
机器之心编辑部
当前,各大榜单上不断刷新的高分似乎已经成为了大模型们之间的常态。然而,在一项名为 ARC-AGI-3 的基准测试中,两款广受瞩目的顶尖模型——OpenAI 的 GPT-5.5 和 Anthropic 的 Claude Opus 4.7 ——却都遭遇了前所未有的挑战……
最近,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告。结果显示,在处理全新逻辑任务时,两者的得分均低于1%,其中 GPT-5.5 得分仅为0.43%,而 Claude Opus 4.7 则为0.18%。
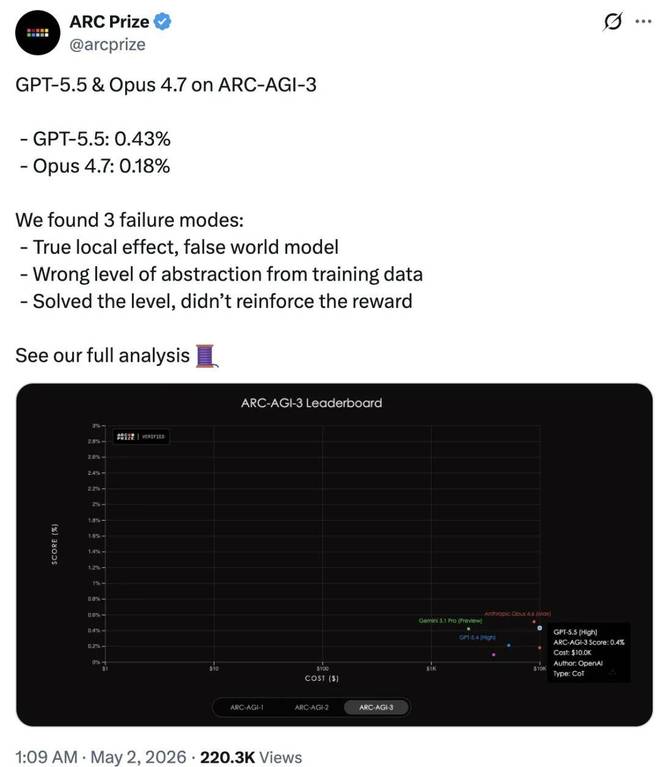
这意味着即便拥有庞大的参数量和几乎无限的计算资源,这些模型在面对「全新逻辑环境」时的表现还不如一个6岁的小孩。
这是怎么一回事?
ARC-AGI-3:测试智能的核心标准
为了更好地理解这一成绩,我们需要了解一下 ARC-AGI-3。这是由 Keras 的创始人 François Chollet 创建的最新一代基准测试系列,在今年三月首次发布。
当初,François Chollet 表示,只有当一个 AI 系统在初次接触所有环境时表现出不低于人类水平的表现,才能算作真正「攻克」了 ARC-AGI-3。
根据团队进行的大量人类测试显示:未经过任何训练的人类可以在首次接触这些环境中完全解决难题,而目前所有的前沿 AI 推理模型在这一测试中的表现都低于1%。
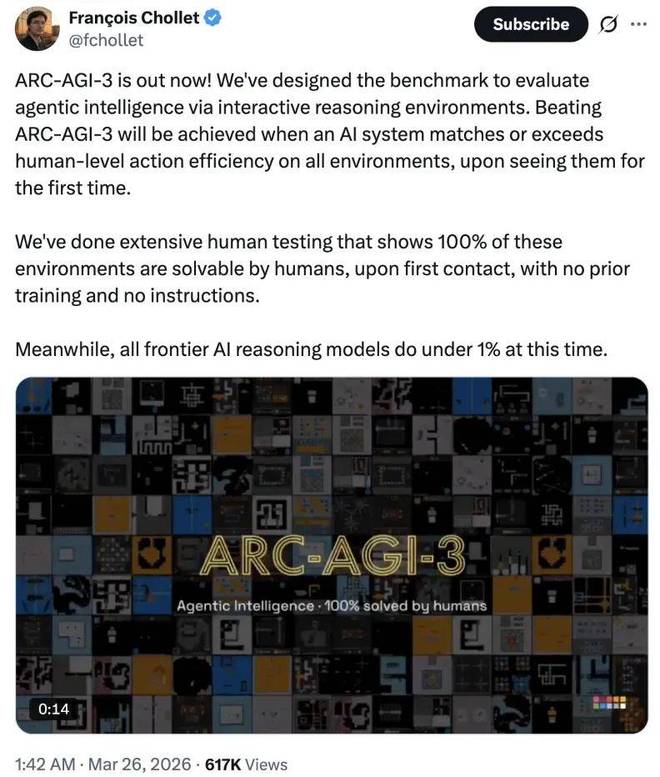
当时这两款模型还未发布,但如今它们的表现与当初预期并无二致。
