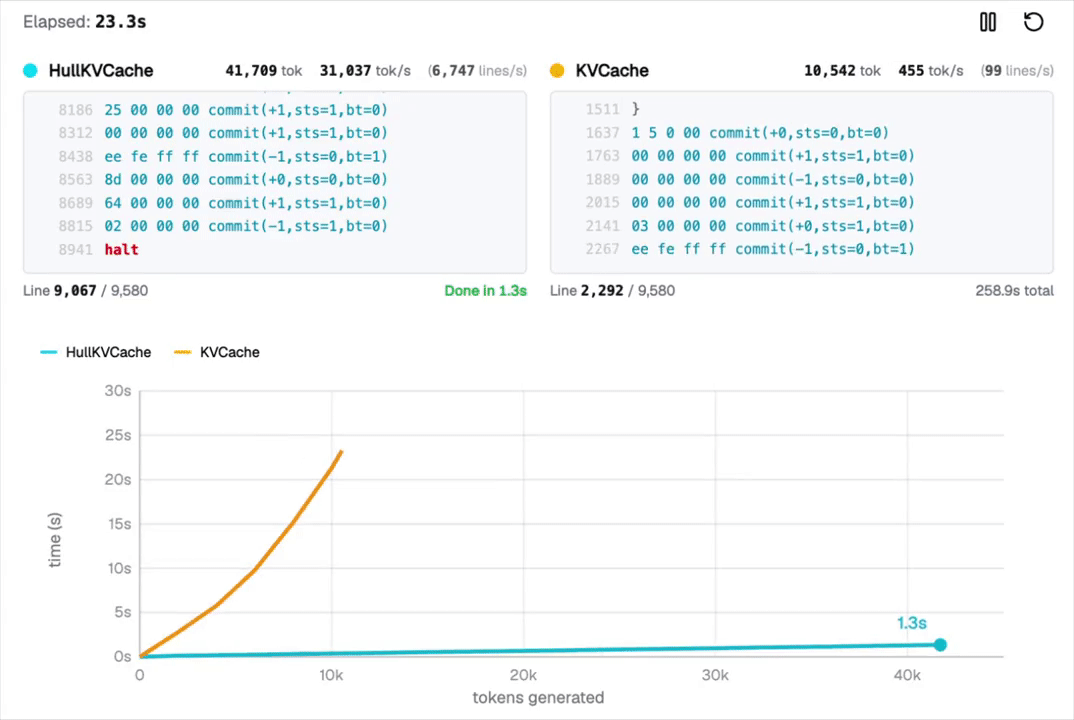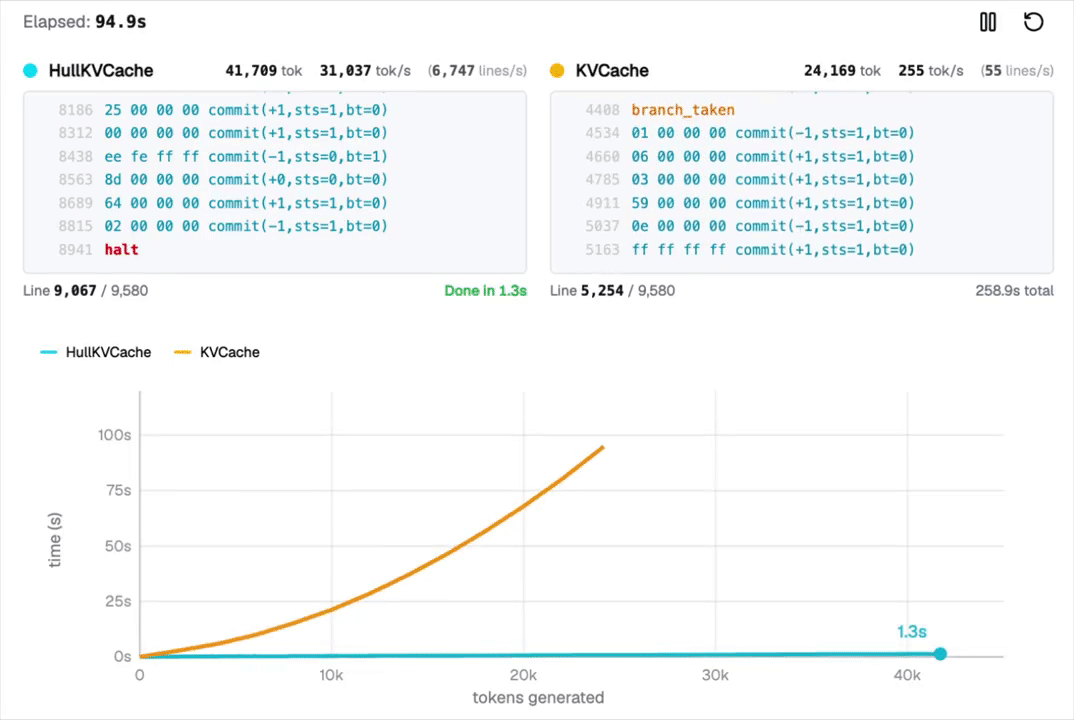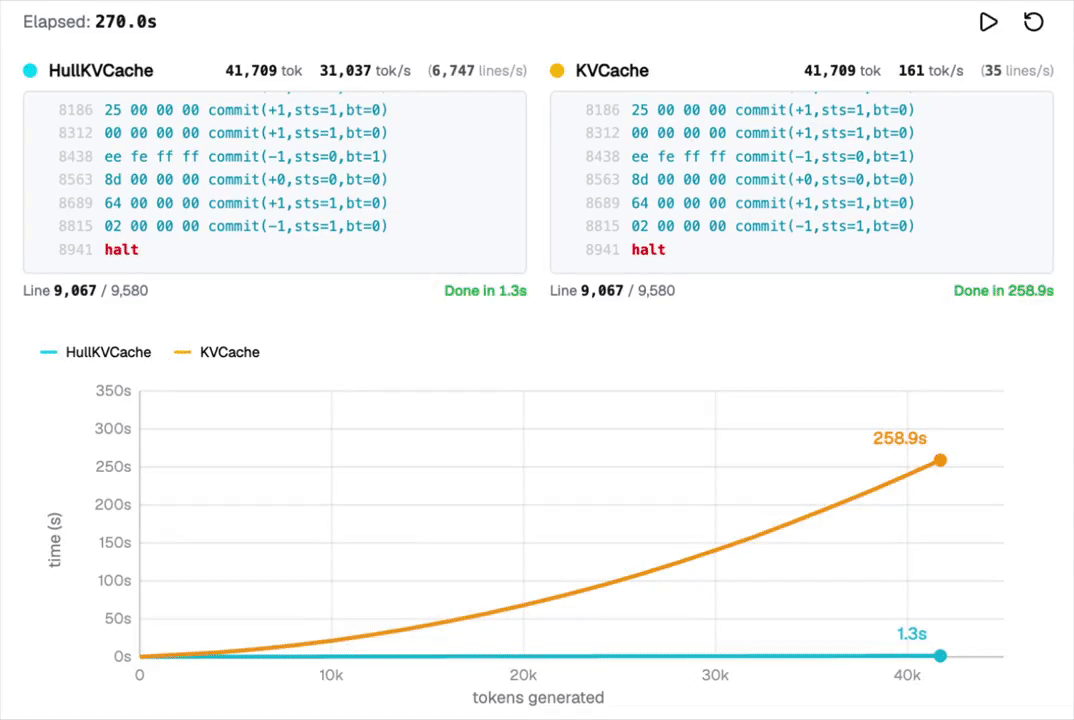
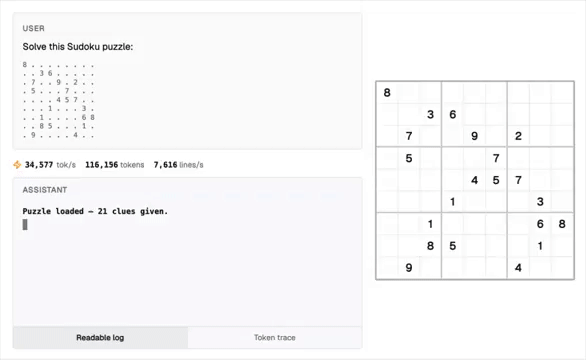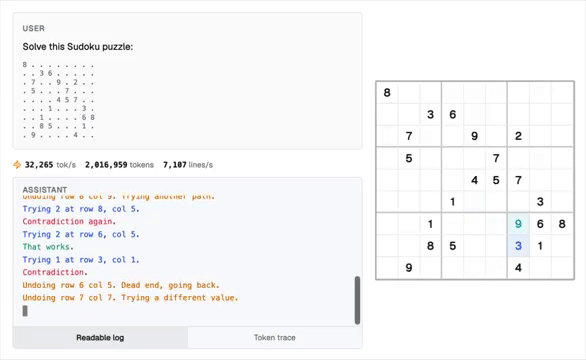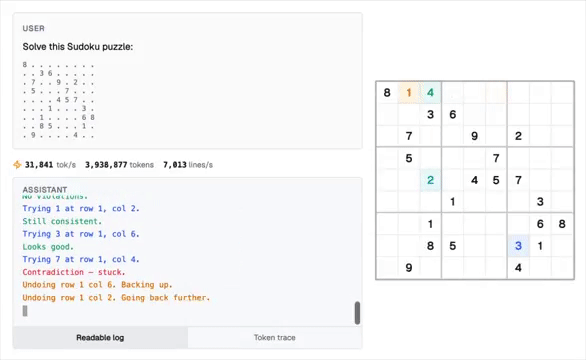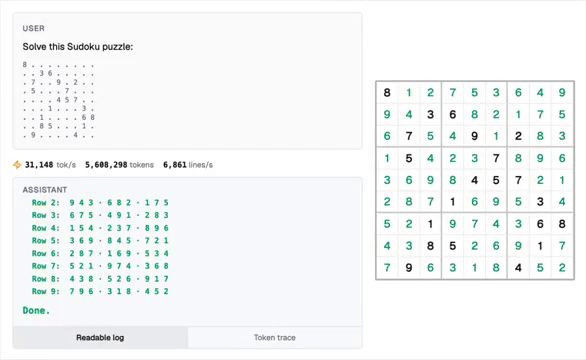
