一项新的研究指出,北京大学彭宇新团队利用细粒度树形结构先验,提高了多模态大模型在生物分类识别中的泛化能力,成功解决了生物类别层次识别的难题。
 衡宇
衡宇通过引入完整的类别树认知,该研究推动了生成式模型向通用视觉理解迈进。
研究团队提出了一种创新方法,使多模态大模型能够更准确地识别生物分类的各个层级。
目前的多模态大模型同样无法识别这一复杂的类别层次。
实际上,自然界中的对象通常具有复杂的类别层级结构。

蓝锥嘴雀属于“动物界-脊索动物门-鸟纲-雀形目-唐纳雀科-锥嘴雀属-蓝锥嘴雀”。
与传统的细粒度视觉识别不同,分层视觉识别不仅要识别最终的细粒度类别,还需预测所有所属的类别层次。
尽管现有的一些生成式大模型在细粒度视觉识别任务中表现出色,但缺乏类别树知识,导致它们无法从粗到细地精准识别每一层。

研究团队发现,通过对比学习获得的判别式大模型,其表征空间已经充分编码了类别树中的类间和类内关系。
背景
基于这一发现,团队利用判别式大模型的表征指导生成式大模型的学习,为多模态大模型学习类别树提供了新的路径。
这项研究成果是北京大学彭宇新教授团队在细粒度多模态大模型领域的最新进展,相关论文已被CVPR 2026接收,并已开源。
尽管现有多模态大模型在细粒度视觉识别的准确率上有所提升,但在分层视觉识别任务中,仍面临挑战。
具体而言,有以下三点挑战:
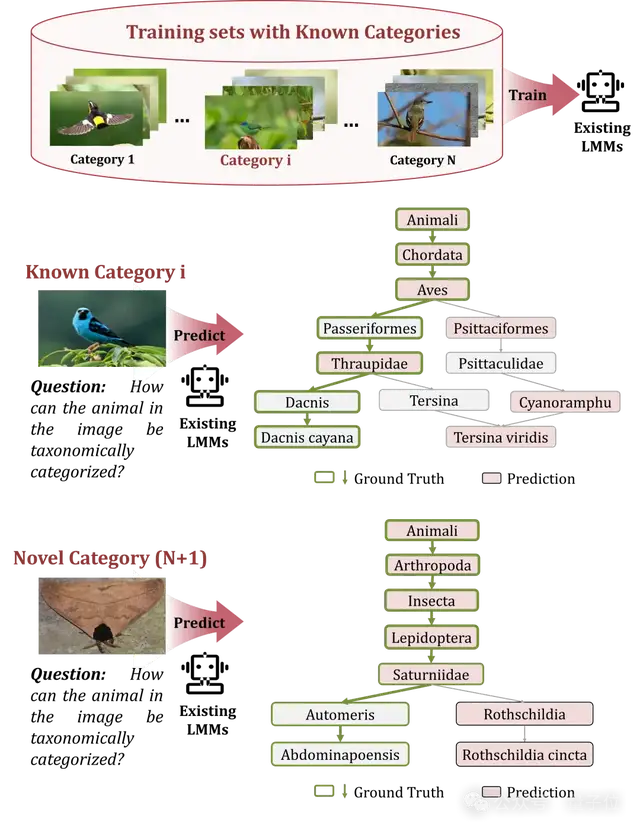
△图1. 研究背景
1. 类别层次中的区分能力不足:对于较粗的类别层次,模型倾向于学习类内的共同点;而对于较细的类别层次,则倾向于学习类间的特点。这种差异导致模型难以区分相似的类别。
2. 无法保证相邻层次间的关系:由于缺乏类别树知识,模型难以确保相邻层次的预测类别满足父子节点的关系。
技术方案
3. 新类别识别能力不足:现有模型倾向于挖掘不同细粒度子类别的差异,忽视了对共性的总结,难以准确识别未见过的新类别。
为解决这些问题,彭宇新教授团队提出了分类感知表征对齐方法(TARA),用于将类别树结构知识注入多模态大模型。
通过将大模型与生物基础模型的视觉表征对齐,促进大模型提取具备完整类别树结构的视觉表征。
具体如下:
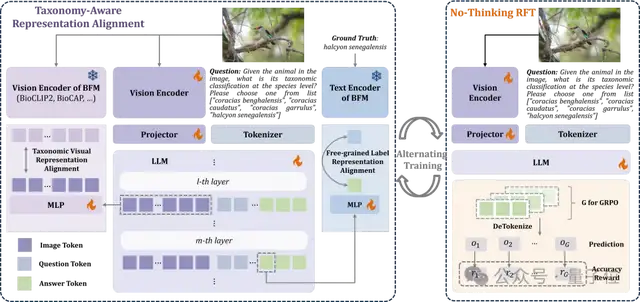
同时,通过将大模型输出答案的首个词元表征与经生物基础模型编码后的真实类别表征对齐,促进大模型将具备完整类别树结构的视觉表征映射为对应层次的类别名称。
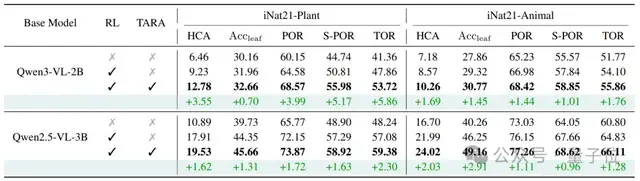
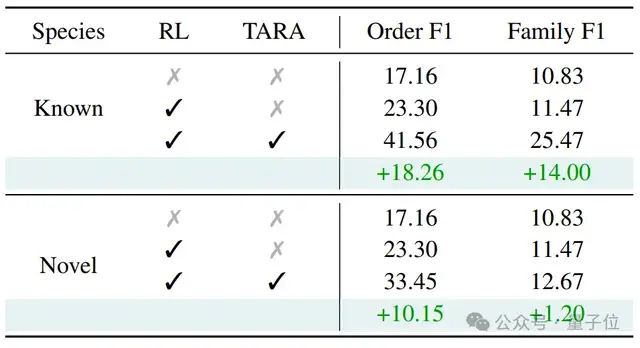
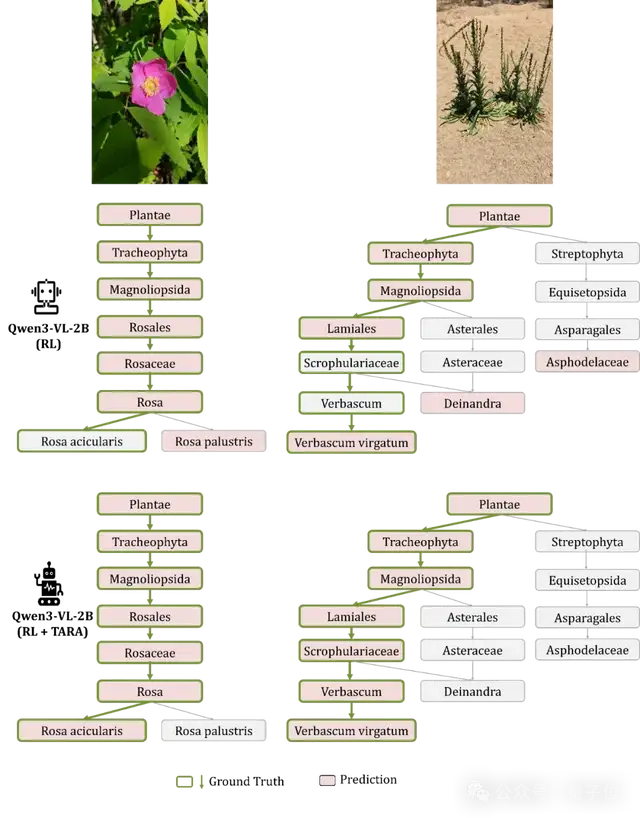
实验结果显示,这种方法不仅能增强现有大模型的细粒度视觉识别能力,提升最终的细粒度类别的识别准确率,还能增强分层视觉识别能力,从粗到细提升类别树上每一层的识别准确率。
为向多模态大模型注入类别树结构知识,本文提出了分类感知表征对齐方法TARA。如图2所示,TARA包含2个主要部分。

