
“以图思量”的方法,即通过工具调用或代码生成等方式,在思考过程中引入辅助图像(如裁剪、标定、作辅助线等),已成为增强多模态大语言模型视觉推理能力的重要手段。这类方案虽然效果显著,但也带来了对外部工具的依赖性,导致了几个局限。
- 训练和推断复杂度高:在训练过程中,模型需要额外学习各种工具及函数接口的使用方式,增加了训练难度;同时,在多轮交互式推理中也延长了推断延迟时间。
- 可操作类型受限:受制于可用工具种类,这类方法难以应对更加复杂的任务挑战。
- 难以扩展为通用能力:每增加一类新的工具时都需要重新标注数据并设计接口,使得模型更像是一个“工具调度中心”,而非真正理解和创造性的思考者。
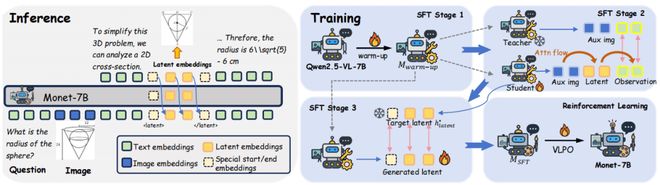
Monet提出了一种无需依赖外部工具或代码的直接在连续隐空间中进行视觉推理的新方法。通过生成连续的“隐式视觉嵌入”(latent visual embeddings),这种技术模拟人类脑海中绘制草图和进行空间想象的过程,从而将视觉思维能力内化为模型的一部分。该研究团队由北京大学博士生王启迅、史阳及来自Amazon AGI SF Lab的王一飞组成,指导教师包括快手可灵团队的张远行以及北京大学英向华、王奕森教授。这项工作已获得CVPR 2026会议接受。

