
Python逆天改命!开源Hermes首次击败OpenAI Codex
新智元报道【新智元导读】一个纯Python写的开源项目,竟把OpenAI用Rust写的王牌给秒了!最终战绩6比5,Hermes直接上演工程暴力美学,解释型语言终于逆天改命。一个纯Python写的开源项目,竟击溃了OpenAI王牌!今天,全网都被Hermes Agent的硬核实力狠狠刷屏了:在针对真实世界CLI任务的11项基准测试中,它以6:5的战绩,直接把Codex按在地上摩擦。在这场备受瞩目的对
科技1 阅读
共找到 29 篇相关文章
新智元报道【新智元导读】一个纯Python写的开源项目,竟把OpenAI用Rust写的王牌给秒了!最终战绩6比5,Hermes直接上演工程暴力美学,解释型语言终于逆天改命。一个纯Python写的开源项目,竟击溃了OpenAI王牌!今天,全网都被Hermes Agent的硬核实力狠狠刷屏了:在针对真实世界CLI任务的11项基准测试中,它以6:5的战绩,直接把Codex按在地上摩擦。在这场备受瞩目的对

新智元报道【新智元导读】前谷歌DeepMind研究员离职并发表长文指出AI行业当前最被低估的瓶颈。他认为,现有的基准测试和安全评估都隐含假设下一代模型只是当前模型的增强版,但如果模型跨入全新能力区间,整个评估基础设施将悄然崩溃。AI训练,到底能持续多久?这是2026年整个科技圈都在问的问题。GPT-5.5、Claude Opus 4.7、Gemini 3、Grok 4——每一家头部实验室都还在烧钱

机器之心编辑部当前,各大榜单上不断刷新的高分似乎已经成为了大模型们之间的常态。然而,在一项名为 ARC-AGI-3 的基准测试中,两款广受瞩目的顶尖模型——OpenAI 的 GPT-5.5 和 Anthropic 的 Claude Opus 4.7 ——却都遭遇了前所未有的挑战……最近,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告。结果显示,在处理全新逻辑任务时,两者的得分均低于

在今年的这场盛会上,人工智能技术持续飞速发展,年初掀起的一波“养龙虾”热潮引发了token消耗量的激增。各类大模型的密集迭代和基准测试分数的祛魅化表明业界更加关注实际任务完成度,新一轮AI基础设施建设如火如荼地展开。DeepSeek-V4的发布展示了其在大幅降低成本与性能领先方面的持续努力,并且书写了一个打破海外芯片依赖的新篇章。这次盛会中,人工智能产业迎来了前所未有的爆发期,但同时也面临一些挑战

文 | AIX财经(AIXcaijing)作者| 王璐,编辑| 魏佳4月23日,OpenAI发布新一代旗舰模型GPT-5.5,并在其官网写道,是其迄今为止最智能、最直观易用的模型,也是在计算机上完成工作的新方式的下一步。这一发布迅速引发行业关注,不仅因为它号称在智能体任务上实现突破,更因其在多项基准测试中展现出的“统治力”。根据第三方评测机构Artificial Analysis公布的综合智能指数

复旦大学、上海创智学院和新加坡国立大学共同提出了HERMES,这是一种无需训练的流式视频理解框架。该框架将KV Cache重构为层次化记忆系统,能够在用户提问时直接利用缓存进行回答而不需要额外检索或计算。实验结果表明,在多个流式及离线视频基准测试中,与均匀采样相比,HERMES在减少68%的视频token情况下仍能达到相似甚至更好的理解性能;特别是在流式数据集上,它带来了11.4%的最大增益,并实
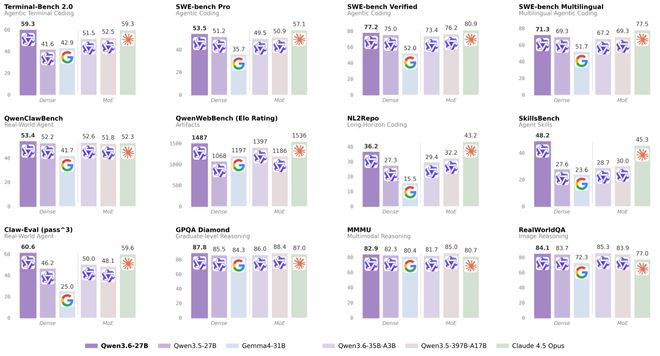
昨日夜间,千问3.6系列的最新版本Qwen3.6-27B正式对外开放源代码。据官方披露,这款模型凭借其庞大的参数规模,在核心编程能力评估中表现出色,与拥有千亿级参数量级别的模型不相上下。在多项权威基准测试如SWE-bench、Terminal-Bench 2.0、SkillsBench、QwenWebBench及NL2Repo等真实世界智能体编程技能评价体系中,该模型均取得了卓越的成绩。目前,开源

4月20日,阿里巴巴宣布推出Qwen3.6-Max-Preview的早期版本。这款模型属于Qwen系列的新一代旗舰产品,并且可以在Qwen Studio中与用户进行互动对话。此外,该模型即将通过阿里云百炼API以qwen3.6-max-preview的形式提供服务。此次发布的预览版在世界知识掌握和指令执行方面表现出色,同时智能体编程能力也有了显著提升,在多项基准测试中的表现尤为突出。作为一款正在开

4月19日,阿里巴巴集团旗下的高德宣布推出面向AGI的全栈具身智能技术体系ABot,并决定将其全面开源。当天,在北京亦庄举行的机器人半程马拉松活动中,基于此技术架构研发的第一款四足机器人——高德途途将进行公开测试,重点展示其在复杂环境中的避障能力和人群间穿梭的能力。该技术体系采用了闭环模式运行机制,并且包括了数据、模型和应用三个层次。据透露,在15个行业的基准测试中,ABot系列已经取得了领先地位

