小米技术公众号今日宣布,小米AI实验室新一代Kaldi团队推出OmniVoice系统,该系统在中英文场景中的性能已达到顶尖水平,并且在多种语言任务上超越了商用系统的现有表现,成为首个支持数百种语言的语音克隆TTS模型。
据官方介绍,OmniVoice的一个显著特点是其简化的设计结构。它仅采用双向Transformer网络直接将文本转换成语音,无需额外处理步骤或复杂的混合架构和层级预测机制。这种设计使其成为了目前最简洁高效的非自回归TTS模型之一。
该系统在合成语音的质量上超越了当前主流的同类模型,并且在训练速度和推理效率方面也有显著优势:一天内即可完成10万小时的训练,使用PyTorch进行推理时可以达到40倍的实时性能。这些特性使其能够适应各种应用场景的需求。
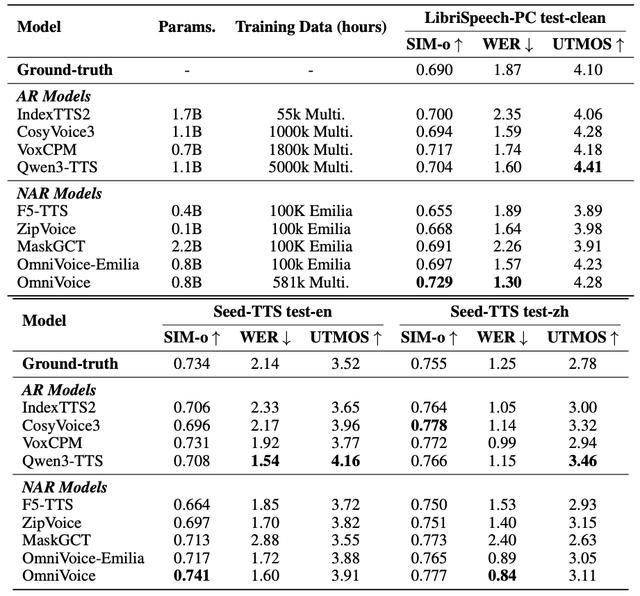
这一成就背后的关键在于两项创新设计:一是采用全码本随机掩蔽策略来提高模型的学习效率;二是利用大型语言模型作为预训练参数,首次在非自回归TTS框架中有效运用了大语言模型技术,大幅提升了语音合成的可理解性。
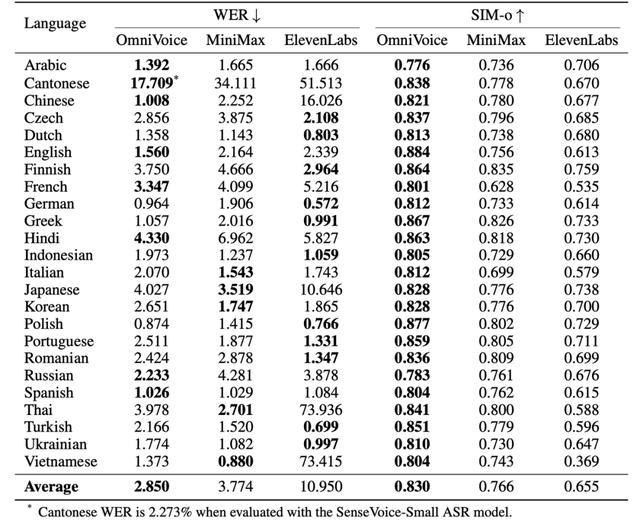
从官方资料来看,在多语种测试环境中,即使仅基于开源数据集进行训练,OmniVoice也能在24种语言的测试中超越商用系统的表现;而在涵盖102种不同语言的大规模评估中,其表现接近甚至优于真实语音。即便面对仅有不足10小时训练数据的小语种情况,该系统仍能生成高质量的合成语音,大大降低了低资源环境下进行语音合成的技术难度。
此外,OmniVoice还提供了一系列实用功能:
用户可以根据个人偏好描述音色属性(如性别、年龄等),无需参考音频即可定制个性化的音色,并且支持包括耳语在内的多种特殊风格的生成。
对于受噪音影响的录音环境,OmniVoice具备自动降噪能力,可以从嘈杂环境中提取清晰的声音特征,确保克隆出高质量的语音效果。
系统还能够插入笑声、叹气等语气符号,增强合成语音的表现力,使其更加贴近自然对话的感觉。
针对中文和英文中的多音字及专有名词易读错的问题,用户可以通过简单的设置来纠正发音错误,从而提高语音合成的准确性。