- 论文标题:《超越图像和语言的隐式视觉推理》
- 论文地址:https://arxiv.org/abs/2511.21395
- 代码链接:https://github.com/NOVAglow646/Monet
- 模型链接:https://huggingface.co/NOVAglow646/Monet-7B
- 数据集链接:https://huggingface.co/datasets/NOVAglow646/Monet-SFT-125K
训练多模态模型进行隐式视觉推理的挑战。
多模态模型在训练过程中面临两大难点:
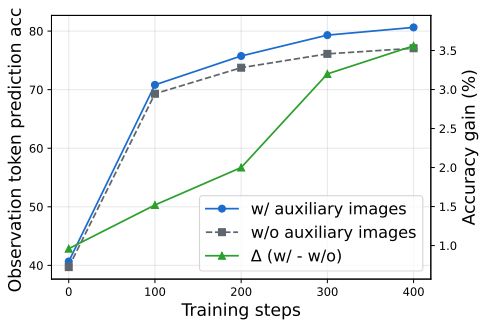
一是隐式嵌入(latent embedding)的监督信号难以获取。一种直观的方式是直接对齐生成的隐式嵌入和中间步辅助图像的表示,以使后者编码视觉信息。然而,由于辅助图像token数量庞大,这会带来高昂的成本,因此现有方法选择压缩图像token至10个左右或选取关键区域的部分token进行对齐,导致了细粒度视觉信息丢失。
二是隐式嵌入难以被优化。监督微调(SFT)过程中,“预测下一个词”的目标容易通过“记住”训练数据实现;强化学习(RL)中常规的GRPO仅在文本token上计算损失,使得奖励信号难以直接施加到隐式嵌入上。
方法概览:
监督微调+强化学习推动隐式视觉推理能力的发展
为了使模型能够自主决定何时启动隐式思考,并生成特殊标记(例如),作者提出了一种结合监督微调和强化学习的框架,以Qwen2.5-VL-7B为基底训练得到的新模型Monet-7B可以在推理过程中交替进行语言理解和视觉想象。
图1展示了左侧是Monet推理过程示意图。右侧则描绘了三阶段SFT与RL(VLPO为作者提出的新型强化学习算法)的过程概述。
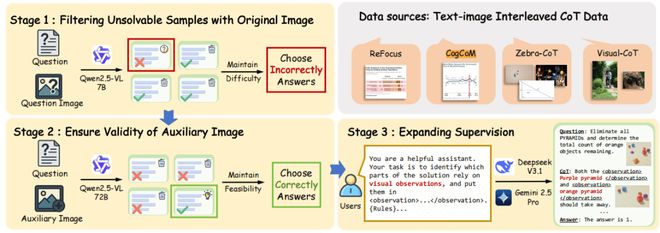
SFT数据集构建:Monet-SFT-125K
尽管当前存在许多公开的图文交错思维链的数据集,但它们普遍存在以下问题:
一、某些辅助图像缺乏必要性;二、一些辅助图像是不必要的;三、某些任务中使用了过多的辅助图。
数据集中的一些关键观察总结为:对于分布内任务而言,使用隐式思考确实能够提升性能;而对于分布外的任务,则只有经过特定训练后的模型才能展现出这种效果。此外,在测试时增加隐式嵌入数量对性能的影响也得到了研究,揭示了缩放定律的存在。
Monet在不同视觉推理任务上的表现
图6展示了内部分布感知和推理任务的性能(真实世界、图表、OCR等)。图7则显示了外部分布视觉推理测试的结果。研究结果显示,在各种任务中Monet-7B均超越了其他基准模型,与基线相比,在不同类型的任务上分别取得了3%~9.75%和2.31%的提升。
消融实验:作者通过全面消融实验验证了SFT阶段各个组件的重要性,并展示了所提出VLPO在SFT模型基础上进一步改进的效果。值得注意的是,基于Monet-SFT进行GRPO训练并未带来稳定的性能增益,这证明了GRPO的局限性。
探究隐式嵌入数量对视觉推理性能的影响
图9展示了测试时不同长度的隐式嵌入数对模型准确率的影响。核心观察表明:对于分布内任务而言,增加隐式思考的数量确实能提升性能;而在分布外的任务中,则只有经过VLPO训练后的模型才能表现出这种趋势。
[1] Yang Z, Yu X, Chen D, Shen M, Gan C. Machine mental imagery: Empower multimodal reasoning with latent visual tokens. arXiv preprint arXiv:2506.17218 (2025).
[2] Li B, Sun X, Liu J, Wang Z, Wu J, Yu X, Chen H, Barsoum E, Chen M, Liu Z. Latent visual reasoning. arXiv preprint arXiv:2509.24251 (2025).
监督微调:
[3] Shao H, Qian S, Xiao H, Song G, Zong Z, Wang L, Liu Y, Li H. Visual cot: Unleashing chain-of-thought reasoning in multi-modal language models. CoRR (2024)
SFT分成三个阶段。
[4] Li A, Wang C, Yue K, Cai Z, Liu O, Fu D, Guo P, Zhu W, Sharan V, Jia R, et al. Zebra-cot: A dataset for interleaved vision language reasoning. arXiv preprint arXiv:2507.16746 (2025).
[5] Fu X, Liu M, Yang Z, Corring J, Lu Y, Yang J, Roth D, Florencio D, Zhang C. Refocus: Visual editing as a chain of thought for structured image understanding. ICML (2025)
[6] Qi J, Ding M, Wang W, Bai Y, Lv Q, Hong W, Xu B, Hou L, Li J, Dong Y, et al. Cogcom: A visual language model with chain-of-manipulations reasoning. ICLR (2025).
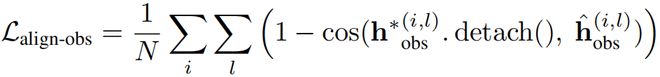

