 近日,DeepSeek发布了多模态技术报告《视觉原语思考》(Thinking with Visaul Primitives),详细披露了其新推出的识图模式背后的创新机制。
近日,DeepSeek发布了多模态技术报告《视觉原语思考》(Thinking with Visaul Primitives),详细披露了其新推出的识图模式背后的创新机制。
该识图模式采用了名为DeepSeek-V4-Flash的基座模型,参数量达到284B,并拥有13B激活多模态推理模型。这一模型尚未正式命名,但DeepSeek已经确认未来会将其整合进基础模型中进行发布。

据介绍,传统的思维链主要在语言领域内发挥作用,而视觉推理则需要更多的信息支持。为了突破这个限制,DeepSeek的新一代多模态推理模型将纯粹的语言逻辑升级为一种结合了空间坐标的双轨思维方式。
在处理图像时,该模型能够像人类一样直接圈定特定的区域或物体,并对其进行精准定位和后续分析,提高了视觉推理的精确度。
据DeepSeek多模态团队负责人陈小康介绍,他们通过动图展示了这一机制的工作原理。在推理过程中,模型可以使用框来标记感兴趣的区域,在接下来的步骤中持续引用这些视觉锚点进行进一步判断。
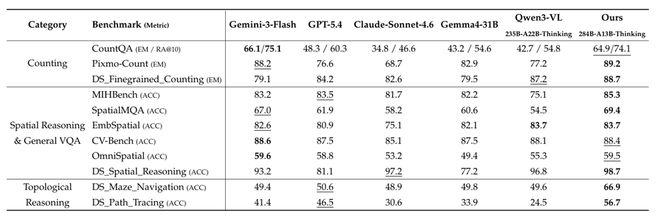
在一系列高难度视觉问答任务测试中,这款新模型的表现优于包括GPT-5.4、Claude-Sonnet-4.6等在内的多款现有模型。

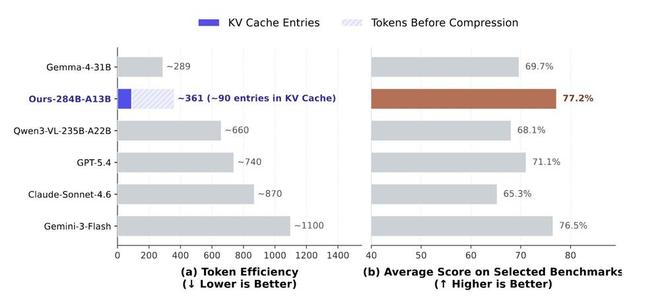
此外,该模型在处理复杂空间推理时表现出较高的token效率。与传统方法相比,DeepSeek采用了一种视觉压缩策略,将图像从原始像素开始进行特征提取,并通过稀疏注意力机制的三级处理最终仅保留90个视觉条目,实现了超七千倍的数据压缩。
这样一来,在模型需要执行复杂的空间推理任务时,无需再在海量数据中反复检索信息,简化了思考过程中的每一步骤。
该论文进一步指出,当前的多模态大模型存在一定的缺陷。尽管业界已经尽力提升视觉模型的识别能力,但在进行复杂视觉推理任务时依然会遇到瓶颈。
DeepSeek团队认为,自然语言在描述连续视觉空间方面存在着一种“指代鸿沟”。这种情况下,即使图像解析再精确也无法完全避免逻辑混乱的问题。
项目地址:
为此,DeepSeek多模态模型通过引入视觉原语如点坐标和边界框来增强其推理能力。具体来说,该团队设计了一种架构,使得视觉特征提取和语言指令处理能够顺利地融合在一起,并输出包含自然语言与视觉信息的联合响应。
技术报告:
为了训练这个复杂的系统,DeepSeek多模态团队构建了一个包括预训练、冷启动数据生成以及强化学习在内的完整流程。他们从网络上收集了大量高质量的数据样本,通过严格的筛选机制保证了模型能够准确识别图像中的关键元素。
在迷宫导航任务中,每个步骤都需要输出精确的坐标信息;一旦发生错误(例如撞墙),整个后续过程将被重置,迫使模型学习如何有效回溯并纠正自己的路径。
为了进一步提高多模态系统的性能,DeepSeek团队还引入了一种稠密奖励机制。这种机制详细分解了每个任务的不同方面,并为每一个成功完成的任务单元提供正向激励。
最后,通过一系列的技术创新和优化手段,DeepSeek不仅提升了模型的视觉理解能力,同时也大幅减少了处理图像所需的计算资源量。
总结来说,这项工作展示了多模态智能迈向更高水平发展的路径。尽管当前技术在某些方面还存在局限性,但其提出的框架为未来的探索提供了新的视角和方向。
于是,模型的思维链条看似环环相扣,实则每一步都存在偏离的风险,一旦涉及到密集计数、多步空间推理或者拓扑导航这种需要逐步推理的任务,逻辑就会因为指代不清而逐渐崩塌。
基于这个判断,DeepSeek多模态团队尝试让模型在思考时“边想边指”,也就是让模型用点坐标和边界框来“指”,把这些人类的视觉原语,变成模型思维链条上的最小认知单元。
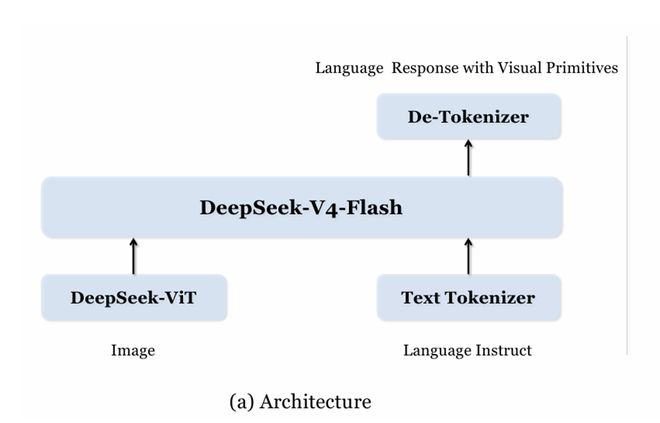
架构层面,这一多模态模型通过DeepSeek-ViT负责将图像转换为视觉特征,下图右下方的文本分词器负责处理用户的语言指令,两者输入至基座模型DeepSeek-V4-Flash进行推理融合,最后由去分词器输出包含自然语言与视觉原语(如坐标框、区域标记)的联合响应。这种设计使模型兼顾文本理解能力和原生视觉定位能力。
二、筛选超4000万个高质量样本,对四类任务针对性优化
要把点和框变成模型思维的一部分,首先要解决的问题,就是如何让模型真正“学会指”。模型需要把“指”这个动作内化成一种思维习惯。
为此,DeepSeek多模态团队构建了一条贯穿预训练、冷启动和强化学习的训练流水线。
在预训练阶段,他们从互联网上爬取了97984个与目标检测相关的数据源,设计了自动化的语义和几何质量审查机制,过滤掉乱码标签、不可泛化的私人实体、严重截断的框以及覆盖全图90%面积的“巨型框”等低质量标注,最终筛选出31701个高质量数据源,总计超过4000万个的精准样本,先让模型掌握基本定位能力。
接下来是冷启动数据构建。DeepSeek多模态团队针对计数、空间推理、迷宫导航和路径追踪这四类最能体现视觉原语价值的任务,合成了一套带有精确思考轨迹监督的数据。
以计数任务为例,模型被明确教导,在思考时要先批量框选所有候选对象,然后再对这些锚定好的框进行逐一校验和累加。

