
复旦大学、上海创智学院和新加坡国立大学共同提出了HERMES,这是一种无需训练的流式视频理解框架。该框架将KV Cache重构为层次化记忆系统,能够在用户提问时直接利用缓存进行回答而不需要额外检索或计算。
实验结果表明,在多个流式及离线视频基准测试中,与均匀采样相比,HERMES在减少68%的视频token情况下仍能达到相似甚至更好的理解性能;特别是在流式数据集上,它带来了11.4%的最大增益,并实现了首个令牌生成时间(TTFT)高达十倍的加速。
在现实生活中,人类观看视频时并不会将所有画面一次性存储下来再进行分析。例如,在看直播、监控或操作机器人等场景中,我们通常会把最近发生的事件保持在注意力前沿,同时压缩早期但重要的信息到长期记忆里。当被问及问题时,我们可以立即作出回应而无需重新回顾整个过程。
尽管多模态大型语言模型在处理离线视频方面已取得显著进展,但在面对流式视频场景时仍面临三大挑战:保持稳定的理解性能、实现即时响应以及控制GPU显存使用量。现有的方法要么通过外部存储保存历史内容并在提问时检索以重建上下文,要么尝试直接压缩缓存但缺乏有效的管理和解释能力。
为了解决这些问题,研究团队提出HERMES(KV Cache as HiERarchical Memory for Efficient Streaming Video Understanding),将KV Cache视为层次化记忆系统而非被动的中间产物。这样不仅能够实现缓存的压缩,还能对其进行精细化管理。目前,这项工作已被ACL 2026会议收录。

- 论文标题:HERMES:KV Cache as HiERarchical Memory for Efficient Streaming Video Understanding
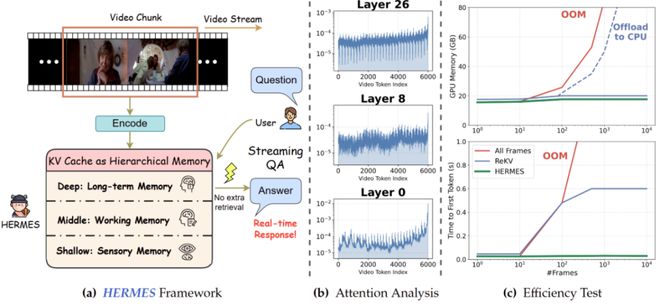
- 图1展示了HERMES的概念图,左侧描绘了其将KV Cache视为层次化记忆系统的设计框架;右侧则显示了不同层的注意力偏好与效率测试结果。
- HERMES的核心创新在于它不仅压缩缓存,还引入了一套管理机制。通过分析注意力模式,研究团队发现不同解码层在处理流式视频时具有不同的信息偏好和分工职责。
- 浅层类似于感官记忆,对最近的帧有明显的近期偏好;中层如同工作记忆,在平衡近期与早期语义信息方面发挥作用;深层则像长期记忆,会周期性地锁定一些关键锚点以保留重要的语义信息。
通过分层管理、跨层平滑和位置重索引三大组件的结合使用,HERMES能够在不依赖额外训练的情况下直接复用一份紧凑而有效的缓存来支持实时视频问答任务。
实验结果显示,在多个流式基准测试中,HERMES不仅实现了更快的速度,还在准确性方面表现出色。例如,在StreamingBench和OVO-Bench等任务上,它显著超过了基础模型的表现,并在不同底座模型上的评估均显示出一致性提升。
此外,在开放式问答任务中,如RVS-Ego和RVS-Movie,HERMES也显示出了更精细的时间与空间理解能力,相较于基本模型提升了最高达11.4%的性能指标。这表明其优势不仅体现在选择题上,还适用于开放式的实际应用场景。
在效率方面,HERMES在用户提问时无需额外检索或计算,直接利用现有缓存进行回答,这尤其适合流式交互场景。实验证明了它在不同输入帧数下保持稳定显存占用和极低的TTFT的能力,表明其具有显著的速度优势。
