
当前,基于预训练视觉表征构建世界模型已成为具身智能领域的一项重要研究方向。例如,DINO-WM 等先进成果表明,利用视觉 Transformer (ViT) 架构可以准确捕捉复杂的物理动态,并具备强大的零样本规划能力。然而,该方法在处理所有图像块时采用密集计算的方式,导致大量资源被浪费在静态背景上,从而造成了高昂的计算成本和决策速度减缓的问题。
特别是在处理如 Push-T 等典型操作任务时,最先进的模型 DINO-WM 的每个预测控制 (MPC) 决策循环耗时高达两分钟。这显然不符合需要高频互动的真实场景的需求,从而阻碍了机器人在各种环境中的广泛应用和低成本部署。
最近,中山大学人机物智能融合实验室与拓元智慧 X-Era AI 合作提出了一种新的世界模型框架:DDP-WM(解耦动态预测世界模型),旨在解决上述挑战。该框架的核心在于分离动态特征的计算,并通过一系列设计优化了资源分配,从而在提高推断速度的同时增加了复杂任务规划的成功率。

- DDP-WM 在处理 Push-T 任务时,将规划速度提高了9倍,同时成功率从90%提升到了98%,展示了其在预测效率和准确性方面的显著优势。这项研究为开发高效且高保真的世界模型开辟了新路径。
- 研究指出,现有的密集计算范式存在大量计算资源浪费的现象,主要原因是大部分场景中变化的区域占比很小,而静态背景占据了大多数空间。因此,该团队对这一现象进行了深入分析,并通过主成分分析 (PCA) 可视化展示了模型内部的工作机制及其处理动态数据时的情况。
- 图1(a) 展示了密集计算范式的特征演变过程中的 PCA 视觉效果,揭示了大量的重复无效计算。进一步地,在相邻帧之间的差异可视化中(图1(b)),可以看出只有极小部分的特征发生了显著变化,这表明物理世界中的动态在特征层面表现出高度稀疏性。
I. 动机
该现象的核心在于大规模预训练视觉模型潜在空间表示对稀疏运动变化的高度敏感性和固有的稀疏特性。这一观察结果直接支持了 DDP-WM 的设计理念:通过区分不同类型的动态,并优化计算资源分配,可以实现更高效的预测过程和更高的性能。
II. 架构设计

图2 描述了 DDP-WM 框架的整体结构。
如图所示,该框架首先使用高效的历史信息融合模块,将速度、加速度等高级动态信息注入当前帧特征中。富含历史信息的 tokens 经过动态定位网络来识别下一帧中的主要变化区域;随后,这些变化区域通过强大的稀疏预测器进行处理,而背景则在低秩校正模块中得到更新。

2.1 动态定位
动态定位网络的功能在于高效、准确地识别出可能发生重要动态的图像块。轻量级视觉 Transformer (ViT) 被用来输出一个稀疏的二值掩码,该掩码用于标记预期发生主要物理交互的区域。
2.2 稀疏预测
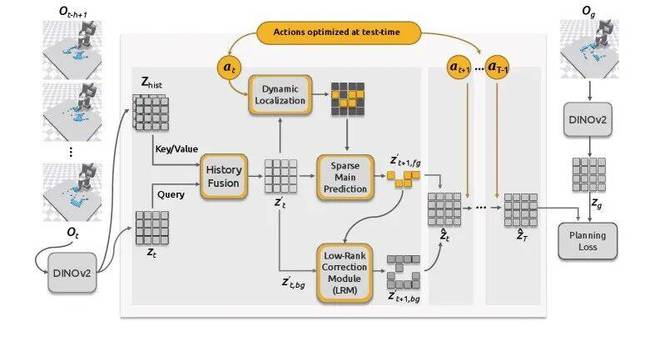
主动态预测器专门处理被识别出的关键变化区域。它利用多层 ViT 架构,但仅将资源分配给关键前景特征子集,避免了对静态背景的无效计算。这种设计允许更深更强的模型专注于实际物理过程的建模。