具体而言,ARC-AGI-3 包含了135个全新环境组成的测试集。每一个环境都是由人类手工设计的,旨在评估模型处理「未知」的能力。
对于参与者来说,无论他们是人类还是 AI,在进入环境中时都不会获得任何玩法说明。要取得进展,必须做到以下几点:
- 探索未知界面 ;
- 从稀疏反馈中推断规则;
- 提出并验证假设 ;
- 从错误中恢复 ;
- 将经验迁移到下一关(持续学习)。
每个环境的构建都不包含模型通常依赖的文化知识,只保留「抽象推理能力」本身。
简单来说,ARC-AGI-3 是一个在新颖性、模糊性、规划和适应性上的最低共同测试集合。这些正是现实世界任务对智能体的核心要求。因此,它也被视为目前最接近「人类智能本质」的测试之一。
顶尖模型纷纷失利背后的三大原因
虽然 GPT-5.5 和 Claude Opus 4.7 的表现令人失望,但了解其背后的原因似乎更为重要。
ARC Prize 研究团队通过对160组完整运行轨迹的分析,总结出了导致模型「崩溃」的三大核心失败模式:
首先,真实的局部反馈与虚假的世界模型
模型可以理解哪一步动作产生了变化(局部反馈),但无法将这种因果关系转化为一套完整的全局规则。
例如,在一个需要旋转物体以匹配插槽的任务中,模型能够识别出「按下这个键会使物体旋转」这一局部规律。然而它却不能进一步推理出:「旋转会影响结果,因此我需要在行动前调整物体的方向来与目标对齐。」
这一失败并非由于它们看不见,而是因为无法将观察到的事物整合成一个完整的模型。
比如,在任务 「cd82」 中,Claude Opus 4.7 在第 4 步已经意识到执行「ACTION3」可以旋转容器。随后在第 6 步也注意到执行「ACTION5」可倾倒或蘸取油漆。然而,它始终无法将这些碎片化的认知转化为一个完整的逻辑策略。