现在,LLM能够几秒钟内完成数百万步的复杂程序运算,甚至在解决数独问题上达到了100%的准确率。
这一成果迅速引起了众多开发者的高度关注和热烈讨论。
值得一提的是,这项研究彻底颠覆了人们对大模型在计算任务上的固有偏见。
AI领域的大牛Karpathy对此表示惊叹,称这一研究令人深受启发。

通过这种方法,LLM的计算能力得到了显著提升。
在过去,尽管大模型能够解决复杂的科研问题,但在进行基本的数学运算时却显得力不从心。
如何让大模型在执行计算任务时更加可靠和高效,成为了研究的重点。
为此,雅典大学的副教授Christos Tzamos和他的团队,将任意C代码转化为智元,使得模型能够直接运行程序。
他们采用了一种高效的计算路径,大幅提升了Transformer的处理速度。

在短短几秒内,模型便完成了数百万步的程序运算,这在以前是难以想象的。
虽然LLM的计算速度无法与CPU媲美,但这项技术的关键在于赋予了LLM内在的计算能力,使其更智能化。
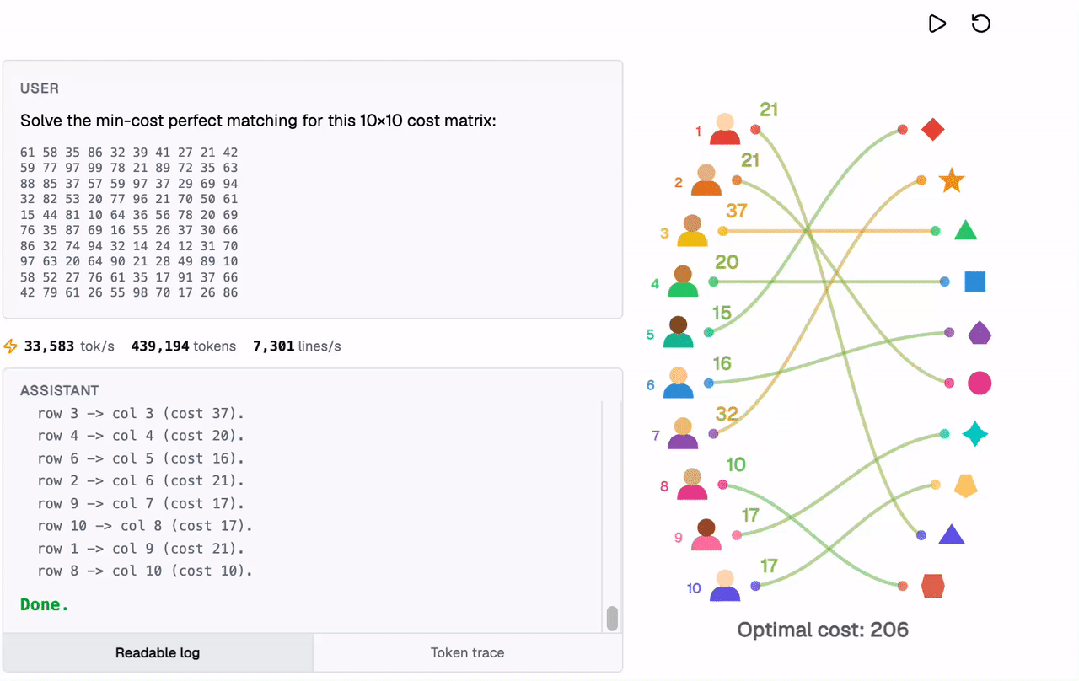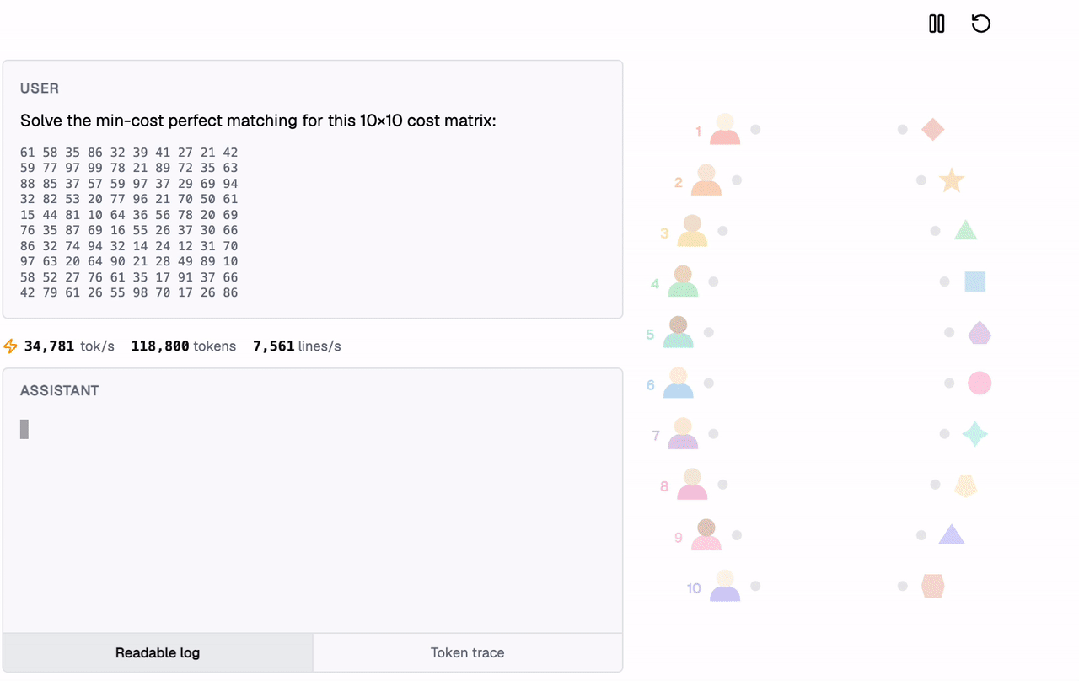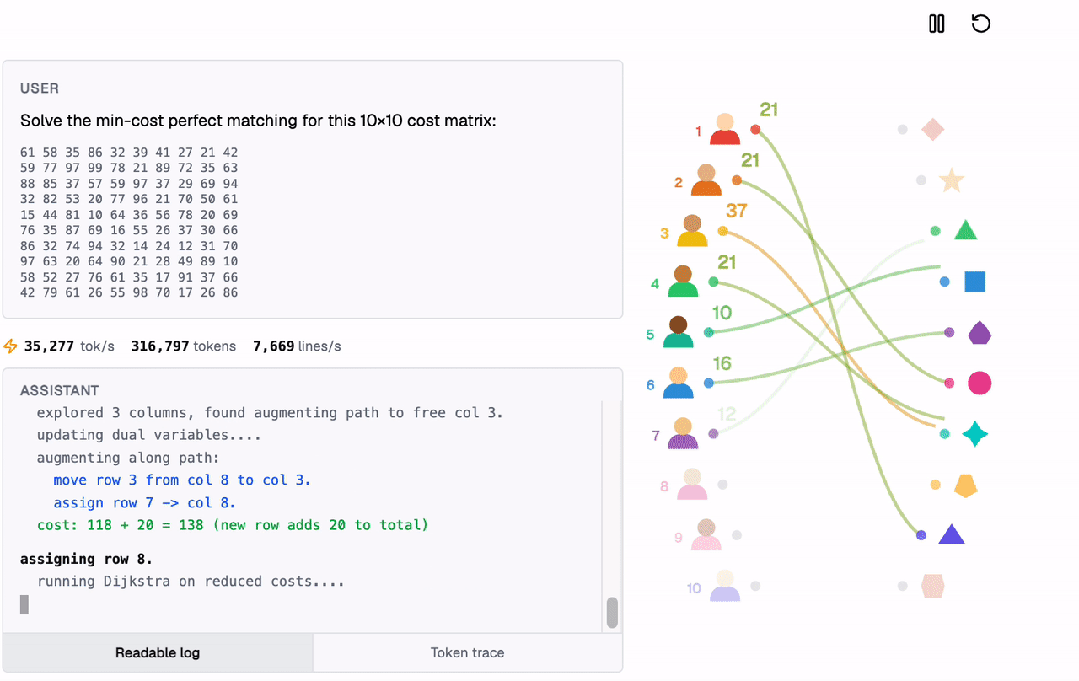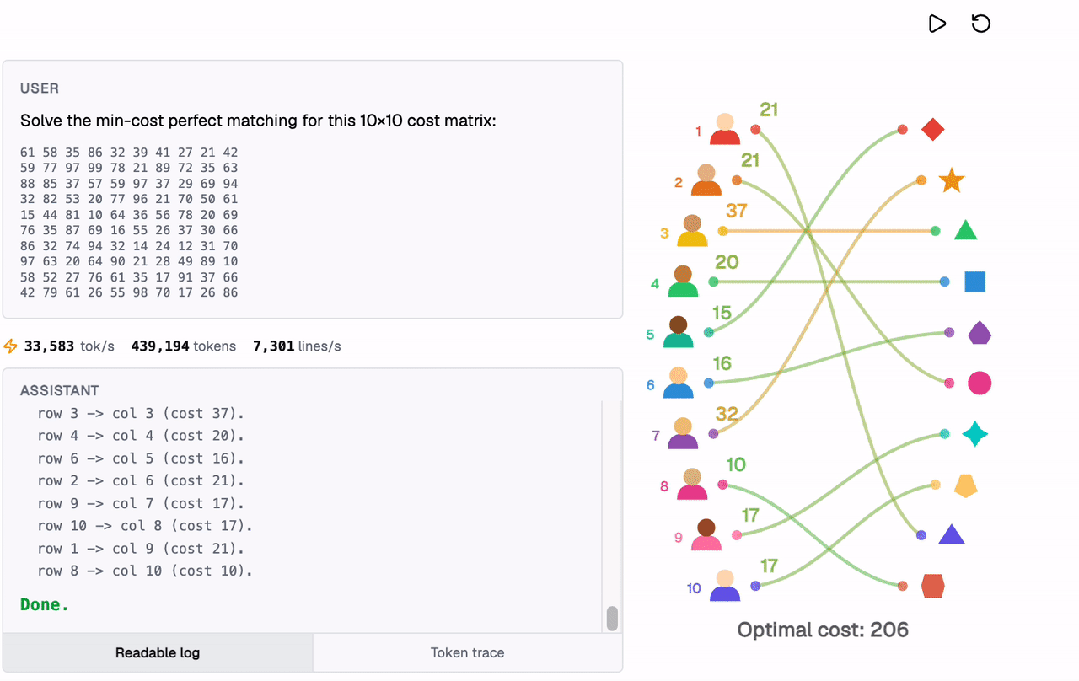