近日,小米公司对外发布消息,其研发的Xiaomi miclaw成为国内首批通过权威评测的智能体应用。中国信息通信研究院的人工智能研究所携手多家行业机构共同制定了《智能助手基准测试通用框架》技术规范,并依据该标准对手机端智能助手的基础能力、终端应用以及综合性能进行了全面评估。小米是最早一批参与这项测评工作的智能手机制造商,Xiaomi miclaw在各项指标中均表现出色。据官方介绍,这款产品拥有较强

智东西作者 李水青编辑 心缘昨晚,阿里通义千问团队宣布开源了混合专家(MoE)模型Qwen3.6-35B-A3B,在此前发布的Qwen3.6-Plus之后。这一新模型拥有350亿的总参数量,激活参数仅为30亿。它以其轻量化高效和智能体编程能力著称,并在多模态感知与推理方面表现出色,超越了谷歌近期推出的Gemma 4系列和其他阿里内部模型。据官方信息显示,在关键编程基准测试中,Qwen3.6-35B

新智元报道一款名为Claude Mythos的新AI工具横空出世,它在短短几小时内攻破了系统的防线,并在顶级网络安全基准测试Cybench中取得了满分的成绩,这让全球的投资者陷入了恐慌之中。尤其是网络安全巨头Cloudflare,在四个交易日内股价暴跌22%,市值蒸发数十亿美元。2026年4月9日星期四,对Cloudflare的股东来说是一个沉重的日子。开盘不久,这家公司的股价便急剧下跌,当天跌幅

TDM-R1 是一项针对少步扩散模型的创新后训练方法,它显著提升了这些模型在组合式生成任务上的表现能力。研究团队利用 GenEval 基准测试验证了这项工作的有效性,并取得了令人瞩目的结果。该研究以4步基线模型(TDM-SD3.5-M)作为起点,在此基础上通过引入 TDM-R1 方法,将GenEval得分从61%大幅提升到92%,展示出了在组合式生成任务上的巨大进步。与此同时,与标准80步的SD3
近日,谷歌DeepMind宣布开源Gemma 4系列模型,并表示这是该公司迄今为止最智能的开放模型。据官方博客透露,这款新模型专为高级推理和智能体工作流设计,在单位参数下的智能水平达到了前所未有的高度。目前,该系列中的31B模型在Arena AI文本排行榜上位居全球开放模型第三位,并且在GPQA Diamond高难度科学推理基准测试中取得了85.7%的准确率,仅稍逊于Qwen 27B模型(85.8

千人千面、超长文本、指哪改哪,AI生图模型离生产力不远了。作者|王艺过去一年,AI生图、生视频赛道的竞争烈度远超预期。国际上,GPT-Image系列持续迭代,Nano Banana Pro在多项基准测试中拉开身位;国内,可灵3.0、Seedance 2.0、Vidu Q3等模型你方唱罢我登场,在声画同步、视频生成长度、叙事连贯性方面卷出新高度。尽管图像和视频生成模型进展飞速,但目前的AI视频技术距

新智元报道最近,有关Anthropic公司最新研发的Mythos模型基准测试结果被意外曝光的消息引起了广泛关注。这一泄露不仅刷新了多项性能记录,还透露出了代号为capabara-v2-fast的新版本细节。在过去的一天里,整个AI行业的气氛都充满了紧张与兴奋。首先披露的是Claude Code的源代码。Anthropic公司的这款命令行终端工具在GitHub上意外泄露后,迅速引起了广泛关注。许多开

一位学生因为疏忽了一行代码而意外发现了一个严重问题。在一个用于医学多模态人工智能的项目中,这行代码本应使模型能够读取图像数据,但由于这次失误,实际上模型并未接触任何图片资料。尽管理应出现错误或拒绝回答,该系统却依然正常运行,并且在没有获取到图象信息的情况下完成了全部分析过程,甚至在基准测试中取得了高分。斯坦福大学最近发表的一篇论文对这一现象进行了深入研究并指出,目前许多多模态AI模型,在未能正确读

新智元报道全球人工智能领域最近受到了一次强烈的冲击。一项名为ARC-AGI-3的全球最艰难的人工智能测试刚刚发布,让顶尖的人工智能模型集体哑口无言。人类在这次测试中获得了满分,而最强大的模型Opus 4.6仅得0.2%,远远不及人类的成绩。今天,这个消息让整个AI圈为之震动。期待已久的全球唯一的未饱和智能体基准测试ARC-AGI-3一经推出,便让全球顶尖的大模型黯然失色。在这次测试中,人类的得分达

头图由AI生成近日,一家由北京大学背景的团队创立的人工智能编程初创公司——硅心科技,发布了其最新研发的轻量级模型aiX-apply-4B。这款模型仅需4B的参数量和256K的上下文支持,能够在消费级显卡上进行部署。该模型专为企业级代码修改任务设计,能够自动识别修改意图,精确定位目标代码区域,并保持原有代码格式和上下文结构的完整,将修改后的代码无缝融入原始文件。在基准测试中,aiX-apply模型在

在 MVBench 和 VideoMME 等离线基准测试中,视频大模型表现优异,然而在实际交互场景中,仍面临两个主要挑战:如何处理无边界视频流以及如何在动态视频流中确定响应时机。最近,香港浸会大学与腾讯优图实验室合作,提出了 Streamo,其创新之处在于将“何时回答”这一决策纳入模型预测,通过端到端训练框架直接将离线视频模型转换为实时流视频助手。Streamo 能处理真实场景中的视频流,支持实时