Claude Opus 4.7 明白 ACTION3 可以使物体旋转,但未能理解整个游戏的规则。
或者在任务「cn04」中,Claude Opus 4.7 尽管发现了成功的“旋转后放置”的交互逻辑(这是正确的假设),但在随后却陷入了追求整体形状重叠的误区,并为了假象中的顶行进度而偏离了正确目标。

第二种失败模式是被训练数据绑架的抽象思维
模型对当前环境产生了误判,它们会将一个全新的「ARC-AGI-3」任务错误地认为是在玩另一种已知的游戏。
这源于模型对于训练数据的「错误抽象」。多次运行中,它试图通过将其映射到诸如俄罗斯方块、青蛙过河等已知游戏来解释新机制。
虽然从核心先验知识提取抽象概念理论上有助于解决问题,但这些字面类比反而会束缚模型的动作选择。
比如,在任务「cd82」中,GPT-5.5 的思维被锚定在了流沙、物理模拟或颜色填充的游戏机制上;而在任务「ls20」 中,它将本应是按键组合的操作误判为了打砖块游戏。

第三种失败模式是通关却未学会规则
模型可能侥幸通过了一个特定关卡,但无法利用成功的奖励信号来强化并执行正确的后续操作。这说明「通关并不等于理解」。
Claude Opus 4.7 的记录很好地证明了这一点。
在任务「ka59」中,Claude Opus 4.7 尽管世界模型不完整,仍能读出双角色、双目标的布局并完成较短的操作序列。但在 Level 1 中它构建了一套错误理论,并在此基础上不断尝试操作。
而在任务「ka59」中,GPT-5.5 也能够识别出正确的对象结构 —— 两个目标轮廓和一个可切换的第二角色——但始终没有真正执行这一理解。它始终停留在分散的可能性之中。

换句话说,Claude Opus 4.7 类似于“过度自信的直觉主义者”,而 GPT-5.5 则像“思维发散的理论家”。
归根结底,两者之间的差异在于「压缩」能力的不同:Claude Opus 4.7 将观察压缩成了一个“自信但错误”的理论,而 GPT-5.5 几乎无法完成压缩,始终停留在分散的可能性之中。

在这两种情况下,Level 1 的成功掩盖了模型对底层机制的缺失或扭曲,这种「局部胜利」反而为错误的 Level 2 策略提供了一个看似自信的支撑框架。
这也说明,早期关卡的推进并不能可靠反映模型是否真正理解了任务。如果没有明确检验模型「为什么能过关」,它就会把错误的认知带入下一关,并在此基础上不断放大偏差。
双双在 ARC-AGI-3 上的低分表现揭示了一个事实:通往 AGI 的道路仍然漫长且充满挑战。
你认为 AI 在这次测试中的成绩如何?欢迎在评论区交流讨论!
简单来说就是,Claude Opus 4.7 的问题是「压缩错了」,而 GPT-5.5 的问题则在于「压缩不了」。
具体来看,Opus 4.7 在短周期的机制发现方面表现更强。例如在任务「ar25」中,它几乎立刻识别出镜像结构,并顺利通过 Level 1;在任务「ka59」中,即便世界模型并不完整,它也能读出「双角色、双目标」的布局,并完成较短的 Level 1 操作序列。
但问题在于,它也更容易抓住一个错误的「恒定特征」,并坚定执行下去。
比如在任务「cn04」中,它构建了一套「进度 / 计时 / 转换」的错误理论,并在这一假设下不断尝试操作(第 60 步)。它确实形成了一套「可运行的解释」,只是这套解释是错的。
GPT-5.5 则是另一个极端。它的「假设生成」更广泛,这使得它更有可能说出正确的思路,但同时也更难将其转化为具体行动。
比如在任务「ar25」中,它识别出了镜像效应,但不断重新打开「可能的游戏类型空间」,在「俄罗斯方块」「青蛙过河」「乒乓球」「汉诺塔」之间反复横跳,始终无法坚定地执行镜像逻辑。而在任务「ka59」中,它也构建出了正确的对象结构 —— 两个目标轮廓和一个可切换的第二角色 —— 但始终没有真正执行这一理解。
换句话说,Claude Opus 4.7 有点像「过度自信的直觉主义者」,GPT-5.5 则像「思维发散的理论家」。
而归根结底,两者之间的这种差异在于「压缩」能力的区别:Claude Opus 4.7 将观察压缩成了一个「自信但错误」的理论,而 GPT-5.5 则几乎无法完成压缩,始终停留在分散的可能性之中。
不得不说,此次 Claude Opus 4.7 和 GPT-5.5 双双在 ARC-AGI-3,这一堪称目前最接近「人类智能本质」的测试上的低分表现,揭示了一个事实:AGI 之路「道阻且长」啊。
https://x.com/fchollet/status/2050328852107612559
https://arcprize.org/blog/arc-agi-3-gpt-5-5-opus-4-7-analysis
https://x.com/GregKamradt/status/2050262126120632554
https://x.com/GregKamradt/status/2050262126120632554