2.3 背景更新
对于被视为近似静态的大面积背景区域,DDP-WM 使用了一种低成本的自洽校正策略:低秩校正模块。这一设计通过单向交叉注意力机制允许来自前一帧的背景特征与新生成的前景特征进行交互。
III. 实验验证
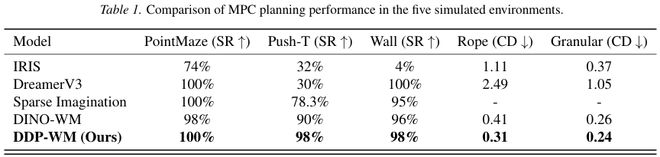
为了全面评估 DDP-WM 的有效性,研究团队在五个不同动态特性和任务复杂度的仿真环境中进行了广泛的实验。这些环境包括从简单的导航到复杂的刚体操作和柔性体运动等场景。主要评估指标为规划成功率、倒角距离及模型预测控制 (MPC) 的计算效率。
3.1 性能超越现有最佳基准
实验结果显示,DDP-WM 在所有任务上的性能均优于或等于当前最先进的密集世界模型 DINO-WM。例如,在 PointMaze 和 Wall 导航中达到了高保真的预测效果,并且在 Push-T 任务中的单次决策时间显著缩短至16秒。
3.2 效率实现数量级提升
实验数据从计算成本、推理吞吐量及端到端 MPC 决策延迟三个维度展示了 DDP-WM 的效率优势。例如,在 Push-T 任务中,DDP-WM 单步前向推理的 FLOPs 为 2.5G,而 DINO-WM 则需要 23G。
IV. 分析
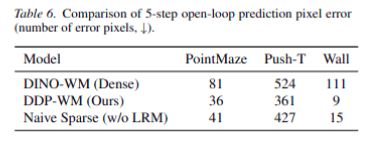
消融实验表明,当去掉低秩校正模块 (LRM) 后,虽然开环预测仍能保持高保真度,但模型的 MPC 成功率急剧下降至70%。这说明 LRM 在闭环规划中的关键作用。
图6 展示了移除 LRM 的稀疏模型与完整 DDP-WM 模型生成的成本地形对比图,证明前者在优化过程中遇到了崎岖不平且噪声较大的环境,而后者则提供了一个光滑且易于优化的漏斗状结构。
研究团队进一步通过主成分分析 (PCA) 证实了背景更新过程本质上是低秩的,并展示了 LRM 模块成功学习到了这种结构。这为 DDP-WM 的高效性和准确性提供了理论支持。
总结而言,DDP-WM 通过精妙的设计减少了计算资源的需求,在不牺牲甚至超越现有最佳模型性能的前提下显著提升了世界模型预测速度。这对于推动具身智能技术在工业生产和家政服务等实际场景中的应用具有重要意义。这一突破性进展使得更复杂的机器人系统能够在轻量级边缘硬件上实现高效部署,从而开启了自主机器人的新时代。

3.2 效率实现数量级提升
实验数据从三个方面来度量 DDP-WM 的效率提升:理论计算成本 (FLOPs)、实际推理吞吐量、端到端 MPC 决策延迟。动态复杂的 Push-T 任务中,DDP-WM 的单步前向推理 FLOPs 为 2.5G,DINO-WM 的单步前向推理 FLOPs 为 23G,两者之比约为 0.108。该理论上的优势被转化成了实际推理速度的提高。在单步推理吞吐量测试中,DDP-WM 在 Push-T 任务上实现了每秒 1563 个样本的吞吐量,相比 DINO-WM 提升了9.2 倍。如此显著的速度优越性在整个 MPC 决策循环中能够更显著地体现;比如,在需要 30 次 CEM 迭代的 Push-T 任务中,DDP-WM 的单次决策时间从 DINO-WM 的两分钟显著缩短至 16 秒,这就使得更高频率的实时机器人控制成为了可能。