▲计数任务的一条冷启动数据
在迷宫任务中,模型的每一步探索都必须输出一个点坐标来标记当前所在,一旦失误撞墙,整个后续探索在因果上就自动失效,模型必须学会回溯。
这种把视觉原语操作直接整合进思维链的做法,让模型在冷启动阶段就建立起“指向-推理”的强耦合。
三、采用稠密奖励机制,视觉编码压缩比超7000倍
有了冷启动模型之后,DeepSeek多模态团队通过一套“训练专家再融合”的后训练策略,将模型的能力进一步精细化。其中的创新点在于强化学习阶段的奖励模型。
以迷宫任务为例,奖励分解为探索进度、撞墙惩罚、路径有效性和探索完整性等多个维度。模型每正确探索一个单元格、没有非法穿越墙壁,都会获得正向信号,而一旦发生撞墙,即便最终的答案为“可解”,也会被严格扣分。
这种稠密的奖励机制,让模型必须认真对待每一个视觉原语操作,无法靠猜答案实现奖励破解。
为了同时掌握框定位和点指向这两种视觉原语,该团队还分别训练了两个专家模型,最后通过在线策略蒸馏将它们融合成一个统一模型,让学生模型在自己生成的思维轨迹上,学习两位专家老师的输出分布。这种设计有效避免了两种异构原语在训练中的相互干扰。
值得一提的是,这项工作的技术路线建立在一个高效的视觉编码架构之上。
首先,Vision Transformer以14×14的块大小将图像切分成视觉token;然后,在ViT输出端进行3×3的空间压缩,将每9个相邻token沿通道维度合并为1个;最后,利用模型底座DeepSeek-V4-Flash自带的压缩稀疏注意力机制,将KV缓存中的视觉条目再压缩4倍。
以一张756×756分辨率的图像为例,它原本会产生2916个patch token,经过三级压缩后最终仅保留81个视觉KV条目,整体压缩比高达7056倍。
这种token效率意味着,模型在展开复杂的空间推理时拥有了一份“提炼好的索引”,可以拿着索引直接进行思考,从工程上就减弱了无关像素对推理链路的干扰。
结语:多模态智能的“系统二”进化
DeepSeek多模态团队也在报告中提到了当前技术的边界。模型在复杂拓扑推理任务上的跨场景泛化能力尚未完善,且思考中视觉基元的激活目前仍依赖显式的触发词,尚未实现完全的自发调用。
但他们也认为,这套框架为多模态社区展示了通往系统二级别的多模态智能的路径。这一路径没有一味地堆高图像分辨率,而在构建了更精准从参照指标。
用空间坐标锚定抽象思维,让模型像人类一样“边指边想”,这本身就是一个值得继续深挖的方向。