
新智元报道
全球人工智能领域最近受到了一次强烈的冲击。一项名为ARC-AGI-3的全球最艰难的人工智能测试刚刚发布,让顶尖的人工智能模型集体哑口无言。人类在这次测试中获得了满分,而最强大的模型Opus 4.6仅得0.2%,远远不及人类的成绩。
今天,这个消息让整个AI圈为之震动。
期待已久的全球唯一的未饱和智能体基准测试ARC-AGI-3一经推出,便让全球顶尖的大模型黯然失色。
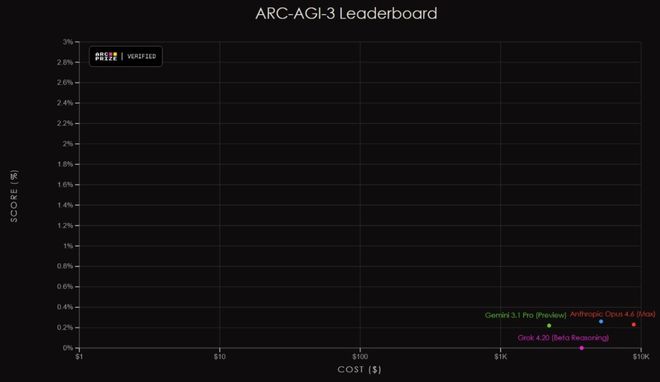
在这次测试中,人类的得分达到了100%,而AI的得分普遍低于1%。

这种差距,几乎如同珠穆朗玛峰般不可逾越。
最令人震惊的是,曾经在上一代测试中取得69.2%高分的Opus 4.6,在这次测试中仅获得0.2%的得分。
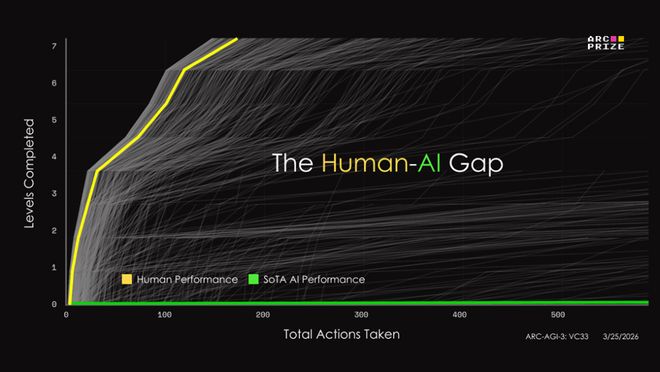
这位曾经在各大排行榜上横扫一切的「学霸」,在这次测试中甚至连蒙带猜都拿不到一分。
这个测试就像一面镜子,揭示了当前AI技术中最深层的缺陷。
在最近的一次采访中,老黄表示他认为AGI已经实现了。然而,ARC-AGI-3的测试结果表明,目前的人工智能可能连1%的AGI水平都未能达到。
ARC-AGI-3,究竟有多难?
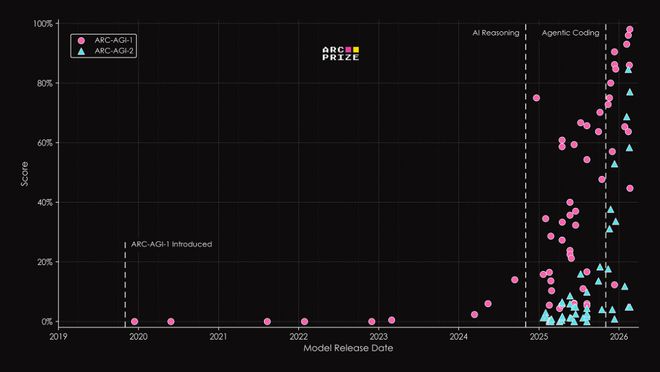
它的前身ARC-AGI-1和ARC-AGI-2在AI圈内早已享有「魔鬼测试」的恶名。
在那些测试中,AI需要通过观察几个示例,推断出网格变换的规律,从而完成新的任务。
听起来并不复杂?但这些看似简单的题目曾让无数的大模型铩羽而归。
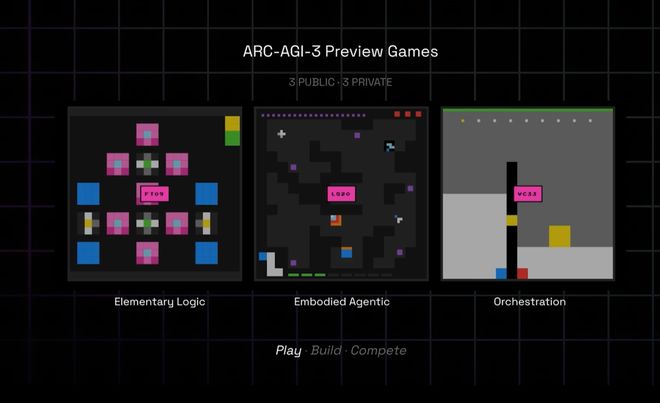
到了ARC-AGI-3,难度更是上了一个台阶:从「静态题」变成了「互动游戏」。
测试包括150多个精心设计的交互式游戏环境,以及1000多个关卡。
每个游戏都有其独特的内在逻辑、隐含规则和通关条件,但没有任何明确的说明文档或自然语言提示。