这种内在计算能力的提升,为未来的AI应用开辟了广阔的空间。
网友们纷纷赞叹,称这是真正的原生智能。
此前,人们普遍认为Transformer不适合进行计算,但这一研究打破了这一传统观念。
过去,每当展示大模型的强大推理能力时,总会有人问及9.11和9.9哪个更大,这成了每个AI项目不可避免的尴尬时刻。
这种问题之所以困扰AI,是因为Transformer模型最初设计是用来理解和生成自然语言,而非进行精确计算。
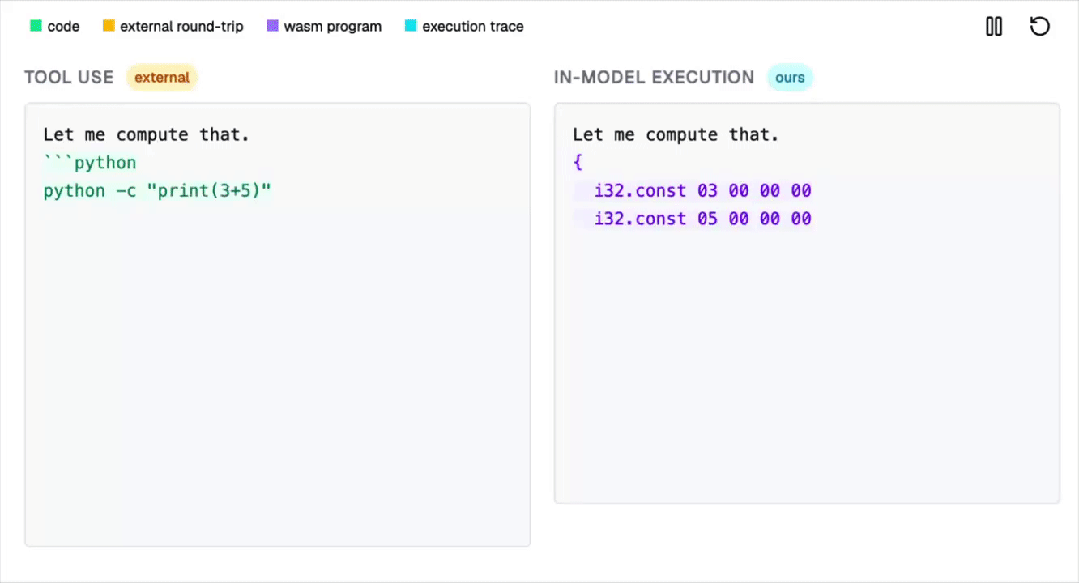