
马斯克宣布Grok V9-Medium 1.5T完成训练:两到三周发布
布IT之家 5 月 25 日消息,马斯克今日宣布,Grok 基础模型 V9-Medium(1.5T、1.5 万亿参数量)已完成训练。马斯克透露,该模型的评估结果相当不错。在补充训练中,加入了大量 Cursor 数据,未来还会继续添加更多数据。马斯克表示,微调工作正在进行中,强化学习将于几天后开始,距离公开发布还有 2 到 3 周。相比目前支撑所有 Grok 生产端流量的 0.5T V8-Small
科技1 阅读
共找到 27 篇相关文章
布IT之家 5 月 25 日消息,马斯克今日宣布,Grok 基础模型 V9-Medium(1.5T、1.5 万亿参数量)已完成训练。马斯克透露,该模型的评估结果相当不错。在补充训练中,加入了大量 Cursor 数据,未来还会继续添加更多数据。马斯克表示,微调工作正在进行中,强化学习将于几天后开始,距离公开发布还有 2 到 3 周。相比目前支撑所有 Grok 生产端流量的 0.5T V8-Small

5月21日,腾讯混元宣布开源全新翻译模型Hy-MT2并上线翻译小程序「腾讯Hy翻译」。Hy-MT2 是支持 33 种语言互译的多语言模型,其中7B 和 30B-A3B模型在各类翻译任务上达到了开源模型最佳效果,超越了几十倍参数量的模型,轻量级的 1.8B 模型也超越了微软等主流商业 API,且得益于 AngelSlim 1.25-bit 极端量化,仅需 440MB 存储空间,可以轻松部署在主流手机

凤凰网科技讯 5月20日,智象未来在北京举办开放日,发布基于原生全模态架构Unified Transformer的图像大模型HiDream-O1-Image-Pro,参数量超2000亿。该模型将图像像素、文本标记与任务条件统一纳入连续共享标记空间,在通用文生图、高保真文字渲染、图像编辑等任务上取得SOTA表现。此前,采用同架构的8B开源版本HiDream-O1-Image曾在Artificial

在大模型时代,许多专业人士或许都遇到过类似的问题:当尝试将 DeepSeek-R1 和 OpenAI-o1 这样的卓越推理能力移植到小规模语言模型(SLMs)上时,实际效果往往不尽如人意。尽管现有的强化学习方法 GRPO 对于 7B+ 参数量的大模型来说非常有效,但一旦应用于更小型的模型中,比如 1.7B 或者参数量更少的情况下,性能提升就显得十分有限。针对小规模语言模型在强化学习中的推理难题,香

DeepSeek近日在GitHub上公开了一款多模态推理模型及其技术报告《以视觉原语思考》。这个模型基于DeepSeek V4-Flash架构(总计参数量为284B,实际运行时激活的参数数量为13B)开发而成,并提出了一种新的多模态推理方式。研究指出当前市面上的许多大型多模态模型存在一个未被充分重视的问题:“指代鸿沟”(Reference Gap),即尽管这些模型能够识别图像中的内容,但在用自然语

机器之心编辑部最近,arXiv 上发布了一篇论文,作者是李博杰,他在文中提出了一种名为「不可压缩知识探针」的评估框架。该框架旨在仅通过黑盒 API 调用来逆向推算任意 LLM 的参数量。论文标题为《Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity》研究人员长

近日,DeepSeek发布了多模态技术报告《视觉原语思考》(Thinking with Visaul Primitives),详细披露了其新推出的识图模式背后的创新机制。该识图模式采用了名为DeepSeek-V4-Flash的基座模型,参数量达到284B,并拥有13B激活多模态推理模型。这一模型尚未正式命名,但DeepSeek已经确认未来会将其整合进基础模型中进行发布。据介绍,传统的思维链主要在语

近日,阶跃星辰发布了一款新的图像编辑生成模型——Step Image Edit 2。据悉,这款模型的参数量仅为3.5B,在KRIS-Bench轻量化评测中取得了综合第一的成绩,并支持多种功能如文生图、中英文渲染、局部编辑等。目前该服务已开放API接口供用户使用,定价为每张图片0.02元,公测期间(4月28日至5月5日)免费体验。根据官方发布的视频资料,在生成文生图的速度方面,Step Image

从 DeepSeek-R1 到 Kimi K2.5,利用强化学习(RL)来优化大型模型的推理性能已成为关键方法。然而,在 RL 后训练过程中存在一个重要问题:这种训练方式是否遵循特定规律?能否通过给定参数量、计算资源和数据规模,准确预测出 RL 训练所能达到的效果?中国科学技术大学与上海人工智能实验室等机构的研究团队对此进行了系统性的研究。他们使用 Qwen2.5 系列密集模型(从0.5B到72B

新智元报道昨晚,GPT-5.5果然如约而至,全球AI开发者为之振奋。紧接着,DeepSeek-V4在同一天发布,令人大为震惊。2026年4月24日对科技界而言意义非凡,这一天注定会被载入史册。OpenAI在凌晨发布了备受期待的GPT-5.5版本,旨在通过更大的参数量重新定义智能技术的新边界。正当人们还在热议这一事件时,一款以颠覆行业闻名的国产产品——DeepSeek,带着其最新的V4版本强势登场。