更重要的是,HERMES能够在固定紧凑的内存预算条件下持续工作,避免因视频数据量增加而导致的内存压力上升问题,更适合长期在线部署的实际需求。
除了效率与准确性之外,HERMES还证明了流式视频理解不一定要依赖于保存尽可能多的帧。论文指出,在减少68%的视频token的情况下,它仍然能够在多个基准测试中保持竞争力和泛化能力,这为未来的研究提供了新的视角。
HERMES不仅在技术层面展示了强大的性能与效率优势,还提供了一种更为自然且接近真实部署需求的设计思路。它的价值在于为流式视频理解提供了一套可迁移的模式,并具有广泛的适用性和解释性,适用于视频助手、机器人、智能安防等多个领域。
未来展望中,HERMES展示了如何让大规模视频模型以更像记忆系统的方式持续工作,这预示着下一代流式多模态智能体的发展方向。随着实时视频应用的不断增加,这种既能保证准确性又能实现低延迟和低内存开销的方法可能会成为视频大模型迈向“能持续在线理解视频”的关键一步。
HERMES项目由复旦大学一年级博士生张浩威和南京大学本科生杨枢栋共同完成;合作作者包括新加坡国立大学See-Kiong Ng教授;通讯作者为复旦大学计算与智能创新学院青年研究员傅金兰以及邱锡鹏教授。
HERMES 最有启发性的地方,在于它不是从工程经验出发硬做压缩,而是先通过注意力机制分析,去观察不同解码层到底更偏好什么样的视频信息。研究团队发现,在流式输入下,不同层实际上天然呈现出不同的 “记忆分工”。
一个关键洞察:不同层,关注的是不同粒度的信息
研究发现,浅层、中层和深层对视频 token 的偏好并不相同:
浅层像感官记忆。它们对最新到来的帧有明显的近期偏好 (recency bias),更关心 “刚刚发生了什么”。
中层像工作记忆。它们会在近期信息和更早的语义信息之间做平衡,承担承上启下的过渡作用。
深层像长期记忆。它们不再单纯偏向最近帧,而是会周期性地锁定一些帧级 “锚点” token,用来保留更长时间跨度上的关键语义。
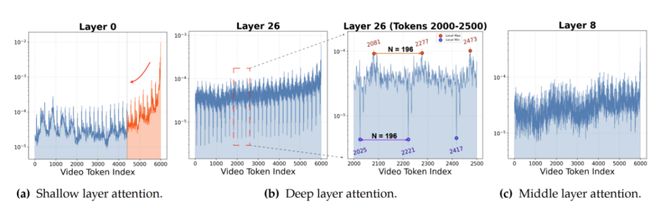
图 2:不同层对流式视频 token 的注意力偏好。浅层更关注最近 token,深层更倾向于捕捉具有节奏性的帧级锚点,中层则承担过渡作用。
这意味着,KV Cache 并不是一个 “各层同质” 的存储池,而天然更像一个由感官记忆、工作记忆和长期记忆组成的层次化系统。HERMES 正是基于这一点,重新设计了流式视频缓存的保留策略。
方法三件套:分层管理、跨层平滑、位置重索引
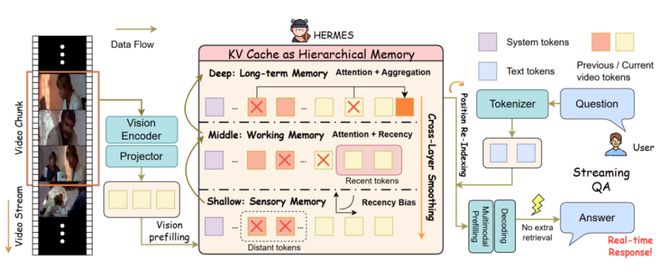
图 3:HERMES 方法总览图。包括 “分层 KV Cache 管理”、“跨层记忆平滑” 和 “位置重索引” 三大关键组件。
围绕 “KV Cache 是层次化记忆” 这一核心认识,HERMES 构建了三大关键组件:
1. 分层 KV Cache 管理(Hierarchical KV Cache Management)
HERMES 不再对所有层采用统一的淘汰策略,而是按层分配不同保留逻辑。浅层主要按时间新近性保留 token;深层则更多依据对用户查询的注意力重要性来保留帧级锚点;中层通过对 “新近性” 和 “注意力分数” 做插值,在二者之间取得平衡。
2. 跨层记忆平滑(Cross-Layer Memory Smoothing)