另外,为了使对齐损失确确实实是通过调整隐式嵌入而不是被“走捷径”优化的,作者提出让对齐损失的梯度仅能通过隐式嵌入流向模型参数。实现细节可见原文。

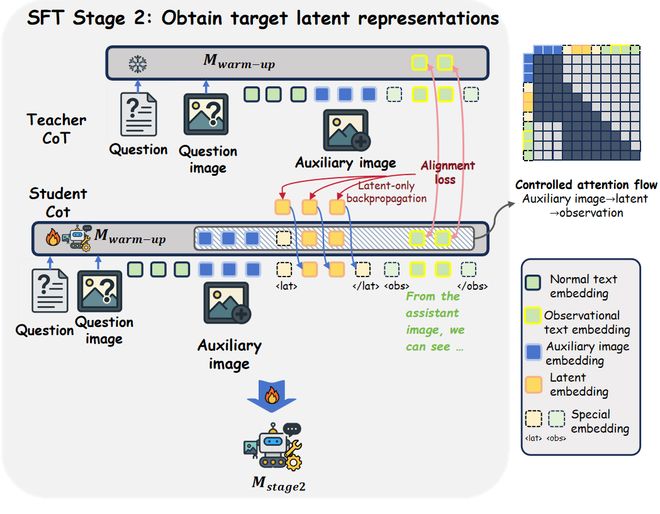
图4 SFT第二阶段示意。包含对齐损失和next-token-prediction损失两部分。其中Teacher CoT为包含辅助图像的图文交错CoT;Student CoT中辅助图像后为生成的隐式嵌入,且辅助图像能且仅能被隐式嵌入可见。
SFT第三阶段:让模型学会“从零开始”隐式思考。由于上一阶段隐式嵌入的产生是在隐式嵌入直接可见辅助图像的情况下的,这与实际应用时存在差异。
为此,在第三阶段中,作者将第二阶段训练后模型产生的高质量隐式嵌入作为目标,让模型在不可见辅助图像情况时产生的隐式嵌入与之对齐,如图5所示。
同时这一阶段仍包含next-token-prediction损失,以让隐式嵌入帮助后续推理。
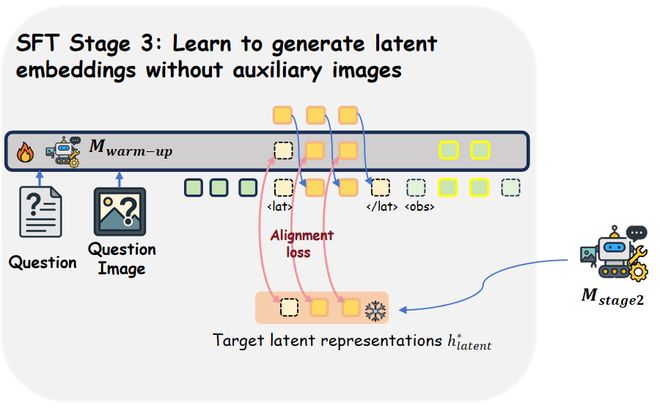
图5 SFT第三阶段示意。这一阶段的目标为对齐无辅助图像时产生的隐式嵌入和来自第二阶段的高质量目标隐式嵌入。VLPO:专为隐式思考设计的强化学习