AI智能体被放置在这些游戏中,只能通过观察当前画面,选择动作,观察结果,再决定下一步行动。
它们只能像盲人摸象一样,一点点地探索,试图在脑海中构建出一个「这个世界可能是这样运作的」模型。

这正是ARC Prize基金会所期望测试的四个方面。
- 探索:是否能够通过主动与环境互动来获取关键信息?
- 建模:能否将零散的观察组合成一个可以预测未来状态的世界模型?
- 目标获取:在没有明确指令的情况下,能否自主判断出应该追求的目标?
- 规划与执行:是否能够规划出行动路径,并根据环境反馈及时调整?
几何级数的羞辱:0.2%是如何来的?
评分标准同样残忍。
ARC-AGI-3的评分标准不考虑「是否通关」,而是关注「效率」,并且与人类的效率进行比较。
这种评分方式在AI基准测试的历史上尚属首次。
受Chollet那篇《论智能的衡量》的启发,ARC Prize团队将「智能」量化为一个转换率:
即从环境中获取信息的效率以及将这些信息转化为正确行动的速度。
假设人类解决某个游戏需要10步,而AI用了100步,那AI的得分是多少?
不是10%,而是1%。
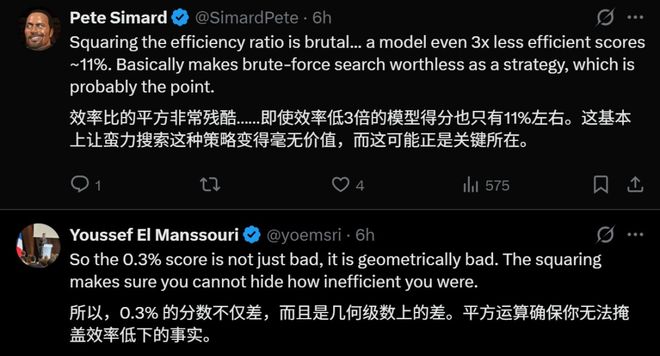
计算公式为:(人类步数/AI步数)²。即(10/100)²=0.01=1%。
如果AI用了200步,那得分就是0.25%;如果用了500步,得分就是0.04%。

这种评分方式彻底堵住了所有依赖「蛮力」的AI策略。
以前的AI可以通过穷举所有可能的操作来找到正确路径。
然而,在这种评分体系下,多试一步就会导致分数断崖式下跌。
如今,Opus 4.6仅得0.2%的意义在于——
假设人类解决某个游戏用了10步,0.2%=0.002,开平方≈0.0447,10÷0.0447≈224步。
这已经不是「笨」的问题,而是像在迷宫里原地踏步。
当这种差距被如此强烈地展现出来,很多原本认为AGI即将实现的人,都感到震惊。
350步 vs 两三下:全面的成绩单
在正式发布前,ARC-AGI-3进行了一轮为期30天的开发者预览。
三款公开游戏从地图导航到图案匹配再到水位调节,题目类型各异,但共同点是:人类觉得简单,AI觉得艰难。


