YuanLab.ai团队近日正式发布了源Yuan3.0 Ultra多模态基础大模型的开源代码。
作为源3.0系列中的旗舰产品,源Yuan3.0 Ultra是全球少数几个可以公开获取的万亿级参数规模的大模型之一。
源Yuan3.0 Ultra在设计上引入了混合专家(MoE)架构,并针对企业应用和智能体工具调用进行了优化,在多模态文档理解、检索增强生成、表格数据分析以及内容摘要等方面表现出色。
这些能力使源Yuan大模型能够高效处理企业在复杂信息环境中的各种挑战,包括图文混排的文件和多层次结构的表格等,并为基于OpenClaw框架构建的企业级多模态AI提供强大支持。
Yuan3.0 Ultra采用了统一的多模态模型架构,实现了视觉与语言数据的有效结合。其初始参数量为1515B,在LAEP技术优化后减少至1010B,并提升了49%的训练效率。
该版本还引入了Localized Filtering Attention机制,增强了对语义关系的理解能力,相比传统Attention结构在精度上有所提升。
Yuan3.0 Ultra为大模型的发展提供了新的路径:更高效率和更强智能。
目前,Yuan3.0 Ultra已经全面开源,用户可以免费下载其参数和代码以进行二次开发和使用。
企业级多模态处理能力
Yuan3.0 Ultra在设计时充分考虑了企业真实业务流程中的需求,能够有效应对文档、表格及数据库等多种信息形式的挑战,并支持通过多步骤推理与工具调用来完成复杂的任务。
复杂文档和图表的理解
在企业的日常运作中,大量的关键信息往往嵌入在技术方案、财务报告等文件之中。这些内容通常包含图文混排结构及复杂的表格数据,是企业构建知识体系中的难点所在。
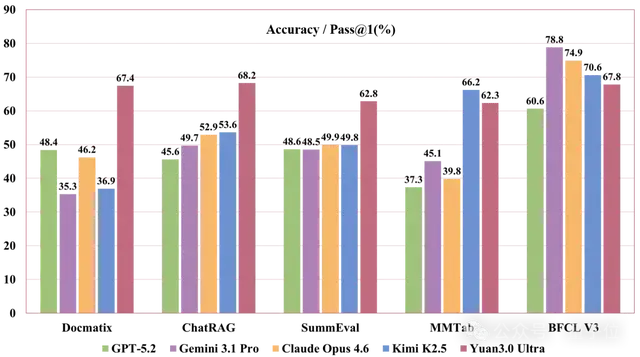
Yuan3.0 Ultra在多项多模态文档理解评估测试中表现出色,并优于其他同类模型,在解析图文混合信息和表格语义方面具有明显优势。
该能力使其能够精准提取并解析复杂的文档结构,支持智能体系统高效完成任务如财务分析、合同审查等,从而大幅提高企业处理信息的效率。
多源信息检索与整合
企业内部知识资源分散且复杂
在这种环境下,仅仅依靠检索是不够的,还需要对多源内容进行语义整合与综合分析。然而传统的检索系统通常只能提供零散的结果,难以形成完整的结论。
Yuan3.0 Ultra在多个检索增强生成评测中表现出色,并优于其他前沿模型,在基于检索结果生成深度语义回答的能力方面具有显著优势。
依托这一能力,该模型可以在企业知识环境中实现从检索到理解再到综合生成的完整信息处理流程,支持智能体使用私有知识完成复杂任务。
数据分析与业务决策支持
在企业的日常运营中,大量的业务决策需要依赖于数据库查询、报表分析和跨系统的数据整合工作。
Yuan3.0 Ultra在Text-to-SQL基准测试中表现出色,在Spider评测中领先其他大模型,展示了其在自然语言理解与结构化查询生成方面的强大能力。
该能力使模型能够高效支持OpenClaw等智能体进行数据查询、业务分析及报告生成等工作,为企业构建基于这些技术的决策系统提供强有力的支持。
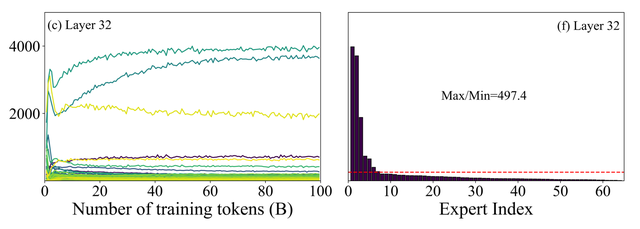
研究团队发现,在大模型预训练过程中存在专家负载不均衡的问题
这一现象反映了模型在长期训练中形成的功能专化趋势,不同专家开始对特定模式或任务类型产生偏好,形成了类似大脑功能区域化的分工结构。
Yuan3.0 Ultra提出了Layer-Adaptive Expert Pruning(LAEP)算法来解决这一问题
- 该方法通过动态识别低效的专家并调整模型结构,使计算资源能够更加集中地利用在真正发挥作用的部分上。
- LAEP显著提高了Yuan3.0 Ultra的预训练效率,并减少了参数规模的同时保持了模型的专业化能力。
这项研究也揭示了一个重要的方向:未来的基础大模型设计和优化需要更多考虑结构上的分工与专业化,以进一步提高学习及计算效率。
