量子位公众号QbitAI收到了一篇由MIPL团队提交的文章。
当你看到一只蓝锥嘴雀的照片时,或许能辨认出它属于鸟类,但能否具体到“鸟纲-雀形目-唐纳雀科-锥嘴雀属-蓝锥嘴雀”这个分类呢?
目前,即使是先进的多模态大模型也无法准确完成这一任务。

实际上,自然界中的物种分类结构非常复杂,形成了从界到种的层级体系。例如,蓝锥嘴雀属于动物界-脊索动物门-鸟纲-雀形目-唐纳雀科-锥嘴雀属-蓝锥嘴雀。
与传统的细粒度视觉识别不同,分层视觉识别的目标是识别出每个物种在分类树中的所有层级,而不仅仅是最终的细分类。
尽管现有的生成式大模型如Finedefics和Fine-R1在细粒度视觉识别方面表现良好,但由于缺乏对分类树的理解,它们难以从粗略到精细地识别出每一层级的类别。

此外,通过分层类别标签对比学习得到的判别式大模型(例如BioCLIP、BioCLIP2、BioCAP等)已经能够编码类别树中的关系。本文通过利用判别式大模型的特征指导生成式大模型的学习,为多模态大模型在学习分类树结构方面提供了新的途径。
背景
北京大学彭宇新教授团队的这项研究是关于细粒度多模态大模型领域的最新成果,该论文已经被CVPR 2026会议接受,并且代码已经公开。
尽管现有的多模态大模型在细粒度视觉识别上的准确度有所提高,但在涉及分类树知识的分层视觉识别方面仍然存在挑战。具体来说,有三个主要问题:
一是同层分类的差异性较差,对于较粗粒度的类别,模型容易忽略类别间的差异,而对于细粒度的类别,则容易忽略类内的相似性。
二是层级间的一致性较差,由于模型缺乏分类树知识,难以保证相邻层级的分类关系正确。
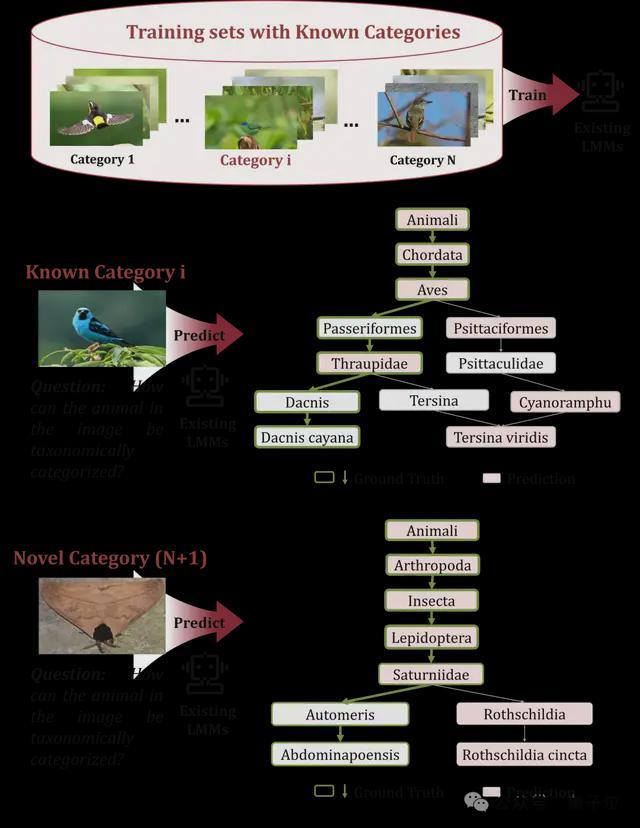
△图1. 研究背景
三是对新类别的泛化能力较差,模型通常会关注不同细粒度子类别的差异,而忽略这些子类别的共性,这影响了模型对新类别的识别能力。
针对这些问题,彭宇新教授团队提出了一种分类感知表征对齐方法(TARA),旨在将分类树结构的知识注入多模态大模型。
技术方案
该方法通过将大模型的中间层特征与生物基础模型的视觉特征对齐,促进大模型提取具有完整分类树结构的视觉特征,并通过将大模型的输出与生物基础模型的类别特征对齐,指导大模型在指定层级上生成对应的类别名称。
经过实验验证,本方法不仅能提升大模型的细粒度视觉识别精度,还能增强其分层视觉识别能力,从而在分类树的每一层级上提高识别准确度。
图2展示的是分类感知表征对齐方法TARA的框架图,该方法包含两个主要部分:
具体如下:
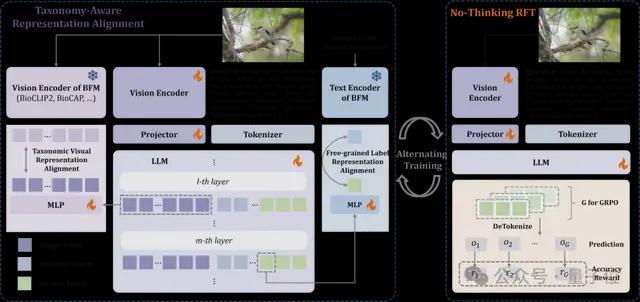