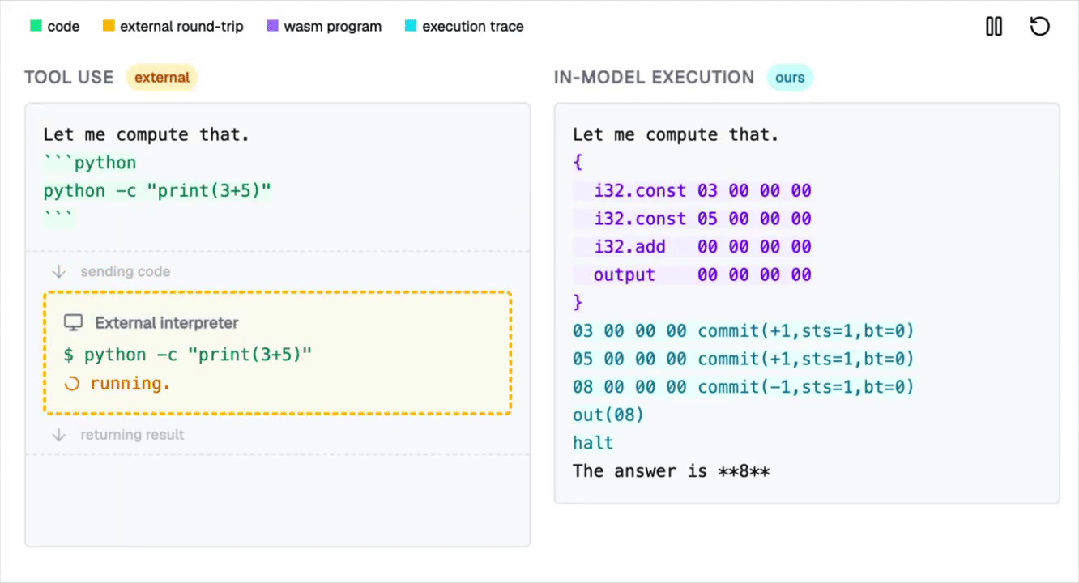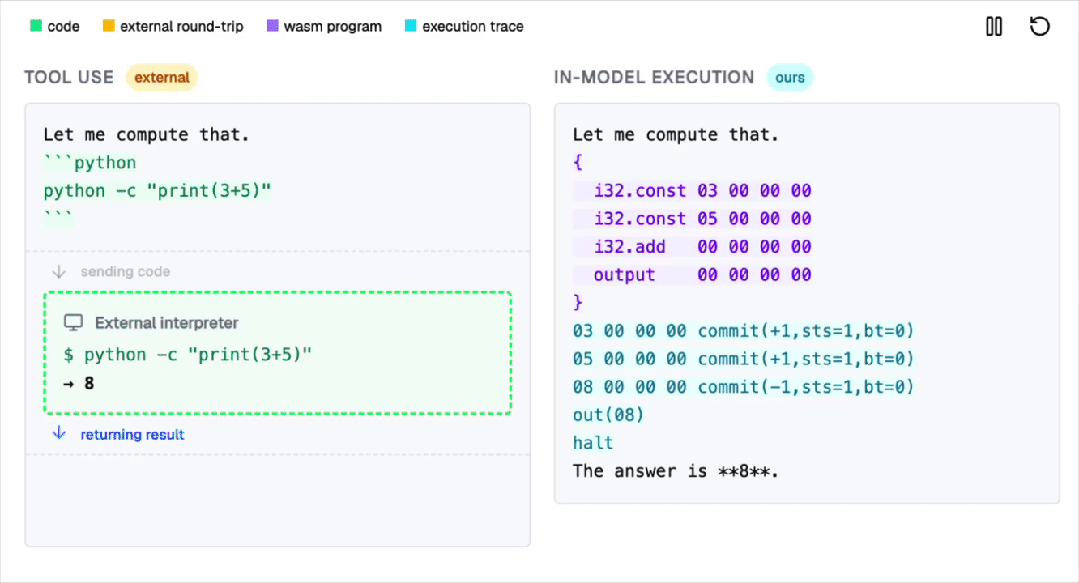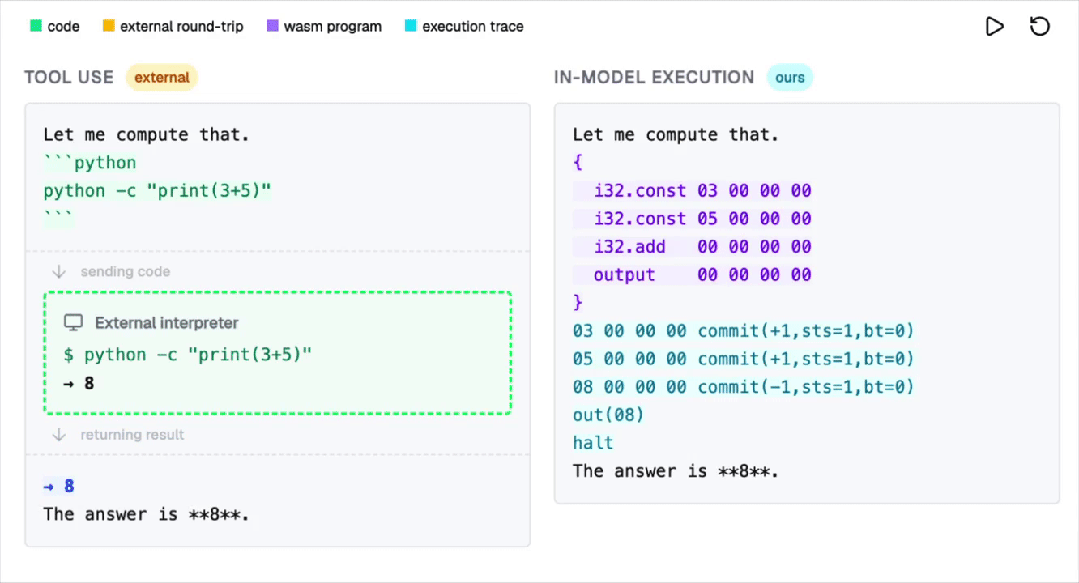
为解决这一难题,AI行业曾尝试通过调用外部工具的方式来弥补这一缺陷。
然而,这种方法不仅不够优雅,还可能引入额外的安全风险。
此次,麻省理工学院的博士团队提出了一个全新的解决方案:直接在Transformer内部构建一个完整的WebAssembly虚拟机。
这意味着,神经网络的前向传播过程本身就等同于执行计算机程序。
可以退出历史舞台?