1200多名人类玩家参与了测试,完成了3900多场游戏。
大多数人不仅轻松过关,还玩得很开心。有些玩家甚至一路「速通」挑战到了理论最优步数。
人类基线:100%。AI这边,前沿大模型得分全部低于1%。
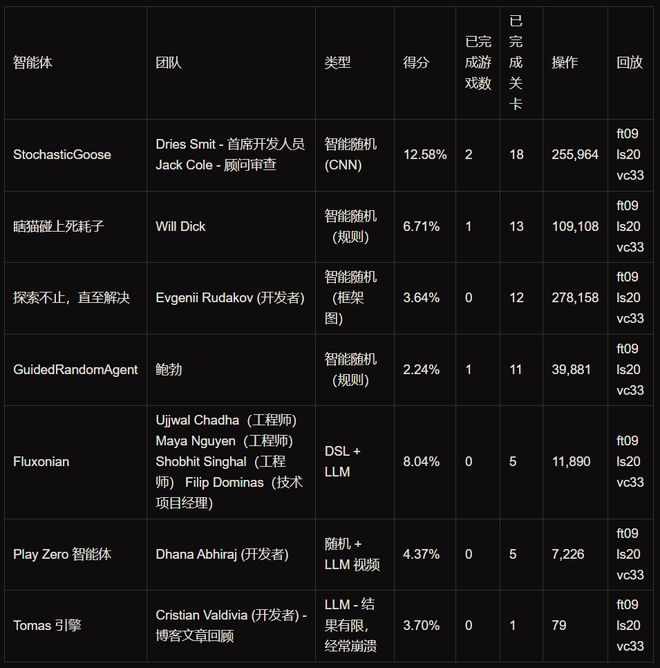
预览期的冠军是来自Tufa Labs的StochasticGoose。
它不是大模型,而是一个基于卷积神经网络的动作学习型智能体,通过简单的强化学习来预测哪些操作会导致画面变化。最终得分12.58%,是所有参赛系统中最高的。
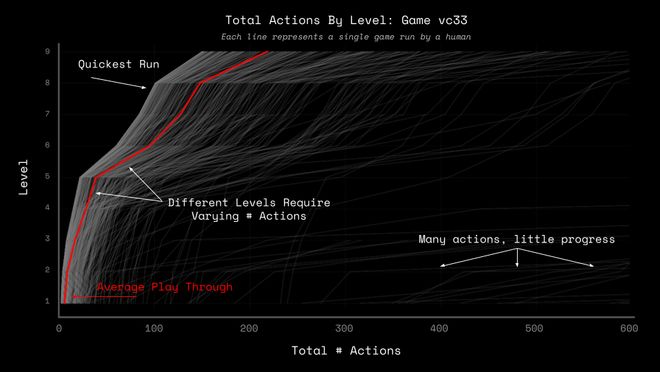
即便是这个冠军,也在一款调水位的游戏里开局时花了将近350步做无效的点击操作。
350步,而人类只需要两三步。
轻量级的CNN智能体和图搜索系统在这些测试中表现更好,因为它们没有「先入为主」的包袱,能够从环境反馈中学习。
为什么人类能轻松通关?
AI把自己坑了
ARC团队在文档中写了一句话:「人类不会蛮力行事。他们会构建思维模型,检验想法,并迅速改进。」
首先,人类会构建思维模型。
人类玩家面对一个全新游戏时,第一步不是「瞎点」,而是观察。几分钟之内,一个粗糙但可用的「世界模型」就建成了。
第二步,人类会检验想法。
如果结果和预期一致,模型得到强化。如果不一致,立即修正。
第三步,人类会迅速改进。错了就改,改了再试。
这种「探索-建模-验证-修正」的循环,在人类身上几乎是本能的。
而AI呢?只是一个「记住了很多答案」的应试高手,它的「学习」方式与人类完全不同。
人类的学习是在线、交互、假设驱动的;AI的学习是离线、数据驱动、模式匹配的。
ARC-AGI-3没有任何「题海战术」可以覆盖,它考的是「怎么学习」,而这恰恰是目前AI最弱的一环。
目前,这场挑战赛的奖金池高达85万美元,其中70万美元是给「满分通关者」的终极大奖。
参赛者必须完全开源代码,并且在无网环境下接受评估。这意味着你不能偷偷调用云端大模型,不能偷偷联网查资料。
与人类这个珠穆朗玛峰的差距,有AI能克服吗?
首先第一步,人类会构建思维模型。
一个人类玩家面对一个全新游戏时,第一件事不是「瞎点」,而是观察。几分钟之内,一个粗糙但可用的「世界模型」就建成了。
第二步,人类会检验想法。
如果结果和预期一致,模型得到强化。如果不一致,模型立即修正。
第三步,人类会迅速改进。错了就改,改了再试。
这种「探索-建模-验证-修正」的循环,在人类身上几乎是本能的。
而AI呢?只是一个「记住了很多答案」的应试高手,它的「学习」和人类的「学习」根本不是一个物种。
人类的学习是在线、交互、假设驱动的;AI的学习是离线、数据驱动、模式匹配的。
ARC-AGI-3没有任何「题海战术」可以覆盖,它考的是「怎么学习」。这恰恰是目前AI最弱的一环。
目前,这场挑战赛的奖金池高达85万美元,其中70万美元是给「满分通关者」的终极大奖。
参赛者必须完全开源代码,并且在无网环境下接受评估。这意味着你不能偷偷调用云端大模型,不能偷偷联网查资料。

和人类这个珠穆朗玛峰的差距,有AI能克服吗?
让我们静待结果。
参考资料:
https://x.com/Hesamation/status/2036861818321146306
https://arcprize.org/arc-agi/3
https://docs.arcprize.org/
https://x.com/fchollet/status/2036881543973790004