
在大模型时代,许多专业人士或许都遇到过类似的问题:当尝试将 DeepSeek-R1 和 OpenAI-o1 这样的卓越推理能力移植到小规模语言模型(SLMs)上时,实际效果往往不尽如人意。尽管现有的强化学习方法 GRPO 对于 7B+ 参数量的大模型来说非常有效,但一旦应用于更小型的模型中,比如 1.7B 或者参数量更少的情况下,性能提升就显得十分有限。
针对小规模语言模型在强化学习中的推理难题,香港中文大学(深圳)T-Lab 的唐晓莹教授带领她的团队成员郭永新和邓文博提出了一个新的算法——G²RPO-A(Guided Group Relative Policy Optimization with Adaptive Guidance),该方法已被 ACL 2026 主会议接受。
新的方法通过在生成过程中注入高质量的思维轨迹,并根据训练情况动态调整指导力度,解决了小模型面临的奖励稀疏问题。实验显示,在 Llama、Qwen 和 DeepSeek 等多个主流模型上,G²RPO-A 在数学推理和代码生成任务上的表现显著优于传统的 GRPO 方法,特别是在 Qwen3-1.7B 上的表现尤为突出:在 MATH500 测试中从 50.96 提升至 67.21,在 HumanEval 中则从 46.08 升高到 75.93。

- 研究揭示了小模型训练过程中的瓶颈在于“奖励稀疏”困境,即由于模型自身能力的限制,面对复杂的推理任务时难以生成高质量的思考链,导致大部分试验无法获得正向反馈。例如,在 Qwen3-1.7B 在代码任务上的奖励分布中可以看出其问题所在。
- 为了解决这一问题,G²RPO-A 并没有简单地提供标准答案给模型,而是在生成的部分轨迹中注入高质量的思维路径,并根据训练状态动态调整指导强度。这种策略有助于缓解小规模语言模型在 RLVR(强化学习虚拟现实)中的先天劣势。
- 该研究团队形象地将这一问题比作“新手司机驾驶手动挡车”:无论引擎如何努力,没有正确的引导依然难以完成复杂的操作任务。这项新方法的核心在于它能够有效地让模型更快、更准确地找到有效的推理策略,而不是依靠简单且固定的指导方式。
- G²RPO-A 的核心创新包含两个关键组件:一是指导机制,在生成轨迹的过程中注入部分高质量的思维路径;二是自适应调整指导强度,根据训练状态动态变化。这使得小模型在面对复杂任务时能够更加灵活地应对奖励稀疏的问题,并且提高了整体的学习效率。
- 作者指出,尽管 G²RPO-A 在数学和代码生成等特定场景中展示了显著的提升效果,但其应用范围仍然有限制:一是主要集中在这些领域内的测试验证;二是指导比率 α 还需要依靠经验搜索来确定,尚未完全实现自适应调整。
通过深入探讨小规模语言模型在强化学习中的瓶颈和限制条件,这项研究不仅提供了一种有效的解决方案——G²RPO-A 算法,还为未来的研究开辟了新的方向。论文和相关代码已经公开发布,可供进一步探索和应用。
一个灵魂拷问随之而来:难道小模型注定与高级推理能力无缘吗?
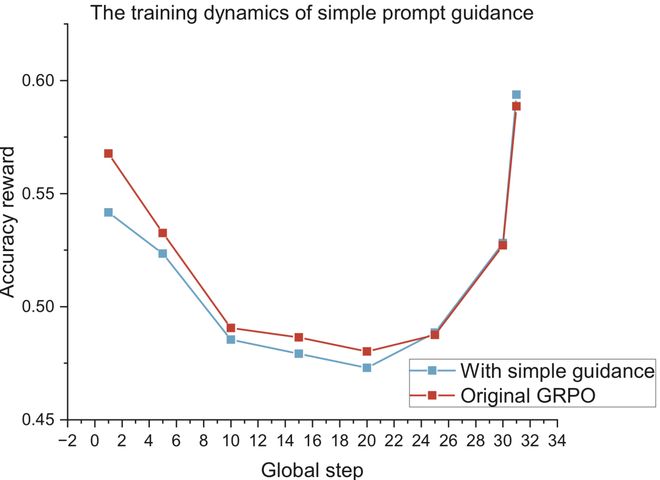
图 1:Naive Guidance 的困境。使用 Qwen2.5-Math-7B 在 s1K-1.1 数据集上训练,简单的固定长度指导在早期训练阶段有短暂提升,但很快与 vanilla GRPO 无异。
一、小模型的「推理瓶颈」到底卡在哪?