通过这种方式,AI终于解决了长久以来困扰其发展的计算能力瓶颈。
传统Attention机制在进行计算时效率较低,而这项研究则直接推动了Transformer架构的革新。
这一突破性的进展,意味着AI不再需要借助外力来完成计算任务,而是能够自主执行复杂的计算程序。
未来,这种混合架构有望在数值计算、物理模拟、金融建模和密码学运算等多个领域引发革命性变化。
AI工程师Aviraj指出,虽然Percepta的方法非常出色,但他们的方法更加侧重于解决特定问题。
Percepta团队采用了一种专门为特定任务设计的极简指令集,而不是依赖于通用编译产物。
这种创新方法让Transformer能够在内部运行完整的计算机程序,从而彻底改变了AI的能力边界。
理解Transformer如何执行计算的一个重要视角,是将其视为一个不断增长的笔记本。
每一步计算都记录在新的一页上,一旦记录,之前的页面就不能更改。
这种只增不减的轨迹,与自回归Transformer的工作方式非常相似。
在这种模型中,每一个新的智元都是基于前面的少量位置生成的。
三年了。

这种方法使得许多算法都能够被表示成只增不减的轨迹,每一步只需要读取少量先前的位置。
在Christos Tzamos的系统中,AI模型生成的智元代表了虚拟机的动态状态,包括指令指针、内存、栈操作、算术运算和控制流。
AI模型通过回看相关的先前步骤来重构当前状态,实现了高效的计算路径。

虽然Transformer能够表示这种执行轨迹,但随着轨迹的增长,标准解码过程的成本会越来越高。
为解决这一问题,Christos Tzamos团队提出了一种快速解码路径,显著提高了计算效率。
总之,这项研究的价值在于将计算能力直接嵌入到LLM中,使其成为一个由推理系统和计算引擎组成的混合体。
这种进步为未来的AI发展指明了一个新的方向。

未来的AI将不再仅仅是概率模型,而是更加智能和高效的系统。
这一突破可能预示着下一代AI技术的真正发展方向。
他们把一台完整的WebAssembly虚拟机,硬编码进了Transformer的权重里。
也就是说,神经网络的前向传播过程本身,就等价于执行一台计算机。
过去AI的耻辱,如今终结了。
