ReCALL团队在量子位平台上发布了一篇文章,探讨了生成式模型的应用效果。
当多模态大模型具备强大的视觉和逻辑推理能力时,人们期待它们能轻松解决图像检索任务,尤其是组合图像检索问题。
然而实际应用中却发现,将这些大型生成式模型改造为判别式的检索工具后,其性能反而显著下降。这种从生成转向判断的转换过程中产生了严重的功能退化现象。
最近,紫东太初团队与新加坡国立大学的研究人员合作解决了这一行业难题,并提出了ReCALL框架。该框架通过独特的“诊断-生成-校准”闭环体系,克服了生成式模型向判别式检索器转变时遇到的范式冲突问题,使大模型在保持其原始推理能力的同时,能够高效地执行图像检索任务。

这项成果已被国际计算机视觉顶级会议CVPR 2026收录,并且在CIRR和FashionIQ等基准测试中刷新了性能指标的新纪录。这为多模态大模型的应用开辟了一条新的路径,有助于其更有效地应用于具体领域。
在实际操作中,范式冲突导致的智能倒退成为一大挑战
聪明的MLLM为何在执行检索任务时容易出错?研究团队指出,根本原因在于生成和判别两种模式间的矛盾冲突。
大模型习惯于采用链式的思考方式来理解视觉关系,但为了适应搜索需求而强行将其转化为基于单一向量的方法,这会导致其原有能力的退化。
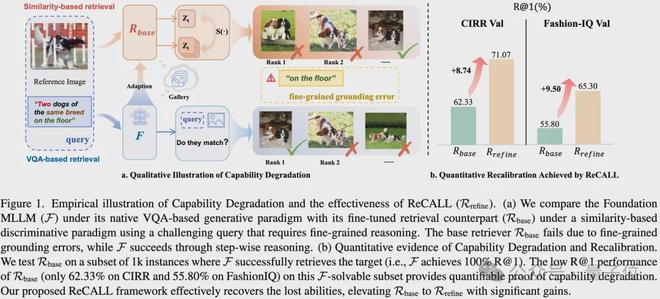
如图所示,在面对需要细致推理的问题时,未经调整的大模型能够准确地找到答案。然而,经过传统微调后的检索器版本却常常给出错误的答案。
数据显示,与原始大模型相比,经微调的检索器在特定任务中的性能下降明显:CIRR数据集上的R@1从原来的100%降至62.33%,而在FashionIQ上则降到了55.80%。这表明,这种调整不仅没有提升性能,反而削弱了模型原有的推理能力。
为了克服这一挑战,作者提出了一种名为ReCALL的四阶段校准框架
鉴于能力退化的原因是由于初始微调导致的大模型偏离正轨,因此如何引导其回归正确的轨道成为关键。
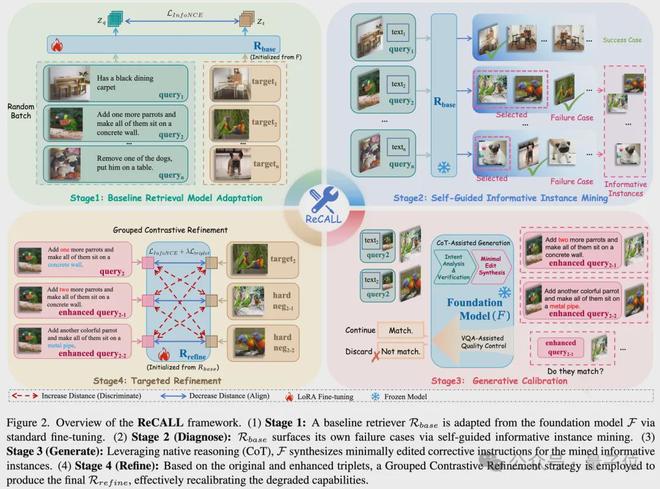
ReCALL的核心在于利用大模型原本的推理信号来纠正检索空间中的盲点。整个过程被细分为四个步骤:基础适配、自我诊断、生成校准和针对性打磨。
在初始阶段,研究人员通过标准损失函数将原始模型微调为一个基础检索器。尽管这赋予了它初步的检索能力,但也导致了一些功能上的退化。
在第二步中,团队让基础检索器在训练集上运行以识别错误样本,并从中提取出具有误导性的负面案例作为后续调整的基础。
第三阶段是生成校正。通过精心设计的方法来纠正这些错误,具体包括意图分解和验证以及最小编辑合成两个核心步骤。
这些措施帮助模型生成了从正确答案到错误结果的修正指令,从而提供了精确的纠错信号,确保训练数据的一致性和准确性。