星期五中午,本该是盘算周末去哪嗨的黄金时段。但没想到 DeepSeek 突然正式发布并开源了 V4 系列模型预览版。一上来就是王炸级别,而且双双标配百万 token 上下文:参数量达 1.6T 的 DeepSeek-V4-Pro(49B 激活参数)284B 参数的 DeepSeek-V4-Flash(13B 激活参数)即日起可在官网 chat.deepseek.com 或官方 App 体验,API

新智元报道DeepSeek V4 引人注目,其参数量达到惊人的1.6万亿,并且在Codeforces竞赛中排名人类选手第二十三位,KV缓存仅前代的十分之一。在同一周内,Kimi K2.6也宣布开源,支持数百万token的上下文和300个子Agent协同工作,模型参数量更是达到了2.6万亿。两家公司在中国AI领域中的地位显赫,它们的技术进步与发布时间高度契合,似乎有意为之。回顾过去一年半的时间线,D

智东西编辑团队发布了一篇关于腾讯新一代混合专家架构的大规模语言模型Hy3 preview的文章。该文章详细介绍了姚顺雨领导的混元团队首次对外展示的新一代大模型。Hy3 preview是迄今最智能的模型,采用了快慢思考融合的设计理念,并具备支持最长256K上下文的能力。它拥有总计295B的参数量和激活参数数量为21B。从测评结果来看,Hy3 preview在复杂推理、指令遵循、代码生成与智能体能力等

混元大模型重建的第一步是Hy3 preview。作者|连冉姚顺雨在加入腾讯后,推出了首个重要的语言模型项目。4月23日,腾讯正式发布了混元 Hy3 preview 语言模型,并将其开源。这款模型采用快慢思考融合的MoE架构设计,总参数量达295B,激活参数为21B,支持的最大上下文长度达到256K,官方宣称其整体性能处于同尺寸模型中的领先水平。按照研发进度来看,Hy3 preview 从今年年初启
智东西编译 杨京丽编辑 陈骏达近日,阿里通义千问团队发布了Qwen3.6-27B的开源版本——这是一个具有270亿参数的大规模稠密多模态模型,并支持思考与非思考模式。相较于先前推出的Qwen3.5-397B-A17B,新的Qwen3.6-27B虽然在参数量上仅为前者的十分之一,却在编程性能等多个关键指标上实现了超越。其不仅显著提升了编程能力,在文本和多模态推理方面也表现出色。与同级别的Ge
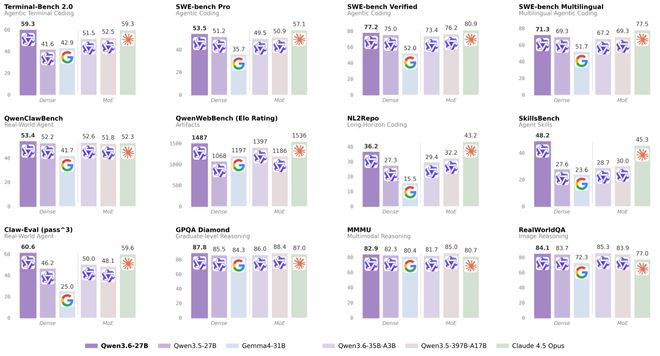
昨日夜间,千问3.6系列的最新版本Qwen3.6-27B正式对外开放源代码。据官方披露,这款模型凭借其庞大的参数规模,在核心编程能力评估中表现出色,与拥有千亿级参数量级别的模型不相上下。在多项权威基准测试如SWE-bench、Terminal-Bench 2.0、SkillsBench、QwenWebBench及NL2Repo等真实世界智能体编程技能评价体系中,该模型均取得了卓越的成绩。目前,开源

近日,在科技领域内备受关注的蚂蚁百灵,正式对外发布了 Ling-2.6-flash 大模型。这款拥有 104B 参数总量和 7.4B 激活参数量的新产品,以“Token 效率”为核心特色,能够提供更快、更经济且更加适合大规模实际应用的智能化服务。自匿名测试版“Elephant Alpha”在 OpenRouter 上线以来,仅一周时间便引起了业界的高度关注。上线后,“Elephant Alpha”

近日,一款名为Elephant(大象)的匿名AI模型在OpenRouter平台低调登场。上线短短两天内,这款模型便跃升至OpenRouter热门榜首位,并且调用量已超过1850亿个token。在OpenRouter的日排名中,Elephant位列全球第八。据OpenRouter的介绍,Elephant是一款拥有100B参数量的纯文本模型。它的亮点在于高效的token效率和强大的上下文支持能力,可处

智东西作者 李水青编辑 心缘昨晚,阿里通义千问团队宣布开源了混合专家(MoE)模型Qwen3.6-35B-A3B,在此前发布的Qwen3.6-Plus之后。这一新模型拥有350亿的总参数量,激活参数仅为30亿。它以其轻量化高效和智能体编程能力著称,并在多模态感知与推理方面表现出色,超越了谷歌近期推出的Gemma 4系列和其他阿里内部模型。据官方信息显示,在关键编程基准测试中,Qwen3.6-35B

在本周四晚间,谷歌发布了其最新的模型系列 Gemma 4,这一系列被认为是当前开源领域中最强大的。新的 Gemma 系列在 Arena AI 排行榜上获得第三名的位置,并且超过了参数量是它五倍多的大规模模型。此外,Gemma 4 使用了 Apache 2.0 开源许可证,这意味着它可以完全用于商业用途。Google DeepMind 最近开发的 Gemma 4 是一个多模态模型系列,专门处理文本和