当前,尽管 GRPO 等强化学习算法在大模型上取得了巨大成功,但在小规模语言模型(SLMs)上却面临严峻挑战。研究团队通过深入分析发现,问题的核心在于「稀疏奖励」困境:
由于 SLMs 自身能力有限,面对复杂推理任务时,它们很难生成高质量的思考链,导致大部分 roll-out 都无法获得正向奖励。如下图所示,Qwen3-1.7B 在代码任务上的奖励分布极其稀疏:
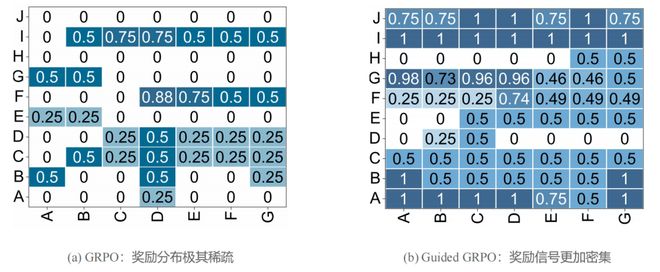
图 2:Qwen3-1.7B 在代码任务上的奖励热力图对比。引入 guidance 后,模型更容易采样到高奖励候选,奖励信号显著变得更密集。
研究团队形象地将其比作「新手司机开手动挡」:无论引擎(模型)如何努力,缺乏正确的引导(指导)依然难以完成复杂的驾驶(推理)操作。
二、G²RPO-A 核心算法架构
为了缓解小模型在 RLVR 中的先天劣势,G²RPO-A 并不是简单地把标准答案喂给模型,而是在 roll-out 的部分轨迹中注入高质量 thinking trajectory,并根据训练状态动态调整 guidance 强度。
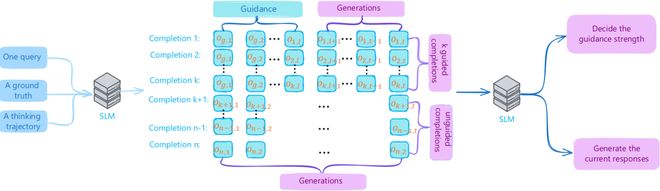
图 3:G²RPO-A 的整体框架。每一步训练都会将 roll-out 分成 guided 和 unguided 两组,再根据当前奖励与历史奖励的比值动态调整后续 guidance length。
G²RPO-A 的核心创新包含两个关键组件:
- 指导机制(Guidance Mechanism):在模型生成 roll-out 的过程中,注入部分高质量的思维轨迹作为引导,使 SLM 朝向生成更高质量候选答案的方向发展。

三、关键发现:
为什么简单指导行不通?
研究团队首先验证了 naive guidance 的效果,发现简单的固定长度指导效果有限。更关键的是,在基于 Math-220K 子集的训练动态分析里,这种「看起来更容易拿到奖励」的做法并没有真正带来更健康的优化信号:
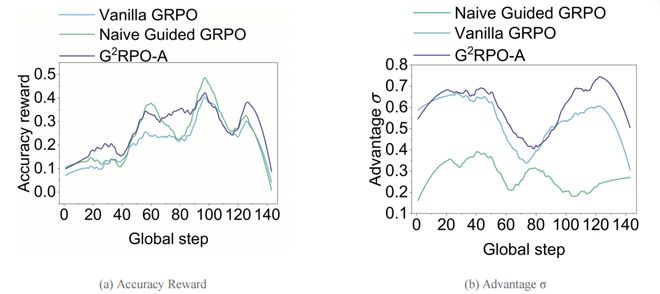
图 4:Naive Guided GRPO 的陷阱。论文在基于 Math-220K 子集的训练动态中发现,naive guidance 虽然能短暂抬高 reward,但其 advantage 标准差极低,严重阻碍了 SLM 的训练效率。
换句话说,naive guidance 的问题不在于「完全没帮助」,而在于它只是让模型更容易采到一些高奖励候选,却没有同步保住足够有区分度的 advantage 信号;结果就是奖励看似变好,训练效率却没有真正提升。
四、主实验结果:
数学和代码上到底涨了多少?