为此,作者提出了VLPO(Visual-latent policy optimization),通过估计隐式嵌入的生成概率来将其纳入损失函数的计算之中。

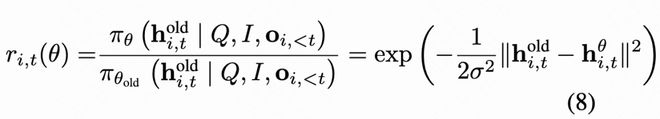

Monet带来了分布内和分布外视觉推理能力的提升
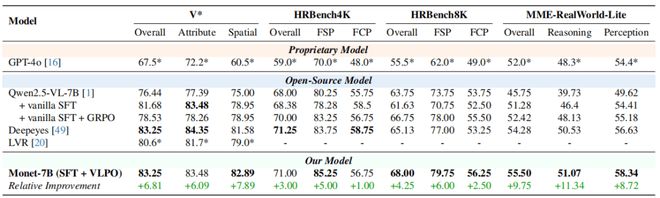
图6 分布内的感知和推理任务上的性能(真实世界、图表、OCR任务)
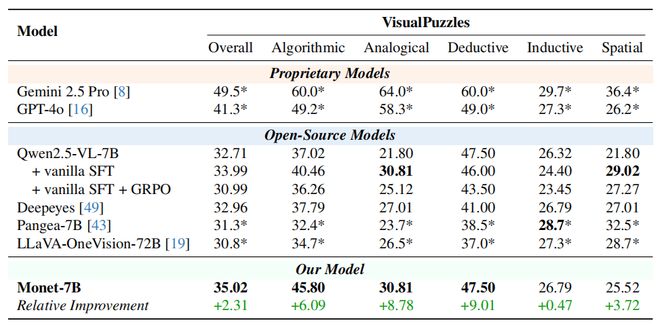
图7 分布外视觉推理任务上的性能(抽象视觉推理任务)
主要结果:作者在分布内任务(真实世界、图表、OCR)和分布外任务(抽象视觉推理)上测试了Monet-7B。
结果如图6和图7所示,Monet超过了SFT、SFT+GRPO以及现有的think with images和隐式视觉推理的基线。相比基模型,在分布内和分布外任务分别取得了3%~9.75%和2.31%的提升。
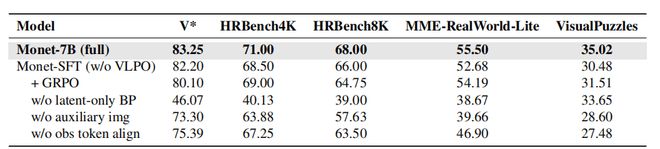
图8 消融实验。“Latent-only” BP为SFT阶段二中让对齐损失的梯度仅流向隐式嵌入的设计;“auxiliary img”为SFT阶段二中在student COT中引入辅助图像的操作。
消融实验:作者通过全面的消融实验验证了SFT阶段各组件的必要性,以及提出的VLPO在SFT模型(Monet-SFT)基础上带来的进一步提升。
值得注意的是,在Monet-SFT基础上进一步进行GRPO并不能带来稳定的提升,印证了GRPO的局限性。
探究隐式嵌入数量对性能的影响

图9 横轴:测试时隐式嵌入数量。纵轴:测试准确率。三条绿色线为Monet-SFT模型,训练时隐式嵌入数量分别为8、10、12;蓝色为SFT(K=8)+VLPO(K=10);粉色为SFT(K=8)+GRPO.
作者探究了不同的训练时和测试时隐式嵌入数量K对性能的影响。核心观察总结如下:
- 对于分布内任务,使用隐式思考确实相比纯文本思考能带来提升;对于分布外任务,只有经过VLPO训练的模型的隐式思考能相比纯文本带来额外提升。
- 对于分布内任务,Monet-SFT模型展现出了测试时的缩放定律(test-time scaling law):测试时随着隐式嵌入数量(甚至远超训练时所见到的长度)增加性能上升;对于分布外任务,只有VLPO展现出了这一趋势;
- GRPO主要提升非隐式思考的性能(测试时latent size=0),而对于隐式思考(测试时latent size>0)提升不明显。
更多细节请参考原文。
参考文献:
[1] Zeyuan Yang, Xueyang Yu, Delin Chen, Maohao Shen, and Chuang Gan. Machine mental imagery: Empower multimodal reasoning with latent visual tokens. arXiv preprint arXiv:2506.17218, 2025.
[2] Bangzheng Li, Ximeng Sun, Jiang Liu, Ze Wang, Jialian Wu, Xiaodong Yu, Hao Chen, Emad Barsoum, Muhao Chen, and Zicheng Liu. Latent visual reasoning. arXiv preprint arXiv:2509.24251, 2025.
[3] Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Unleashing chain-of-thought reasoning in multi-modal language models. CoRR, 2024
[4] Ang Li, Charles Wang, Kaiyu Yue, Zikui Cai, Ollie Liu, Deqing Fu, Peng Guo, Wang Bill Zhu, Vatsal Sharan, Robin Jia, et al. Zebra-cot: A dataset for interleaved vision language reasoning. arXiv preprint arXiv:2507.16746, 2025.
[5] Xingyu Fu, Minqian Liu, Zhengyuan Yang, John Corring, Yijuan Lu, Jianwei Yang, Dan Roth, Dinei Florencio, and Cha Zhang. Refocus: Visual editing as a chain of thought for structured image understanding. In ICML, 2025
[6] Ji Qi, Ming Ding, Weihan Wang, Yushi Bai, Qingsong Lv, Wenyi Hong, Bin Xu, Lei Hou, Juanzi Li, Yuxiao Dong, et al. Cogcom: A visual language model with chain-ofmanipulations reasoning. In ICLR, 2025.