YuanLab.ai团队近日宣布,正式开源源Yuan3.0 Ultra这一多模态基础大模型。
作为源3.0系列的一部分,这款旗舰模型是目前仅有的三个达到万亿级参数规模的开源多模态大模型之一。
它通过引入MoE架构来优化训练效率,并针对企业应用及智能体工具调用进行了深入改进,在多模态文档理解、检索增强生成(RAG)、表格数据分析和内容摘要等领域表现出色。
该模型能够高效处理企业环境中的复杂信息,如图文混排的文档和多层次结构化的表格等,并支持基于OpenClaw等智能体框架构建的企业级Agent AI系统。
Yuan3.0 Ultra采用了一种统一的多模态架构来协调视觉与语言的信息建模。其中,语言处理网络采用了混合专家(MoE)设计,初始参数量为1515B,在训练过程中通过LAEP方法优化至1010B,预训练效率提高了49%。其激活参数规模为68.8B。
此外,该模型还引入了Localized Filtering Attention(LFA),有效增强了对语义关系的建模能力,并提升了模型的整体精度。
Yuan3.0 Ultra的发展路径体现了更高效率和更强智能的理念。
目前源Yuan3.0 Ultra已经全面开源,用户可以免费获取其参数和代码进行使用。
在企业环境中,Agent通常需要同时处理文档、表格等多种信息格式,并通过多步骤推理与工具调用完成任务。设计时充分考虑了这些需求。
大量关键业务信息存储在技术方案报告、财务报表以及行业研究材料中,往往包含复杂的图文结构和跨页面链接,给企业构建知识体系带来了挑战。
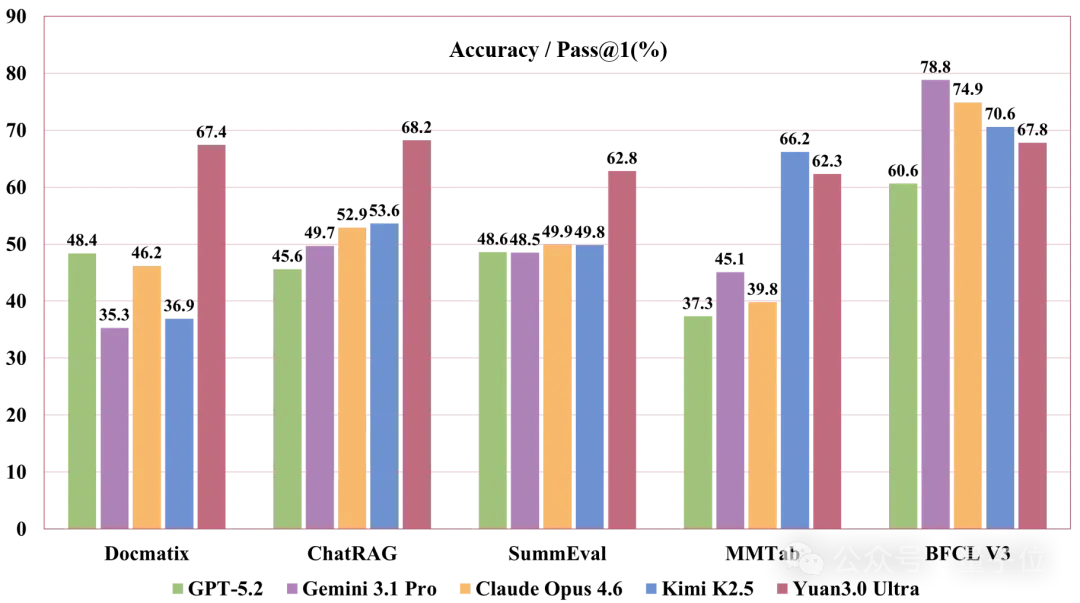
Yuan3.0 Ultra在多模态文档理解评估中的表现超越了Claude Opus 4.6、Gemini 3.1 Pro等前沿模型,在图文解析与表格语义分析方面展现出了卓越的能力。
模型能够准确地解析图文混排的结构,并提取关键数据指标,支持智能体系统高效完成文档理解、数据抽取和报告总结任务。
在企业内部,知识通常分散在各种文档库、知识管理系统及业务数据库中,信息来源复杂且缺乏统一的标准。
要有效地整合这些资源并进行综合分析,不仅需要强大的检索能力,还需要对多源内容进行语义上的整合。传统的检索系统往往只能返回零散的信息,难以形成完整的结论。
Yuan3.0 Ultra在基于检索的生成评估中表现出色,领先于Claude Opus 4.6、Gemini 3.1 Pro等最新模型,在深度语义整合和生成回答方面展现出明显优势。