1. 层次视觉特征对齐:通过将大模型的中间层特征与生物基础模型的最后层特征进行对齐,促进大模型提取具有完整分类树结构的视觉特征。
2. 粒度自由类别特征对齐:通过将大模型的输出特征与生物基础模型的类别特征对齐,指导大模型将视觉特征映射到对应层级的类别名称。
在分层视觉特征对齐中,经过分层类别标签训练的生物基础模型能够提供包含分类学信息的监督信号,促进大模型提取具有完整分类树结构的视觉特征。给定输入图像I和特定层次类别的问题q,生物基础模型的视觉编码器εv(·)输出目标视觉特征img=εv(I)∈RN×d,大语言模型第ℓ层的视觉表征表示为ℓimg∈RN×D,采用可学习的映射层PV(·)将其映射到生物基础模型的视觉特征空间,并最小化对齐损失。
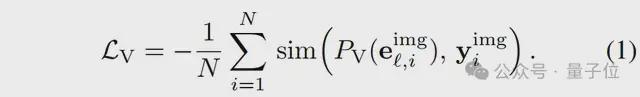
在粒度自由类别特征对齐中,一张图像可能对应多个层级的类别标签,但用户关心的层级不同。例如,专家可能希望在“种”层级上将对象识别为阿卡迪亚霸鹟,而普通用户只需要在“纲”层级上将其识别为鸟。通过在相同层级上对齐生物基础模型和大模型的类别文本特征,促进大模型将视觉特征映射到对应层级的类别名称。生物基础模型的文本编码器ET(·)输出目标文本特征ylabel=ET(C)∈Rd,大语言模型第m层的答案表征序列表示为emanswer∈RN′×D,采用可学习的映射层PT(·)将答案的首个词元表征映射到生物基础模型的文本特征空间,并最小化对齐损失。
最终,TARA的对齐损失定义为两者的平均值。

在模型的训练和推理阶段,采用无需思考的强化微调(No Thinking RFT)和TARA交替优化大模型、映射层PV(·)与PT(·),促进大模型适配分层视觉识别指令的同时学习分类树知识。在推理阶段,生物基础模型和映射层PV(·)与PT(·)不参与运算,直接由优化后的大模型进行识别。
表1展示了在iNaturalist-Plant和iNaturalist-Animal上的分层视觉识别结果。本方法不仅能提升多种大模型的细粒度视觉识别能力,还能增强分层视觉识别能力,从而在分类树的每一层级上提高识别准确度。
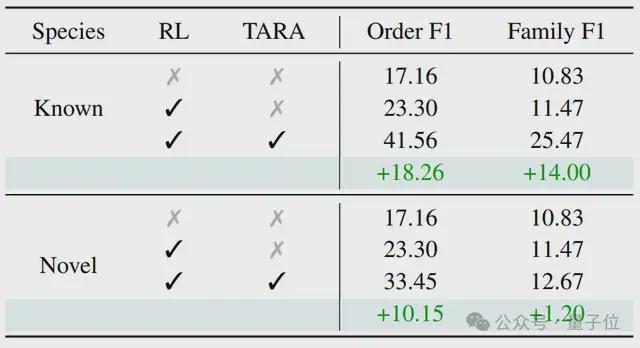
表2展示了在TerraIncognita的新类别上的分层视觉识别结果。这部分新类别不仅是在模型训练集中未出现的类别,更是稀有或记录极少的物种图像,在公开数据中几乎找不到样本。
实验结果
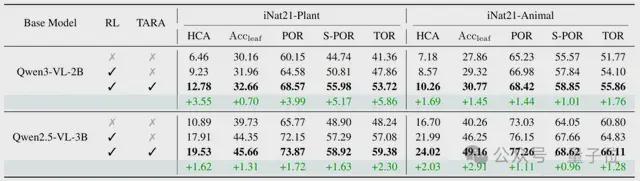