1. 分层视觉表征对齐:通过将大模型中间层与生物基础模型最后一层的视觉表征对齐,促进大模型提取具备完整类别树结构的视觉表征。
2. 自由粒度类别表征对齐:通过将大模型输出答案的首个词元表征与经生物基础模型编码后的真实类别表征对齐,促进大模型将具备完整类别树结构的视觉表征映射为对应层次的类别名称。

△图2. 分类感知表征对齐方法(TARA)框架图

1. 分层视觉表征对齐。
经分层类别标签训练的生物基础模型能够提供包含分类学信息的监督信号,促进大模型提取具备完整类别树结构的视觉表征。
实验结果
给定输入图像I和识别特定层次类别的问题q,生物基础模型的视觉编码器εv(·)输出目标视觉特征img=εv(I)∈RN×d,其中d表示生物基础模型的特征维度。
大语言模型第ℓ层的视觉表征表示为ℓimg∈RN×D,采用可学习的映射层PV(·)将其映射到生物基础模型的视觉特征空间,并最小化如下对齐损失:
2. 自由粒度类别表征对齐。
一张图像同时对应不同层次的类别标签,但用户期望识别的类别层次可能不同。
通过在同一层次上对齐生物基础模型和大模型的类别文本表征,促进大模型将具备完整类别树结构的视觉表征映射为对应层次的类别名称。
生物基础模型的文本编码器ET(·)输出目标文本特征ylabel=ET(C)∈Rd,其中C表示在期望层次上的真实类别名称。
大语言模型第m层的答案表征序列表示为emanswer∈RN′×D,采用可学习的映射层PT(·)将答案的首个词元表征映射到生物基础模型的文本特征空间,并最小化如下对齐损失:
项目价值
最终,TARA的对齐损失定义为两者的均值:
3. 模型训练和推理: