多模态大模型的自信心有多强?
一项由浙江大学、阿里巴巴、香港城市大学及密歇根大学的研究团队进行的实验表明:
当图像逐渐变得模糊,直至几乎无法辨认时,研究者持续监测模型的准确率与置信度的变化情况。
实验结果显示,准确率急剧下降,而置信度基本保持不变。这意味着,即使图像变得模糊,模型仍然会以很高的置信度给出答案。
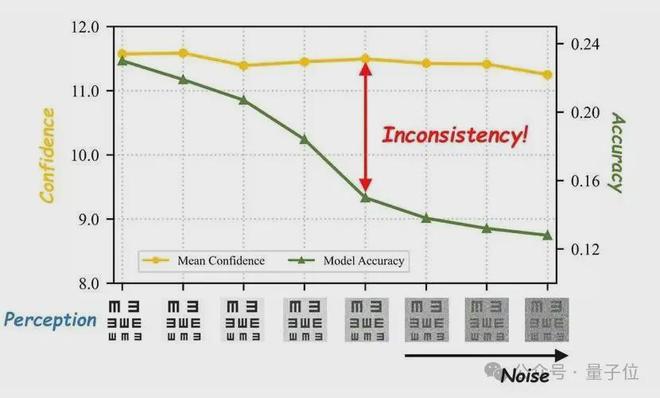
这种“盲目自信”的倾向,正是多模态大模型在复杂视觉推理中产生幻觉和误判的主要原因之一。为了解决这一问题,研究团队提出了一种称为CA-TTS(Confidence-Aware Test-Time Scaling)的框架:该框架首先通过强化学习校准模型的自我评估能力,然后将校准后的置信度转化为推理阶段的资源分配信号。
实验表明,CA-TTS在四个主流视觉推理基准上全面达到了最先进的水平,平均超越现有最优方法8.8%。尤其是在Math-Vision基准上,准确率从23.0%提升至42.4%。

达尔文曾经指出,无知往往比知识更容易带来自信
这项研究的主要出发点,是一个长期被忽视的问题:模型是否真正理解它不知道的信息?
研究团队将上述现象定义为“感知钝化”(Perceptual Bluntness)。也就是说,模型对视觉信息质量的变化不够敏感,即使视觉证据明显退化,置信度仍然很高。在人类语境下,这就像一个人在看不清题目时仍然非常自信地给出答案。
为了更稳定地衡量这一问题,研究团队没有采用文本模型中常见的token级校准方法,而是将置信度定义为整个输出序列的平均负对数概率(NMLP),建立了一种响应级别的置信度度量。基于这一度量,整个方法分为两个阶段:训练阶段的置信度校准以及推理阶段的置信度感知扩展。
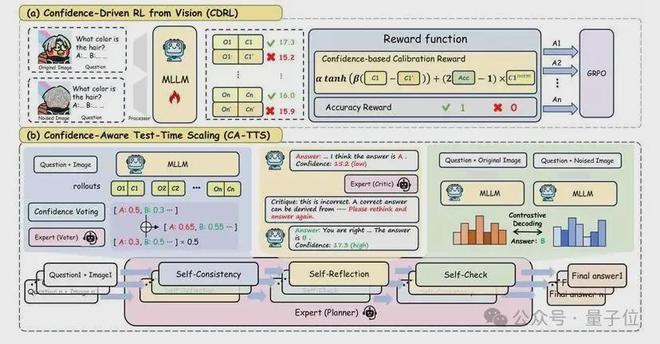
第一阶段:CDRL重新校准视觉感知与置信度
训练阶段的核心模块是CDRL(Confidence-Driven Reinforcement Learning)。其目标是让模型在“看得清”和“看不清”两种情况下,给出与视觉证据匹配的置信度。
为此,模型被要求同时处理原始图像和加噪图像,并通过强化学习优化一个双重奖励机制:
1. 视觉敏感性奖励:鼓励模型在原始图像和噪声图像之间产生合理的置信度差异。差异越大,说明模型对视觉退化越敏感。
2. 校准一致性奖励:当模型预测正确且置信度高时给予奖励;当模型预测错误但置信度仍高时施加惩罚。
这两个奖励机制共同约束模型学会两个方面:一是对视觉退化保持敏感,二是对自身判断保持诚实。
在训练数据上,研究团队从六个公开基准中筛选出了1936个高质量样本,并使用CLIP注意力图定位关键视觉区域,生成更具针对性的扰动,使噪声集中施加在真正影响推理的局部区域。
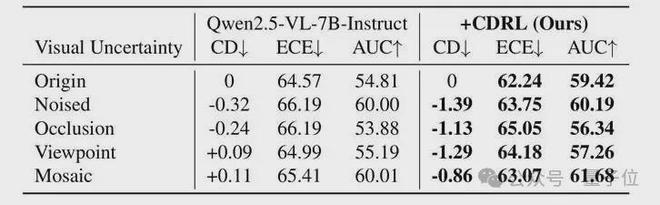
实验结果显示,CDRL的效果不仅仅是“置信度降低”,而是“置信度终于与视觉证据对齐”。面对噪声图像时,训练后的模型置信度下降幅度是训练前的4.3倍;面对遮挡条件时,这一比值达到4.7倍。
更值得注意的是,训练前模型在视角变换和马赛克干扰下,置信度甚至还会反向上升,而CDRL训练后,所有视觉扰动条件下的置信度都显著下降,ECE与AUC指标也同步改善。
第二阶段:CA-TTS将校准后的置信度转化为推理信号
有了更可信的置信度之后,研究团队进一步提出了CA-TTS,将“模型对自己有多确定”转化为推理阶段的调度信号。它包含三个协同工作的模块,并由专家模型动态决定何时介入:
自洽性检验:不再使用简单的多数投票,而是采用置信度加权投票。模型生成多个候选答案后,先由内部置信度进行聚合,再引入专家模型作为外部校准器,对候选答案进行二次评估。
反思:当初步结果的置信度不足时,专家模型以批评者的角色生成批评意见,引导基础模型重新推理,避免它在原有的错误路径上反复自洽。
视觉验证:在视觉层面对答案进行进一步验证。通过对比解码,比较原始图像与噪声图像下的输出概率分布;如果答案确实依赖视觉证据,那么在噪声图像下其支持度应当下降。
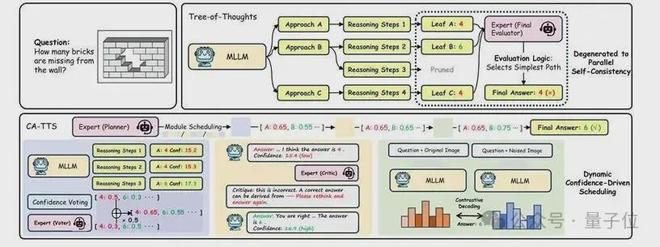
与常见的思维树不同,CA-TTS的关键不仅在于“多思考几步”,而在于建立了一个多阶段验证闭环。即使前一阶段给出了错误的候选答案,后续模块仍有机会纠正它。论文中的“墙上缺了多少块砖”案例就体现了这一点:思维树在最终单点评估上失手,而CA-TTS通过加权投票、反思和视觉自检三步纠偏,最终恢复出正确答案。
实验结果:四大基准全面领先
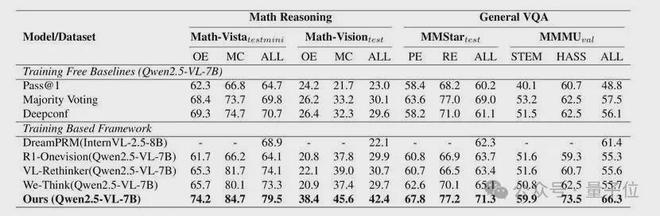
在四个主流视觉推理基准上,CA-TTS的表现如下。需要注意的是,这里的基座模型统一为Qwen2.5-VL-7B,因此提升主要来自方法本身,而不是底座差异。
几组数字尤其有代表性。Math-Vision上,CA-TTS从基线的23.0%提升至42.4%,几乎翻倍;MMMU上达到66.3%,相较基线提升17.5个百分点。这说明它带来的改进不仅限于单点收益,而是在不同类型视觉推理任务上的一致性改进。
消融实验进一步揭示了CDRL与CA-TTS的分工关系:
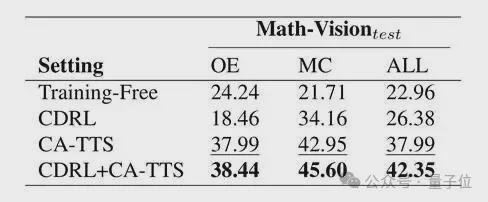
单独使用CDRL,提升3.4个百分点,说明置信度校准本身就有独立价值;单独使用CA-TTS,提升15.0个百分点,说明推理框架已经能够显著改善决策质量;两者结合后总提升达到19.4个百分点,表明CDRL为CA-TTS提供了更可靠的策略基础,二者存在明显的协同效应。
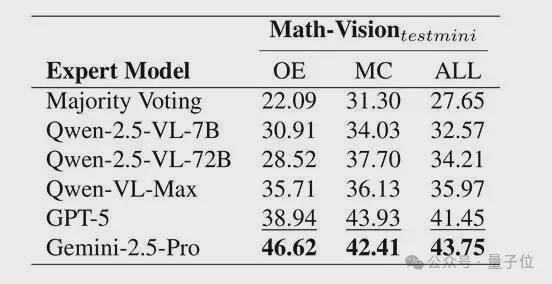
研究团队还检验了专家模型的依赖程度。即使让Qwen2.5-VL-7B自身充当“专家”,性能也仍比纯多数投票高出接近5个百分点(32.57% vs. 27.65%)。换句话说,强专家模型确实能进一步放大收益,但框架本身并不是靠“抱大腿”成立的。