模型能够在企业知识环境中完成从检索到理解再到综合生成的完整信息处理流程,支持OpenClaw等智能体利用私有知识解决复杂任务。
在企业运营场景下,许多业务决策依赖于数据库查询、报表分析以及跨系统数据整合。
这类工作通常需要将业务问题转换为SQL查询,并结合数据结果进行详细分析和报告编写。这一流程效率较低且耗时较长。
Yuan3.0 Ultra在Text-to-SQL基准测试中表现出色,优于Kimi K2.5、DeepSeek V3.2等前沿模型,在自然语言理解和结构化查询生成方面能力突出。
模型能够高质量支持OpenClaw等智能体的数据查询、运营分析以及报告制作任务,帮助企业构建基于这些智能体的业务决策系统。
在长期研究中发现,大模型预训练过程中的专家负载演变可以分为两个阶段:
- 初始过渡期:在早期预训练时,由于随机初始化的影响,每个专家所接收的token数量差异显著;
- 稳定期:此时各专家之间的token分配趋于稳定,但部分专家长期处于低负荷状态。
在这一阶段,模型内部算力资源分布极不平衡,少数专家承担了大量的计算任务。最高与最低负载的专家之间差距可达500倍。
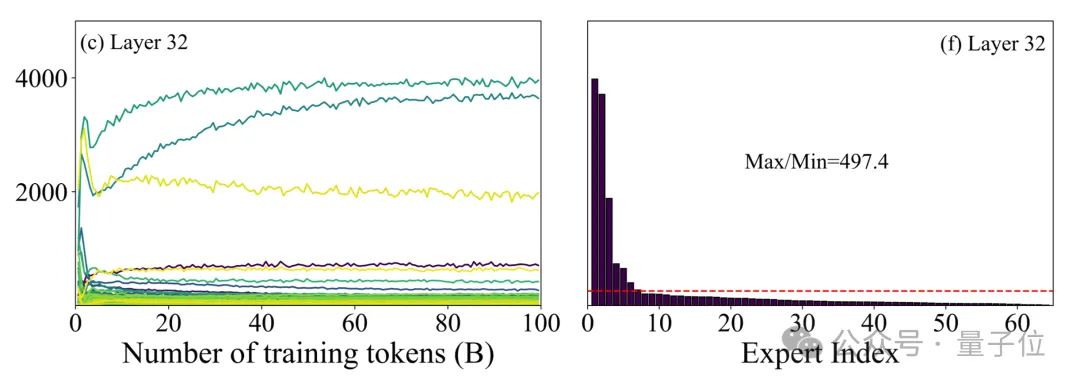 △MoE模型训练过程中存在专家训练不均衡问题
△MoE模型训练过程中存在专家训练不均衡问题从学习机制的角度来看,这种现象体现了大模型在训练中形成的“功能专一化”——不同专家逐渐对特定模式或结构产生偏好,在模型内部形成专业分工。
这种特性与人类大脑的认知组织方式相似。研究表明,人脑通过区分不同的神经元区域来优化信息处理效率,这类似于MoE架构中的专家分化现象。
为提高大规模MoE模型的计算效率并保持其专业化能力,需要识别和剔除冗余结构。
Yuan3.0 Ultra提出了Layer-Adaptive Expert Pruning(LAEP)算法来解决这一问题。该算法通过统计专家负载信息动态地调整模型结构,优化算力分配。
LAEP使计算资源集中于真正发挥作用的专家身上,避免了低效连接对整体性能的影响,提升了学习及计算效率。
这一过程类似于大脑在长期学习过程中对神经连接进行优化与重组,从而提升认知效率。
 △Yuan3.0 Ultra采用LAEP显著提升预训练效率
△Yuan3.0 Ultra采用LAEP显著提升预训练效率实验结果显示:
- Yuan3.0 Ultra通过LAEP算法减少了模型参数量,并提高了预训练效率。