如果每一层都独立淘汰 token,就容易出现不同层在同一缓存位置上 “记的不是同一个东西” 的问题。HERMES 通过从深层向浅层传播重要性信号,对跨层记忆进行平滑,让多层缓存之间保持更一致的视觉记忆结构。
3. 位置重索引(Position Re-Indexing)
随着流式输入不断累积,token 的位置索引会越来越大,最终逼近模型支持的上限,影响生成质量。HERMES 通过位置重索引,把保留下来的 token 重新映射到连续位置区间中;在流式任务上使用更省算力的惰性重索引 (lazy re-indexing),在离线长视频评测上则使用更稳定的即时重索引 (eager re-indexing)。
这三步结合起来,让 HERMES 能在不依赖额外训练、不需要查询时外部检索的前提下,直接复用一份紧凑而有效的缓存,支撑实时视频问答。
实验结果:HERMES 不只是更快,
还在多个基准上更稳更准
主结果:在流式视频基准上显著领先 training-free 基线
研究团队在StreamingBench、OVO-Bench、RVS-Ego、RVS-Movie等多个流式视频任务上进行了系统评估。结果显示,HERMES 不仅超过了对应的基础模型,也普遍优于现有 training-free 的 offline-to-online 方法。
以Qwen2.5-VL-7B为例,在仅使用4K video tokens的情况下,HERMES 在 StreamingBench 上达到79.44%,相较基座模型的73.31%提升6.13个点;在综合平均指标上达到59.21%,相比基座模型的52.28%提升6.93个点。基于Qwen2.5-VL-32B的 HERMES 版本则进一步将综合平均表现提升到64.82%。
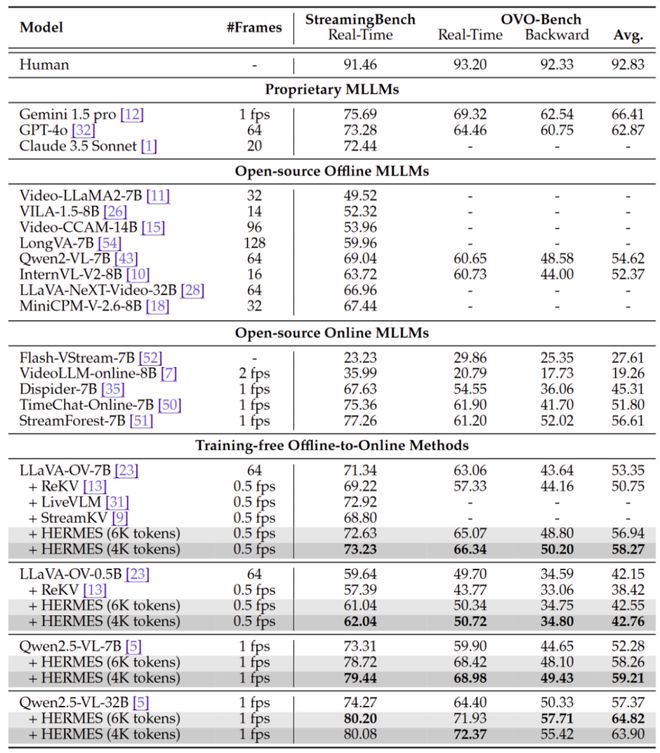
图 4:StreamingBench 与 OVO-Bench 上的主结果。HERMES 在众多 offline-to-online 方案中表现突出,并在不同底座模型上均能稳定提升。
在开放式流式问答任务上,HERMES 同样展现出更细粒度的时序与空间理解能力,在RVS-Ego和RVS-Movie上相较基础模型最高可提升11.4%,说明其优势不仅体现在多选题上,也体现在更接近真实使用场景的开放问答中。
效率优势:查询到来时 “实时开口”
如果说准确率证明了 HERMES “记得住”,那么效率实验证明了它 “答得快”。由于 HERMES 在用户提问到来时不需要额外检索或辅助计算,它可以直接在现有缓存上完成回答,这一点对流式交互尤为关键。
在基于LLaVA-OV-7B、4K-token memory budget的测试中,HERMES 在不同输入帧数下都保持了稳定的显存占用与极低的 TTFT。论文显示,在16、64、256帧输入下,其 TTFT 分别约为27 ms、29 ms、28 ms;在256 帧设置下,相比此前的 SOTA 方法StreamingTOM,HERMES 实现了约10×的 TTFT 加速。
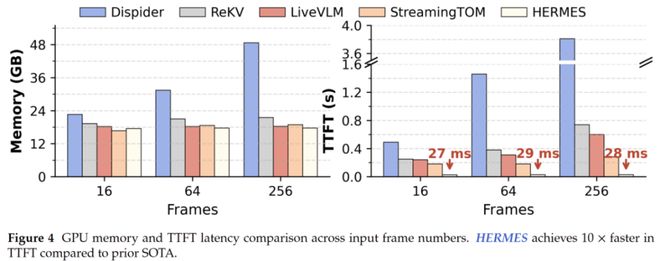
图 5:效率对比结果。随着输入帧数增加,HERMES 仍能保持稳定的 GPU 显存占用和极低的 Time To First Token (TTFT)。
