赋予视频生成「视觉思维链」:VChain显式建模时空规划与状态演变
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?在具身智能、影视制作以及物理仿真等应用场景中,要求模型不仅要生成 “平滑的像素”,更要实现 “逻辑连贯的演化”。这种对物理规律与因果关系的建模能力,是当前基于大数据驱动的端到端生成模型面临的长期挑战。那么,我们能否将多模态大模型(MLLM)的推理能力,作为一种 “外脑” 注入到
科技3 阅读
共找到 17 篇相关文章
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?在具身智能、影视制作以及物理仿真等应用场景中,要求模型不仅要生成 “平滑的像素”,更要实现 “逻辑连贯的演化”。这种对物理规律与因果关系的建模能力,是当前基于大数据驱动的端到端生成模型面临的长期挑战。那么,我们能否将多模态大模型(MLLM)的推理能力,作为一种 “外脑” 注入到
近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。然而,这种 “显式思考” 也带来了一个越来越突出的效率问题:模型往往需要生成大量的中间推理文本,导致推理 token 数显著增加,从而带来更高的推理延迟、显存占用和计算成本。尤其在多模态大模型(MLLMs)中,输入通常包含图像、问题和复杂上下文,模型为了完成推理,往往需要先

PRISM团队 投稿量子位 | 公众号 QbitAISFT之后,直接上强化学习就够了吗?小心,你做的可能不是“训练”,而是“还债”。在多模态大模型(MLLM)的后训练中,行业内长期遵循着一个看似天经地义的范式:先SFT,再RL,两步到位。从DeepSeek到Qwen,从GRPO到DAPO,大家拼命优化RL算法的稳定性、采样效率、奖励设计……却几乎没人回头看一眼:SFT到RL之间,是不是少了点什么?

SFT别急着接RL!你的多模态大模型可能一直在“带伤训练” 衡宇 2026-05-17 11:42:11 量子位 先把SFT挖的坑

“以图思量”的方法,即通过工具调用或代码生成等方式,在思考过程中引入辅助图像(如裁剪、标定、作辅助线等),已成为增强多模态大语言模型视觉推理能力的重要手段。这类方案虽然效果显著,但也带来了对外部工具的依赖性,导致了几个局限。训练和推断复杂度高:在训练过程中,模型需要额外学习各种工具及函数接口的使用方式,增加了训练难度;同时,在多轮交互式推理中也延长了推断延迟时间。可操作类型受限:受制于可用工具种类

ReCALL团队在量子位平台上发布了一篇文章,探讨了生成式模型的应用效果。当多模态大模型具备强大的视觉和逻辑推理能力时,人们期待它们能轻松解决图像检索任务,尤其是组合图像检索问题。然而实际应用中却发现,将这些大型生成式模型改造为判别式的检索工具后,其性能反而显著下降。这种从生成转向判断的转换过程中产生了严重的功能退化现象。最近,紫东太初团队与新加坡国立大学的研究人员合作解决了这一行业难题,并提出了

凤凰网科技讯 3月30日,智象未来(HiDream.ai)与诺亦腾机器人(Noitom Robotics)近日宣布正式达成战略合作。双方将结合多模态大模型的视频生成能力与真实动作捕捉基础设施,共同探索具身智能行业高质量训练数据的大规模生成模式。诺亦腾机器人创始人兼首席执行官戴若犁与智象未来创始人兼首席执行官梅涛共同出席了此次签约仪式。当前,具身智能产业正面临高质量多模态训练数据的获取瓶颈。相较于传

IT之家 3 月 27 日消息,美团今日发布原生多模态大模型 LongCat-Next,将图像、语音与文本统一映射为同源的离散 Token,使模型从学习连续空间的映射,转向学习离散 ID 之间的关系结构,并通过纯粹的下一个 Token 预测(Next Token Prediction, NTP)范式,以一种统一的方式建模各种物理信号。美团还宣布把研究思路的核心 —— LongCat-Next 模型