论文做了大量配置实验,首先,最值得展示的其实是主实验结果:在统一训练设置下,直接和 Base、vanilla GRPO、SFT 对比,看看 G²RPO-A 是否真的能把小模型带起来。
配置分析本身给出的核心结论可以先记一句:代码任务通常需要更高 guidance ratio,小模型也通常比大模型更依赖 guidance。这也是作者最后转向「自适应」而不是「固定超参」的直接动机。
先看数学推理主实验。下表来自论文主表,展示了不同 Qwen3 基座在多个数学 benchmark 上的结果:
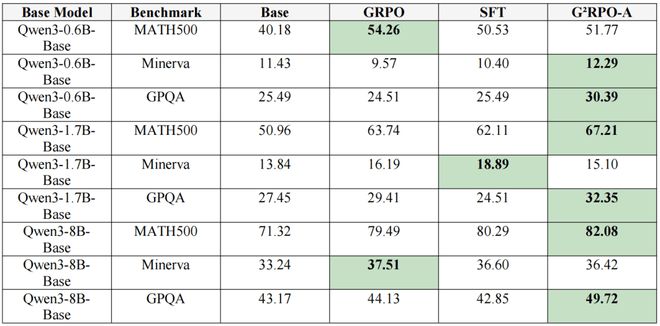
表 1:论文主实验中的数学 benchmark 结果,单位为准确率(%)。
如果只看最有代表性的几组结果,提升是很直观的:Qwen3-1.7B-Base 在 MATH500 上从 50.96 提升到,在 GPQA 上从 27.45 提升到;Qwen3-8B-Base 在 MATH500 上也从 71.32 提升到。论文还补充了更强数学设置下的 AIME 结果,其中 Qwen3-1.7B 在 AIME24/AIME25 上分别达到,高于对应的 GRPO 结果 56.67 和 50.00。
再看代码主实验。这里的趋势也很有意思:G²RPO-A 并不是「每一个单项都绝对碾压」,但整体上在多数 benchmark 上拿到了最优,尤其对小模型的拉升非常明显。

表 2:论文主实验中的代码 benchmark 结果,单位为准确率(%)。
具体来说,Qwen3-0.6B 在 HumanEval 上从 32.32 提升到,LiveCodeBench 上从 17.07 提升到;Qwen3-1.7B 在 HumanEval 上从 46.08 提升到。需要如实说明的是,Qwen3-1.7B 在 LiveCodeBench 上是 SFT 略高,但论文额外给出的 Code-Avg 对比中,G²RPO-A 仍以高于 GRPO 的 60.40 和 Clip-Higher 的 60.19。
五、自适应策略的核心思想
G²RPO-A 的关键不在于「永远加更多 guidance」,而在于根据最近几个训练 step 的奖励变化自动调 guidance length。论文里的更新规则更接近下面这个形式:
指导长度自适应更新规则:
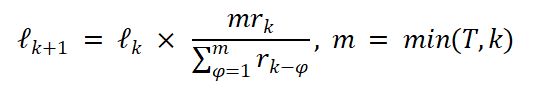
其中,m=min(T,k),ℓₖ 为第 k 步的 guidance length,rₖ 为当前奖励,T 为历史窗口。奖励走高则缩短 guidance,奖励走弱则拉长 guidance。
直观理解:若最近奖励持续上升,则逐步缩短 guidance,让模型自主完成更多推理;若奖励下降,则适当拉长 guidance,降低训练难度。
直觉上,如果最近奖励持续上升,就逐步缩短 guidance,让模型自己完成更多推理;如果最近奖励下降,就适当拉长 guidance,先把训练难度降下来。这比人为预设一个固定 schedule 更贴近论文真正想表达的「adaptive」。
总结与展望
这项工作的价值,不只是提出了一个新 trick,而是把「小模型为什么在 RLVR 里吃不到有效奖励」这件事分析得更清楚:问题不只是模型小,更在于奖励稀疏、advantage 方差信号不足,而且指导强度还会随训练过程变化。
作者也坦言,当前方法仍有两个明显边界:一是验证主要集中在数学和代码任务,跨模态等场景还有待检验;二是 guidance ratio α 仍依赖经验搜索,离真正完全自适应还有一步。
论文和项目仓库都已经公开,这项工作为小规模语言模型在 RLVR 场景中的训练设计提供了一个很有价值的方向。