- 未来的基础大模型结构设计及优化将更加关注如何利用训练中自然形成的专家分化来提高计算效率和学习能力。
Yuan3.0 Ultra采用了Fast-thinking强化学习范式,旨在减少无意义的推理步骤并提升整体精度。
在大规模强化学习过程中,团队围绕反思抑制奖励机制(RIRM)进行了优化设计。这种方法有助于模型在获得可靠答案后主动减少无效的反思过程,同时保持必要的复杂性以解决困难问题。
实验结果表明,在这种控制下的快思考策略下,模型精度显著提高且推理过程中生成的token数量持续下降,实现了准确性和计算效率的同时提升。
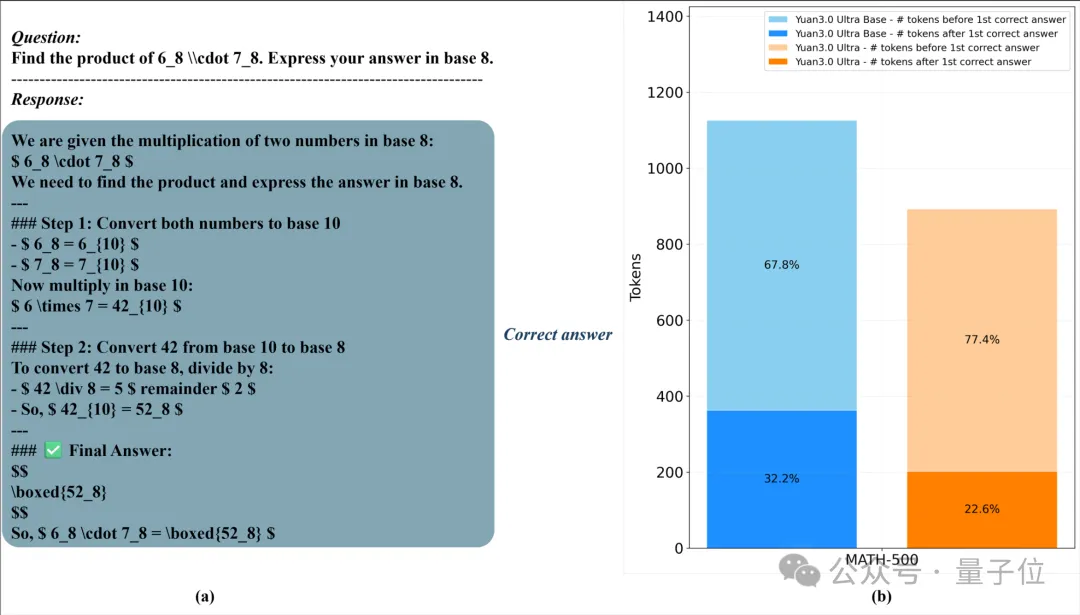 △RIRM优化下的推理效率提升与 Token 消耗对比
△RIRM优化下的推理效率提升与 Token 消耗对比Yuan3.0 Ultra大模型的开源包括了完整的训练方法、技术报告和评测结果。这将促进社区在此基础上进一步开发与行业定制化应用。
LAEP方法代表了团队对下一代基础大模型结构设计的新探索,为MoE架构创新及预训练效率提升开辟了新的路径。
通过开源源Yuan3.0 Ultra,研究团队旨在推动大型语言模型从“展示能力”向“规模化落地”的转变,为企业用户提供深度优化且面向Agent应用的多模态基础大模型解决方案。
Yuan3.0系列还将推出Flash、Pro和Ultra等多个版本,参数规模分别为40B、200B及1T等不同级别。相关成果将陆续公布。
另外,源Yuan3.0基础大模型将包含Flash、Pro和Ultra等版本,模型参数量为40B、200B和1T等,相关成果将陆续发布。
代码链接:https://github.com/Yuan-lab-LLM/Yuan3.0-Ultra
论文链接:https://github.com/Yuan-lab-LLM/Yuan3.0-Ultra/blob/main/Docs/Yuan3.0_Ultra%20Paper.pdf
Huggingface链接:https://huggingface.co/YuanLabAI/Yuan3.0-Ultra-int4
ModelScope链接:https://modelscope.cn/models/YuanLabAI/Yuan3.0-Ultra-int4
始智AI链接:https://www.wisemodel.cn/models/YuanLabAI/Yuan3.0-Ultra-int4