最终阶段通过分组对比学习来进一步优化检索器的功能。这种方法促使模型能够区分极其细微的区别,并将原有的推理能力融入其向量空间中。
实验结果表明,ReCALL框架在多个基准测试中的表现均优于现有方法,在复杂数据集上的性能提升尤为显著。
例如,在CIRR开放域数据集中,它实现了55.52%的R@1新纪录,相对基线模型有8.38%的进步。而在细粒度的FashionIQ数据集中,其平均R@10达到了57.04%,展示了强大的区分能力。
从实际案例来看,经过ReCALL调整后的模型能够更准确地识别特定条件下的目标对象,而未经改进的基础模型则难以完成这一任务。
ReCALL框架的贡献不仅体现在性能上的提升,更重要的是它揭示并解决了多模态大模型在迁移应用过程中遇到的问题。
它表明,在将大型生成式模型应用于检索任务时,应该重视保留和激发它们的原始推理能力,而非简单地将其压缩为单一的判别向量。
当采用这种方法训练模型去分析错误并弥补认知盲区时,可以有效提升其在各种复杂场景下的表现,并促进生成与判断两种范式的融合。
实测成绩:全场景刷新SOTA,细粒度检索能力拉满
ReCALL的有效性在各大主流基准测试中得到了验证。

- CIRR开放域复杂数据集上,ReCALL创造了55.52%的R@1新SOTA,相较于基线模型实现了8.38%的相对提升!在专门考察细粒度区分能力的子集上(R_{subset}@1),更是达到了恐怖的81.49%。
- FashionIQ细粒度时尚数据集上,即便面对极度相似的服装干扰项,ReCALL依然取得了最好的表现,平均R@10达到57.04%
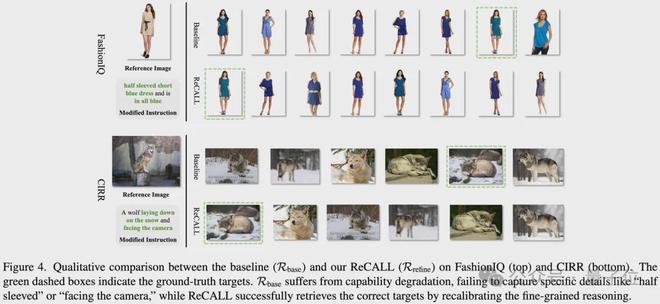
看看上面的实际检索案例,基线模型遇到“正视镜头”、“半袖”这种细粒度条件直接懵圈;而经过ReCALL校准后的模型,眼光毒辣,精准锁定目标!
结语
ReCALL的成功不仅在于刷新了组合图像检索的性能上限,更在于它揭示并修复了多模态大模型在向下游任务迁移时的一道隐形裂痕。
大模型做检索,不应只是粗暴地将高维的“生成式智慧”压缩降维成单一的“判别式向量”。从“盲目对齐”到“诊断—生成—内化”的逻辑闭环,大模型的检索适配正在进入一个强调保留与激发原生推理能力的新阶段。
当我们不再一味追求用海量外部数据去“喂”出一个检索器,而是教会模型用自己的思维链去剖析错题、缝合认知盲区时,它不仅找回了丢失的细粒度感知,更展示了生成与判别两大范式走向和解的可能。
这或许是大模型在诸多垂直领域真正实现“能力无损适配”的重要一步。
论⽂链接:
https://arxiv.org/abs/2602.01639
项⽬代码:
https://github.com/RemRico/Recall