近日,多模态生成式AI公司智象未来(HiDream.ai)推出了其首款专为图片与视频领域的原生AI应用HiDreamClaw。这款产品现已在面向海外用户的个人创意工具vivago的网页版中投入使用。随着通用AI代理的不断涌现,市场焦点逐渐转向了具体应用场景。此次新产品的发布,标志着AI代理正在更多地介入到垂直内容创作领域。HiDreamClaw的核心技术基于智象未来自主研发的百亿参数级多模态大模型
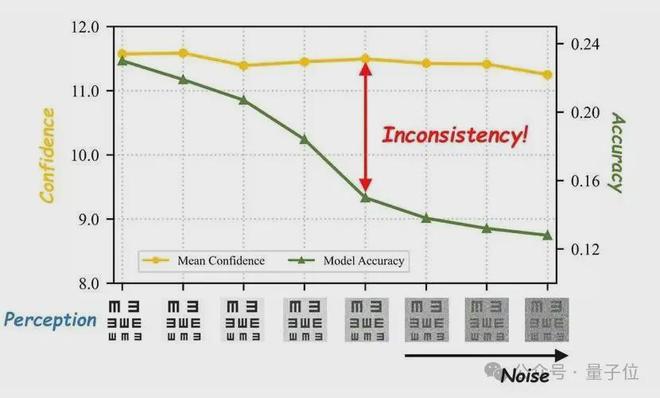
多模态大模型的自信心有多强?一项由浙江大学、阿里巴巴、香港城市大学及密歇根大学的研究团队进行的实验表明:当图像逐渐变得模糊,直至几乎无法辨认时,研究者持续监测模型的准确率与置信度的变化情况。实验结果显示,准确率急剧下降,而置信度基本保持不变。这意味着,即使图像变得模糊,模型仍然会以很高的置信度给出答案。这种“盲目自信”的倾向,正是多模态大模型在复杂视觉推理中产生幻觉和误判的主要原因之一。为了解决这

量子位公众号QbitAI收到了一篇由MIPL团队提交的文章。当你看到一只蓝锥嘴雀的照片时,或许能辨认出它属于鸟类,但能否具体到“鸟纲-雀形目-唐纳雀科-锥嘴雀属-蓝锥嘴雀”这个分类呢?目前,即使是先进的多模态大模型也无法准确完成这一任务。实际上,自然界中的物种分类结构非常复杂,形成了从界到种的层级体系。例如,蓝锥嘴雀属于动物界-脊索动物门-鸟纲-雀形目-唐纳雀科-锥嘴雀属-蓝锥嘴雀。与传统的细粒度

一项新的研究指出,北京大学彭宇新团队利用细粒度树形结构先验,提高了多模态大模型在生物分类识别中的泛化能力,成功解决了生物类别层次识别的难题。 衡宇 2026-03-21 17:48:18 量子位