测试时间缩放:斜率拉开,才是更关键的结果
如果说四个基准上的SOTA说明方法“更准”,那么测试时间缩放曲线揭示的是它“为什么更值”。
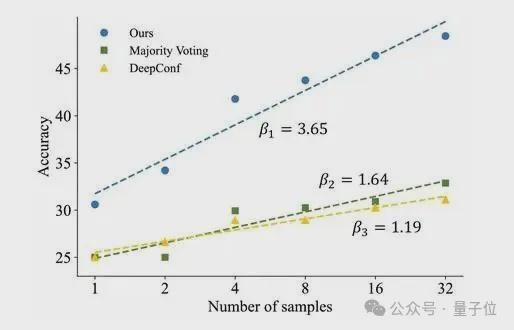
在Math-Vision上,研究团队比较了采样数量从1增加到32时,不同方法的准确率增长趋势。结果显示,CA-TTS的扩展斜率β = 3.65,而多数投票为1.64,DeepConf为1.1。这意味着CA-TTS在采样数量增加时,准确率提升更为显著。
当然,这种方法也并非没有代价。多次采样与专家模型调用会带来额外推理成本,当前实验主要集中在数学推理和通用VQA任务上。但如果目标是让多模态大模型在高风险场景中真正做到“知道自己什么时候不该太自信”,那么这条路线已经给出了一个很有说服力的起点。
论文标题:多模态大模型中的感知、置信度和准确度的联系
作者简介:本文第一作者为杜越天,浙江大学博士生,研究方向为多模态大模型的置信度校准与test-time scaling,导师为朱强教授。本文在朱强教授和刘洁博士的指导下完成。
这项工作最值得关注的地方,可能并不只是又一个更高的benchmark分数,而是它提出了一种新的问题顺序。
过去,多模态推理研究默认的前提是:模型已经在充分利用视觉信息,接下来只需要把推理能力做强。但这篇论文提醒我们,一个模型可能根本没有真正“看懂”图像,却依然能给出高度自信的回答。若这个前提没有被修正,后续再复杂的推理链条,也可能建立在不可靠的感知基础上。
CA-TTS的思路正好反过来:先通过CDRL建立对视觉证据变化敏感、且与准确性一致的置信度,再让这种置信度去指导推理资源的分配。这是一种明确的Perceive-then-Reason范式,也就是从“先推理后感知”转向“先感知后推理”。
当然,这一方向也并非没有代价。多次采样与专家模型调用会带来额外推理成本,当前实验也主要集中在数学推理和通用VQA任务上。但如果目标是让多模态大模型在高风险场景中真正做到“知道自己什么时候不该太自信”,那么这条路线已经给出了一个很有说服力的起点。
论文标题:
Linking Perception, Confidence and Accuracy in MLLMs
作者:
Yuetian Du*, Yucheng Wang*, Rongyu Zhang, Zhijie Xu, Boyu Yang, Ming Kong, Jie Liu#, Qiang Zhu#
单位:
浙江大学、阿里巴巴集团、香港城市大学、密歇根大学
发表:
CVPR 2026
项目链接:
https://github.com/anotherbricki/CA-TTS
作者简介:
本文第一作者为杜越天,浙江大学博士生,研究方向为多模态大模型的置信度校准与test-time scaling,导师为朱强教授。本文在朱强教授和刘洁博士的指导下完成。