3.3 消融实验
为对框架中各设计元素的有效性进行验证,研究团队对 Push-T 任务进行了一系列消融实验。其核心结果是:当去除低秩校正模块 (LRM),并只进行稀疏预测,而将静态区域的特征严格保持与上一帧不变时,虽然开环预测仍然能够保持超越稠密预测的高保真建模,但是模型的 MPC 成功率从 98% 急剧下降到 70%。这说明 LRM 解决的并非简单的开环预测精度问题。
IV. 分析:闭环规划中的挑战与低秩校正
消融实验揭示了一个关键现象:虽然简单的稀疏化方案(即去掉 LRM 的版本,仅预测前景并直接复制背景)在多步开环预测中表现良好,但在闭环规划中性能急剧下降。研究团队对不同模型为规划器生成的优化景观进行了可视化分析。
4.1 优化景观
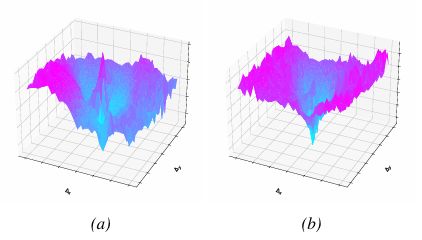
图 6:MPC 成本函数景观对比。(左图)移除 LRM 后的稀疏模型生成了一个崎岖不平、噪声较大的成本景观。 (右图)完整的 DDP-WM 模型提供了一个平滑且易于优化的漏斗状地形。
移除 LRM 之后,模型产生的代价地形崎岖不平,噪声大,峰形呈锯齿状,没有明显的全局最小值(图 6(a))。这种地形上任何基于采样的优化器都无法找到有效的下降方向,在闭环规划中就会失败。相反的是, 带有 LRM 的 DDP-WM 模型生成的代价地形非常平滑,并且有明显的漏斗状宏观结构,中间有一个深的、唯一的最小值(图 6(b))。这种地形给优化算法提供了一个清晰的引力井,从而可以稳定地收敛到最优解。
4.2 低秩结构
研究团队进一步假设,这种看似复杂的全局背景更新本质上是低秩的。为了验证这一核心假设并检验 LRM 是否成功学习到这种结构,研究团队对由真实特征图做差得到的背景更新特征图和 LRM 模块生成的背景更新特征图进行了主成分分析 (PCA)。 结果发现,真实更新特征图的累积解释方差曲线随着主成分数量的增加,呈现出急剧上升、快速饱和的趋势(图 7),有力地证明了真实特征图的更新过程本身就是低秩的。另外也可以看到,LRM 模块生成的更新特征图的 PCA 曲线和真实值曲线非常相似。
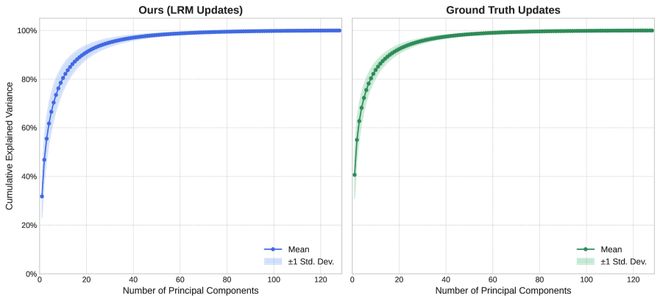
图 7:LRM 成功学习到真实的低维结构。(左图)LRM 预测的更新特征的 PCA 分析(右图)真实更新特征的PCA 分析。
V. 总结与展望
DDP-WM 的成功表明,通过基于对潜在空间的运动模式的深刻洞察进行有针对性的结构设计,完全可以在不牺牲甚至超越现有 SOTA 的前提下,显著提高世界模型预测速度。这项工作对于推动具身智能走向实际应用有重大意义。DDP-WM 把对计算资源的依赖降低了一个数量级之后,就有可能在更轻量级的边缘硬件上部署更高频、更复杂的模型来进行规划,从而为工业生产和家政服务等实际场景中部署先进的自主机器人铺平道路。