更重要的是,这种速度优势不是靠牺牲缓存上限换来的。HERMES 在固定紧凑显存预算下持续工作,避免了随视频流增长而不断抬升的显存压力,更适合真实部署中的长期在线场景。
更少 token,不代表更差理解
HERMES 的另一个重要意义在于,它证明了流式视频理解并不一定依赖 “保存尽可能多的帧”。论文指出,相比均匀采样方案,HERMES 最多可减少68%的视频 token,但依然能在多个流式和离线基准上保持竞争力。
在离线视频任务上,HERMES 并没有因为面向流式场景设计而牺牲泛化性。以LLaVA-OV-7B为基座时,HERMES 在Egoschema和VideoMME上分别达到 60.29% 和 49.22%,高于基座模型;在MVBench上则取得与基座相当的结果。这说明它不仅适用于持续在线的视频流,也具备向更广泛长视频理解任务迁移的能力。
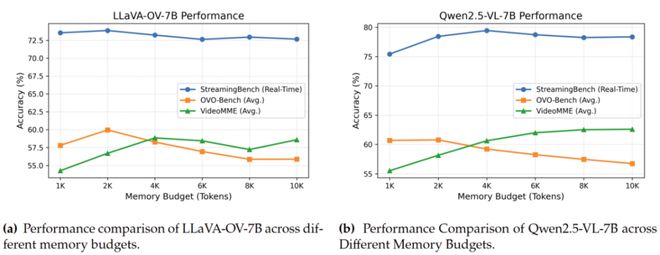
图 6:不同 memory budget 下的性能变化。实验表明,HERMES 在约 4K memory budget 左右已经能在流式与离线任务间取得较好平衡。
从消融实验可以看到,HERMES 的提升并非来自单一技巧,而是来自一整套协同设计:分层缓存管理决定 “留什么”,跨层记忆平滑解决 “不同层是否记一致”,位置重索引保证 “长流式输入下还能稳定生成”。这些模块共同构成了它的性能与效率优势。
为什么 HERMES 值得关注?
HERMES 的价值,不只是又一个在榜单上更高分的方法,更在于它为流式视频理解提供了一种更自然的系统设计思路。
它更接近真实部署需求。对于视频助手、机器人、智能安防、车载系统等场景来说,用户不会等待模型重新检索长上下文再开始作答。HERMES 把 “实时响应” 放在架构设计的中心位置,这一点非常关键。
它给出了更有解释性的缓存视角。很多缓存压缩方法是经验性的,而 HERMES 先做机制分析,再据此设计记忆管理规则,使 “为什么保留这些 token” 这件事变得更清楚。
它是training-free、plug-and-play的。 论文在 LLaVA-OV 与 Qwen2.5-VL 等不同基础模型上验证了 HERMES 的通用性,说明它不是与某个单独模型强绑定的工程 patch,而更像一种可迁移的流式理解范式。
未来展望:让视频大模型真正走向持续在线
HERMES 所回答的,不只是 “如何压缩 KV Cache”,而是 “如何让视频大模型以更像记忆系统的方式持续工作”。从这个角度看,它为下一代流式多模态智能体提供了一个很重要的方向:模型不必在每次回答前重新回看全部历史,而是应该学会像人一样,保留最新感知、提炼关键锚点、压缩长期经验,并在需要时迅速调用。
我们可以预期,这种思路会在更多实时视频场景中释放价值,例如长时监控理解、第一视角视频助手、机器人持续感知、在线教育分析以及人机实时协作等。随着流式视频应用不断增多,像 HERMES 这样兼顾准确性、低延迟与低显存开销的方法,很可能成为视频大模型从 “能看视频” 迈向 “能持续在线理解视频” 的关键一步。
作者简介:
第一作者为复旦大学一年级博士生张浩威和南京大学本科生杨枢栋;合作者包括新加坡国立大学 See-Kiong Ng 教授;通讯作者为复旦大学计算与智能创新学院青年研究员傅金兰与邱锡鹏教授。