不过,但就数独问题而言,这不是LLM第一次突破。
工程师Aviraj认为Percepta的方法很酷,但他们采取了不同的、更面向具体问题的路径。
核心区别在于:不将通用编译产物(如C->WASM)作为模型的学习目标,而是为特定任务设计一个极简的、领域专用的指令集(PSVM)。

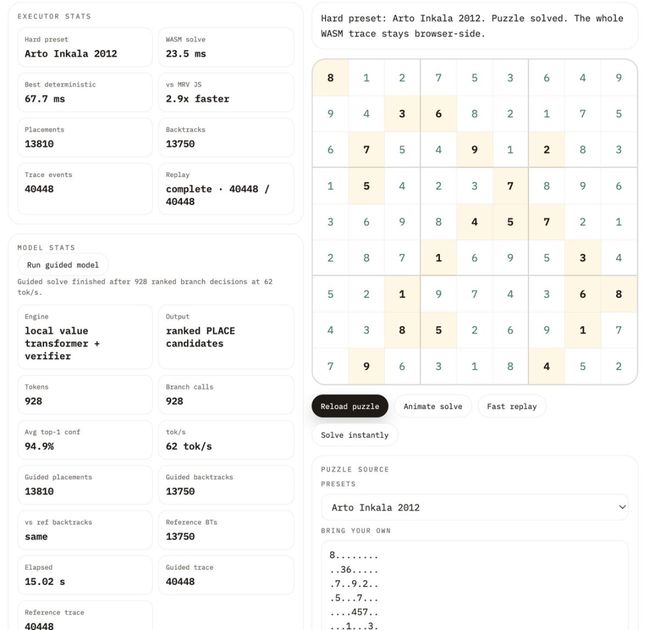
不过,这次看看Christos Tzamos团队如何在Transformer内部跑起来一台电脑的。
这个过程的关键,就是找到一种方法,来编码一台可工作的计算机。
计算:一条只增不减的轨迹
要理解Transformer如何在内部执行程序,不妨用一种稍微不同的方式来思考计算。
想象一个笔记本,计算的每一步都写在下一行。一旦写下,前面的行就不能更改;笔记本只会越来越厚。
这惊人地接近自回归Transformer的工作方式:提示词是输入,生成的智元形成不断增长的轨迹,每个新智元都是通过注意力机制回看少量位置后产生的。
比如,给定一个句子,统计其中动词的数量是奇数还是偶数。每个轨迹智元恰好关注两个位置:对应的输入词(检查它是否是动词)和前一个轨迹智元(读取当前的奇偶状态)。
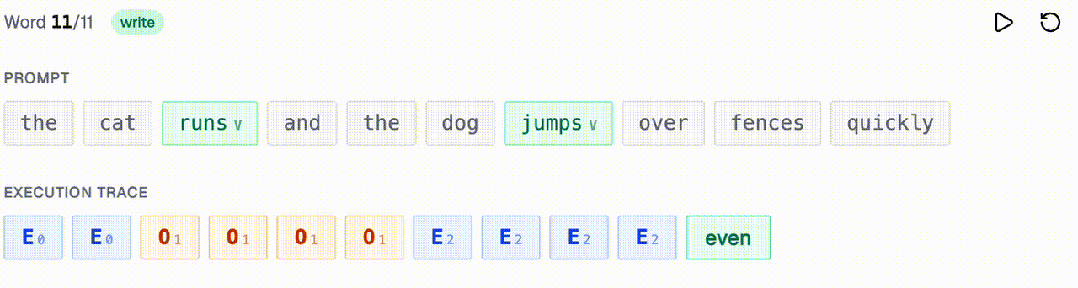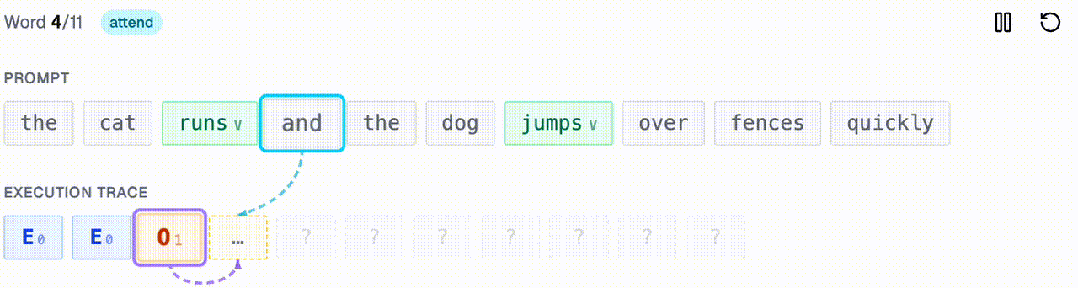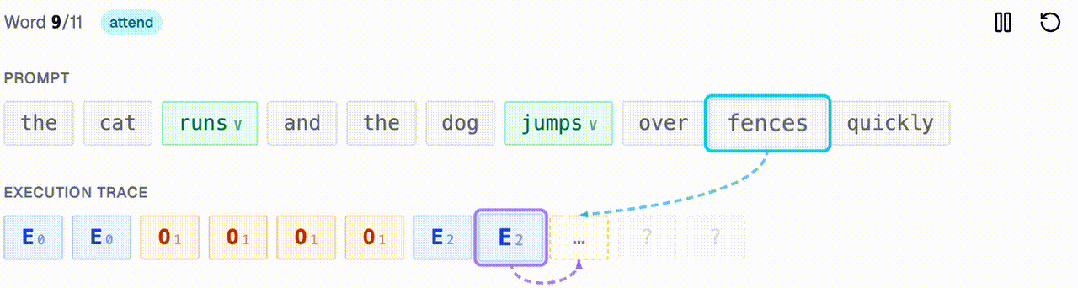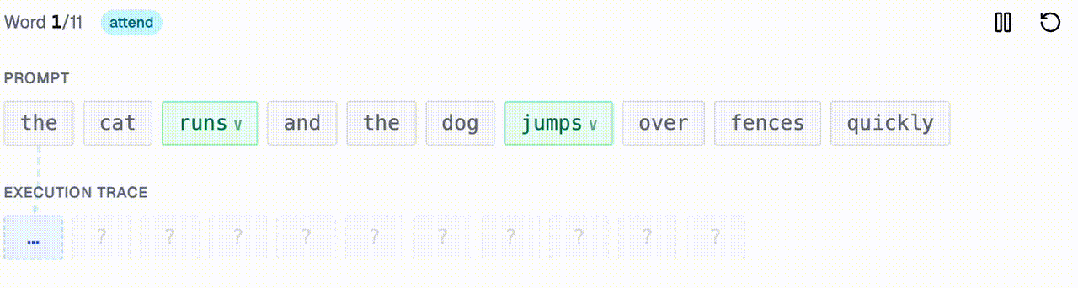
请注意,无论句子有多长,每一步都只需要两次回看(一次看提示词,一次看轨迹)。
这正是其中的核心洞察:许多算法都可以表示成这种只增不减的轨迹,每一步只需读取少量、固定数量的先前位置。
那么,计算能否被表示成一条只增不减的轨迹,且每一步只需回看少量次数呢?
答案是肯定的。
在Christos Tzamos的系统中,AI模型明确地生成了这样的轨迹。
它生成的智元代表了一个虚拟机的动态状态:指令指针、内存和栈操作、算术运算、控制流以及输出。
AI只需通过回看相关的先前步骤,就能重构出当前状态。
这几乎就是图灵机!