Yuan3.0 Ultra采用Fast-thinking强化学习策略
该版本的训练方法侧重于高效的短路径推理方式,在大规模强化学习过程中引入反思抑制奖励机制(RIRM),有效地减少了模型在得到可靠答案后继续进行无效思考的行为,同时保持必要推理深度。
这一优化措施显著提升了模型的推理效率并降低了计算成本,实现了精度与性能的双重提升。
YuanLab.ai团队通过全面开源Yuan3.0 Ultra大模型,旨在推动其在实际场景中的广泛应用
除了公开源代码和预训练权重外,还包括技术报告、完整的训练方法以及详细的评测结果,为社区提供了广泛的支持和资源进行二次开发及行业定制。
Yuan3.0 Ultra的发布标志着大模型从展示能力阶段向实际落地应用阶段转变的重要一步,为企业提供了一款深度优化并面向Agent应用的基础大模型。
源Yuan3.0系列包含Flash、Pro和Ultra等多个版本,覆盖了不同的参数规模需求,更多成果将陆续公布。

Yuan3.0 Ultra采用LAEP显著提升预训练效率
实验结果显示:
- 模型参数减少33.3%
- 整体预训练效率提升49%
这一研究也揭示了一个重要现象:大模型结构不应只是简单扩大参数规模,而应逐渐演化为具有结构分工与专业化能力的“认知系统”。如何利用训练过程中自然形成的专家分化,并通过结构优化进一步提升学习及计算效率,将成为未来基础大模型结构设计及优化的一个重要方向。
不追求“更长思考”,而是“更有效思考”
Yuan3.0 Ultra的训练策略聚焦于Fast-thinking强化学习范式。与单纯延长推理链条不同,模型默认采用高效的短路径推理方式,使计算资源优先用于高信息增益的步骤,而非无约束的反思扩展。
在大规模强化学习过程中,团队围绕反思抑制奖励机制(RIRM)进行了系统优化,通过对反思次数引入奖励约束,使模型在获得可靠答案后主动减少无效反思,同时在复杂问题中保留必要的推理深度。这一机制有效缓解了快思考模式下的“过度思考”(overthinking)现象。
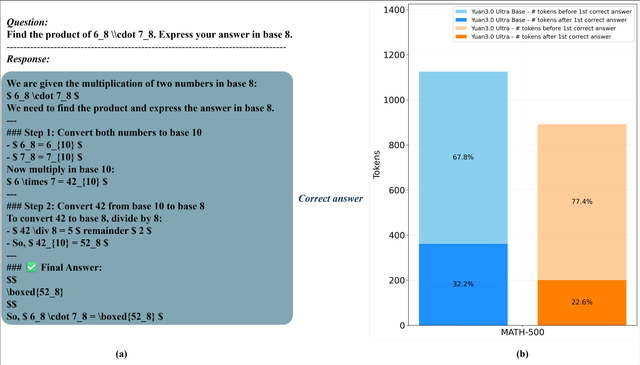
RIRM优化下的推理效率提升与Token消耗对比
训练结果表明,在这一受控快思考策略下,模型精度显著提升,同时推理过程中生成的token数量持续下降,实现了准确性与计算效率的同步优化。
开源基础模型,推动可落地的大模型智能
Yuan3.0 Ultra大模型全面开源,不仅包括模型权重(16bit与4bit模型)、技术报告,也涵盖完整的训练方法与评测结果,支持社区在此基础上进行二次训练与行业定制。
其中模型提出的LAEP方法是YuanLab.ai团队对下一代基础大模型结构的又一次探索与实践,为业界MoE大模型结构创新、预训练算力效率提升带来新的路径。
团队希望通过Yuan3.0 Ultra的开源,推动大模型从“能力展示”走向“规模化落地”,为企业用户提供深度优化的、面向Agent应用的多模态基础大模型。
另外,源Yuan3.0基础大模型将包含Flash、Pro和Ultra等版本,模型参数量为40B、200B和1T等,相关成果将陆续发布。
代码链接:https://github.com/Yuan-lab-LLM/Yuan3.0-Ultra
论文链接:https://github.com/Yuan-lab-LLM/Yuan3.0-Ultra/blob/main/Docs/Yuan3.0_Ultra%20Paper.pdf
Huggingface链接:https://huggingface.co/YuanLabAI/Yuan3.0-Ultra-int4
ModelScope链接:https://modelscope.cn/models/YuanLabAI/Yuan3.0-Ultra-int4
始智AI链接:https://www.wisemodel.cn/models/YuanLabAI/Yuan3.0-Ultra-int4