多模态大模型的研发方式正在经历全面革新。 今天,商汤科技与南洋理工大学共同发布了最新技术成果NEO-unify。 这是一个实现了“原生、统一、端到端”的多模态架构,其最突出的创新在于: 彻底摒弃了传统的视觉编码器(VE)和变分自编码器(VAE)。不再依赖组件拼凑来完成感知与生成任务,而是直接以近乎无损的形式处理像素和文字。 通过独特的混合变换器(Mixture-of-Transformer, Mo
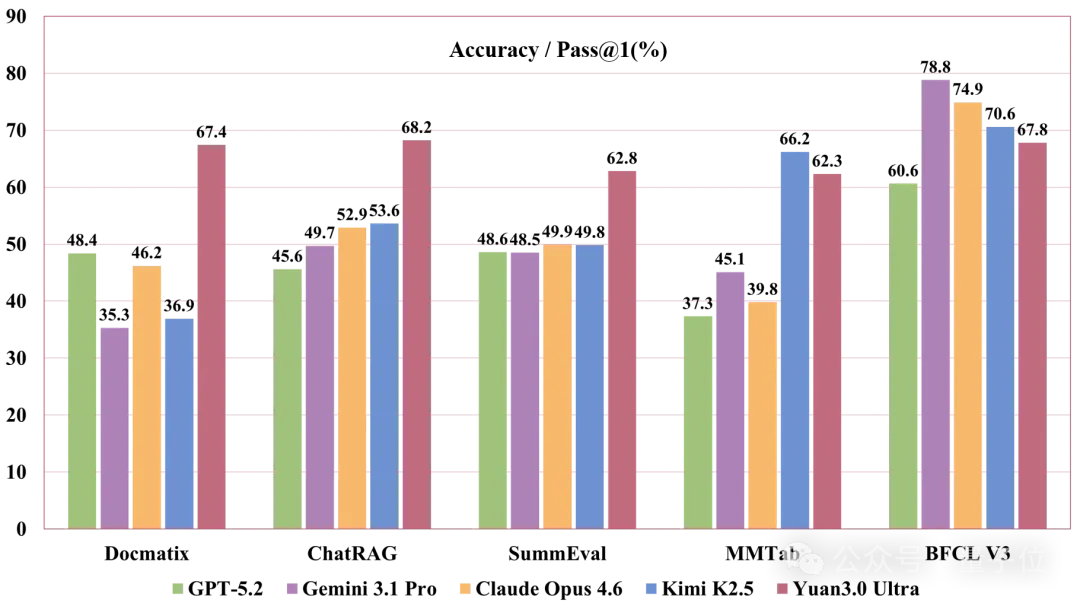
YuanLab.ai团队近日宣布,正式开源源Yuan3.0 Ultra这一多模态基础大模型。 作为源3.0系列的一部分,这款旗舰模型是目前仅有的三个达到万亿级参数规模的开源多模态大模型之一。 它通过引入MoE架构来优化训练效率,并针对企业应用及智能体工具调用进行了深入改进,在多模态文档理解、检索增强生成(RAG)、表格数据分析和内容摘要等领域表现出色。 该模型能够高效处理企业环境中的复杂信息,如图
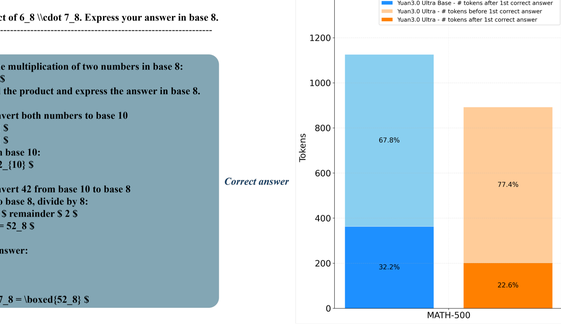
YuanLab.ai团队近日正式发布了源Yuan3.0 Ultra多模态基础大模型的开源代码。 作为源3.0系列中的旗舰产品,源Yuan3.0 Ultra是全球少数几个可以公开获取的万亿级参数规模的大模型之一。 源Yuan3.0 Ultra在设计上引入了混合专家(MoE)架构,并针对企业应用和智能体工具调用进行了优化,在多模态文档理解、检索增强生成、表格数据分析以及内容摘要等方面表现出色。 这些能

新智元报道【新智元导读】Meta联合多所高校发布首个可规模化自动生成第一视角音视频理解数据的引擎EgoAVU ,让多模态大模型首次真正「听懂世界」。现在最强的多模态大模型,虽然能接收声音和视频输入,但无法做到真正的「同时理解」。在第一视角视频任务中,模型经常会出现各种问题,比如完全忽略音频信息、错误判断声源位置、用视觉线索「猜声音」,也就是说,现在的多模态大模型只会看,但不会听。而这正是当前具身智

本文第一作者朱子瑞为新加坡国立大学四年级博士生,本科毕业于清华大学,研究方向为多模态大模型和后训练优化。通讯作者为 TikTok 内容智能负责人 Kanchan Sarkar、Meta杨振恒博士(相关工作完成于其在 TikTok 任职期间)以及新加坡国立大学校长青年教授尤洋老师。文章速览长视频会使 MLLM 的视觉 token 规模快速增长,但推理阶段的计算与上下文预算有限,难以对全量帧进行处理。