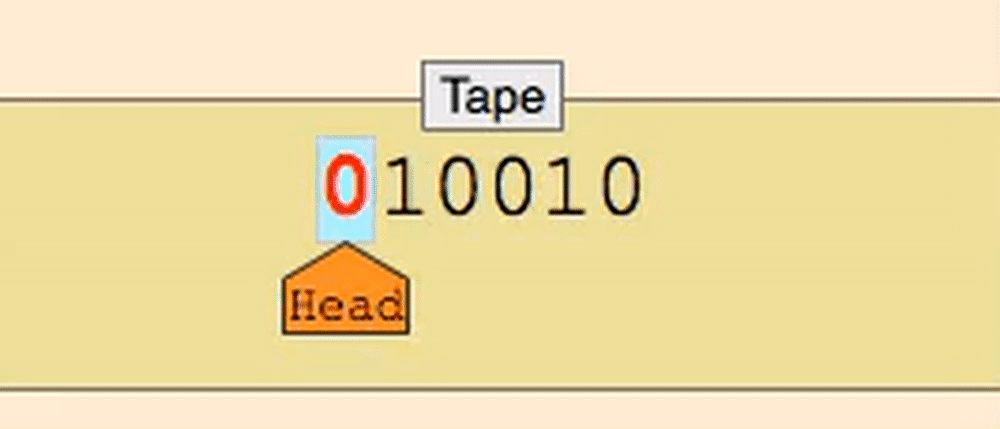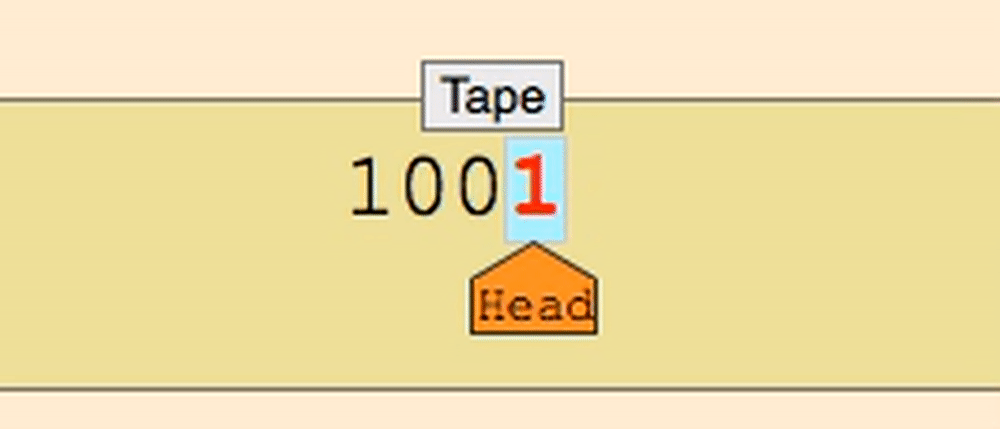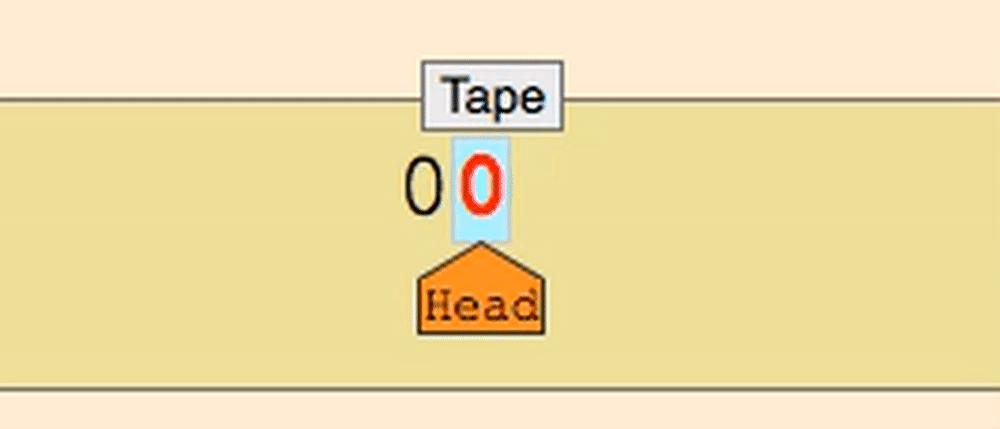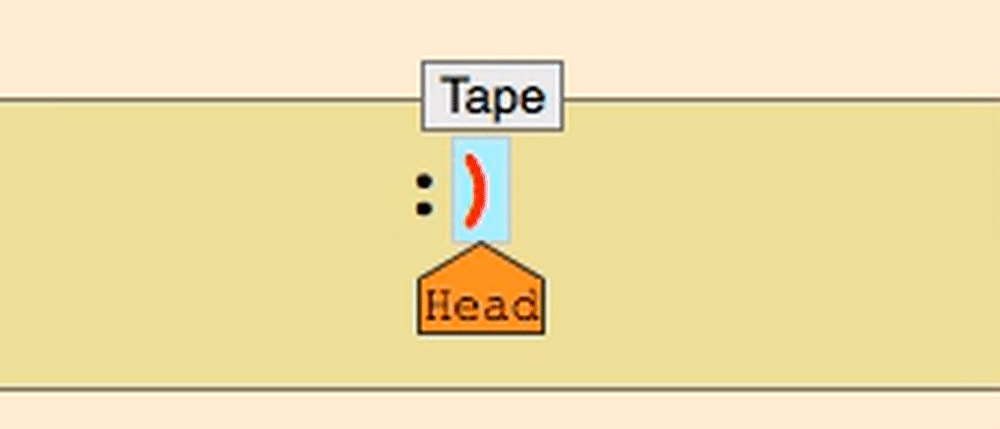
图灵机是一种抽象的计算机模型,它通过在一个无限长的纸带上进行读写操作来执行计算。
但即使Transformer能表示这种执行轨迹,随着轨迹变长,标准的解码过程仍然会付出越来越高的成本。
然而,Christos Tzamos等提出了快速解码路径,消除了这一障碍,而二维注意力头限制,正是实现这一快速路径的关键。

总的来说,这件事真正有价值的地方,不在于「模型更会算了」,而有些能力,可以直接以「系统」的形式嵌入进去。
当Transformer内部开始运行真正的程序,LLM就不再只是一个概率模型,而更像一个由推理系统和计算引擎组成的混合体。
AI,正在变成一整套可以执行、可以组合、可以扩展的系统。
这,可能就是下一代AI的真正方向。
参考资料:
https://x.com/mtrainier2020/status/2033640996337291482
https://www.percepta.ai/blog/can-llms-be-computers