
头图由AI生成
近日,一家由北京大学背景的团队创立的人工智能编程初创公司——硅心科技,发布了其最新研发的轻量级模型aiX-apply-4B。这款模型仅需4B的参数量和256K的上下文支持,能够在消费级显卡上进行部署。
该模型专为企业级代码修改任务设计,能够自动识别修改意图,精确定位目标代码区域,并保持原有代码格式和上下文结构的完整,将修改后的代码无缝融入原始文件。
在基准测试中,aiX-apply模型在Python、Java、JavaScript、C++等主流编程语言和JSON、Markdown等多种文件格式下的平均准确率达到了93.8%,显著超过了Qwen3-4B基座模型的62.6%准确度,并且优于DeepSeek-V3.2千亿级大模型的性能。
实际部署测试显示,aiX-apply模型能在单个RTX 4090显卡上运行,推理速度可达每秒2000 tokens,而DeepSeek-V3.2则需要在八张H200显卡的环境下才能达到相同性能。这意味着aiX-apply模型的计算成本仅为DeepSeek-V3.2的5%,并且推理速度提升了15倍。
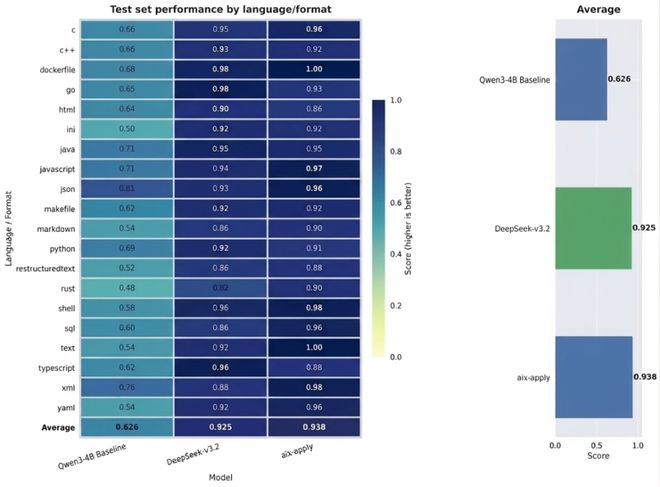
▲基准测试对比
技术层面,aiXcoder团队采用了自适应投机采样技术,优化了代码合并任务中的重复片段识别,有效缩短了端到端的延迟时间。
在准确性和稳定性方面,aiX-apply模型在处理超长代码文件和跨语言环境下的代码理解与生成等复杂任务时,表现出色,与DeepSeek V3.2相当。
为了确保模型在各种泛化性场景中的性能,aiXcoder团队设计了一套全面的测试维度,包括随机替换代码边界占位符、处理超长序列代码、在不完整的代码文件中进行局部编辑,以及涵盖训练数据中少见的编程语言等。
测试结果显示,通过专门的强化学习训练,aiX-apply模型在多种泛化性场景中的准确性和稳定性均与DeepSeek V3.2持平。
该模型的训练数据来源于企业级的真实代码提交记录,aiXcoder团队通过一致性审计机制剔除了模糊上下文和无法推导修改逻辑的信息,确保了训练数据的质量。
这种高质量的数据训练使得aiX-apply模型能够在训练阶段形成从修改意图到代码应用位置的深度映射。
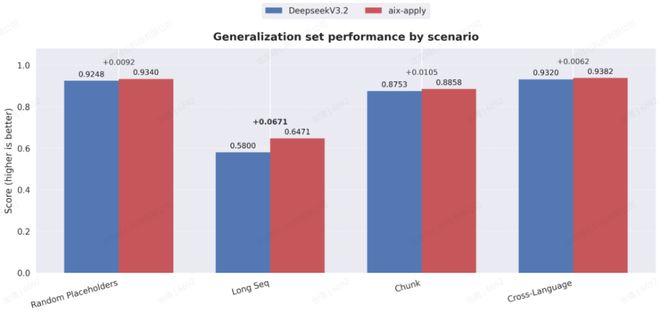
在训练过程中,aiX-apply模型基于高性能强化学习框架生成代码修改内容,并结合规则化奖励机制进行评估。模型会实时判断修改的正确性和边界性,并将结果反馈给模型。
通过这种端到端闭环训练方式,aiX-apply模型能够在“生成-反馈-修正”的在线强化学习中持续优化,确保其操作的精准性和可靠性。
为了确保代码合并过程的高度可控性和结果的可预测性,aiX-apply模型设定了双重核心工程约束:
第一是非副作用约束,确保模型仅修改指定区域,不允许对其他区域进行任何修改;
第二是安全失败策略,当代码上下文锚点不唯一或无法准确识别时,模型会直接输出空结果,避免对代码库造成污染。
总结来说,aiX-apply模型以其低成本、高性能和易部署的特点,为企业级的私有化部署和工程化落地提供了有力支持。
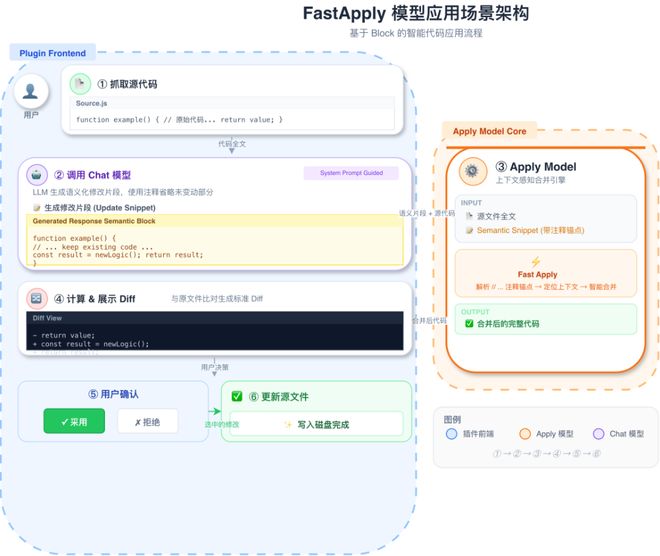
▲模型架构
在成本效益方面,该模型能够在单张消费级显卡上高效运行,其轻量级架构显著降低了企业使用私有化AI的门槛,有助于快速将智能化能力融入研发流程中。
在研发效率方面,aiX-apply模型支持256K的上下文,每秒吞吐量达到2000 tokens,使得大规模代码库中的实时、精准自动化代码修复和集成成为可能。
在工程可控性方面,aiX-apply模型有效减少了AI幻觉引发的错误修改,从而降低了人工审核成本和线上故障的概率,提高了企业研发流程的稳定性和规范性。
结语:aiX-apply轻量化部署,降低企业落地门槛
aiX-apply模型主打低成本、高性能与易部署,在企业私有化部署与工程化落地中较有优势。
成本方面,该模型单张消费级显卡即可高效运行。其轻量化架构降低了企业使用私有化AI的门槛,便于快速将智能化能力融入研发流程。
研发效率上,aiX-apply支持256K上下文,吞吐量达每秒2000 tokens,可在大规模代码库中完成实时、精准的自动化代码修复与集成。
工程可控性层面,该模型有效减少了AI幻觉引发的错误修改,降低人工审核成本与线上故障概率,能够提升企业研发流程的稳定性与规范性。