对于其中许多样本,很可能是未被科学界正式描述的新物种,目前只能可靠地确定其较高层次的分类标签(如“目”和“科”)。本方法通过引入分类树的先验知识,促进模型学习子类别的共性,从而总结出用于识别父类别的判别性特征,提升了新类别的识别准确率。
图3展示了分类感知表征对齐方法(TARA)的案例,相比阿里的Qwen3-VL-2B大模型,本方法在同层判别性和跨层一致性方面表现出色。
针对多模态大模型缺乏分类树知识的问题,本文提出了分类感知表征对齐方法TARA,通过对齐大模型与生物基础模型的中间表征,注入分类树结构知识,不仅提升了细粒度类别的识别准确率,还增强了大模型的分层视觉识别能力,提高了分类树每一层级的识别准确率。
表2展示了在TerraIncognita的新类别(已有类别树之外的类别)的分层视觉识别结果。这部分新类别不仅是模型强化微调训练集中未见类别,更是稀有或记录极少的物种图像,在公开数据中几乎没有或完全没有可用样本,更不可能出现在模型的预训练数据中。
对于其中许多样本,很可能是科学界尚未正式描述的新物种,目前只能可靠地确定其较高层次的分类标签(如“目”和“科”)。本方法通过引入类别树先验,促进模型学习子类别的共性,从而总结出用于识别父类别的判别性特征,提升已知类别树之外的新类别的识别准确率。
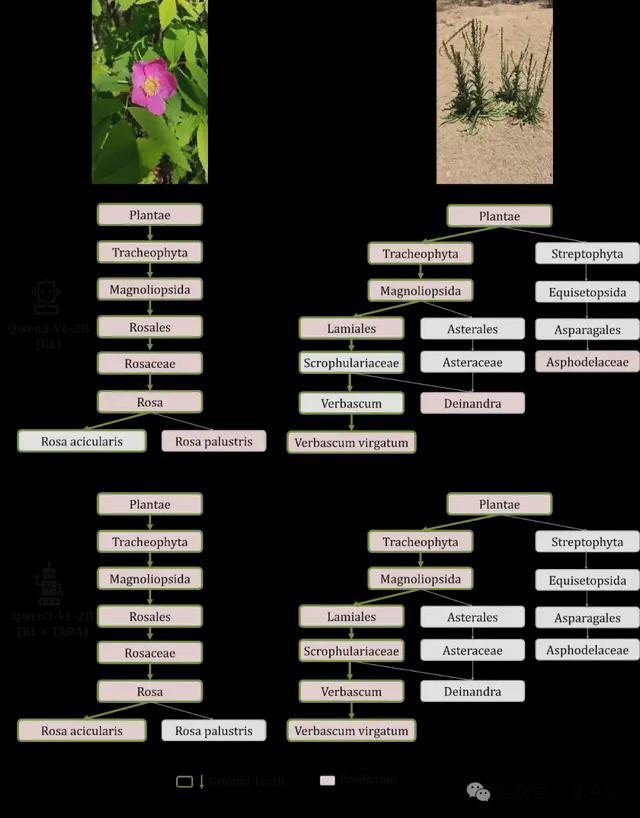
△图3. 分类感知表征对齐方法(TARA)案例展示
图3的案例展示表明,相比阿里的Qwen3-VL-2B大模型,本方法能提升同层判别性与跨层一致性,既区分开同一层的相似类别,又确保相邻层次的预测类别满足父子节点关系。
项目价值
针对现有多模态大模型缺乏类别树知识,无法从粗到细实现每一层的精准识别的问题,本文提出了分类感知表征对齐方法TARA,通过对齐大模型与生物基础模型的中间表征,注入类别树结构知识,不仅能提升最终的细粒度类别的识别准确率,还能增强大模型的分层视觉识别能力,从粗到细提升类别树上每一层的识别准确率。
论文标题:
Taxonomy-Aware Representation Alignment for Hierarchical Visual Recognition with Large Multimodal Models
论文链接:
https://arxiv.org/abs/2603.00431
开源代码:
https://github.com/PKU-ICST-MIPL/TARA_CVPR2026
实验室网址:
https://www.wict.pku.edu.cn/mipl