近日,在科技领域内备受关注的蚂蚁百灵,正式对外发布了 Ling-2.6-flash 大模型。这款拥有 104B 参数总量和 7.4B 激活参数量的新产品,以“Token 效率”为核心特色,能够提供更快、更经济且更加适合大规模实际应用的智能化服务。
自匿名测试版“Elephant Alpha”在 OpenRouter 上线以来,仅一周时间便引起了业界的高度关注。上线后,“Elephant Alpha”的调用量显著攀升,并连续多日位居 Trending 排行榜首位,平均每日消耗超过 100B tokens,每周增长幅度更是超过了5000%。
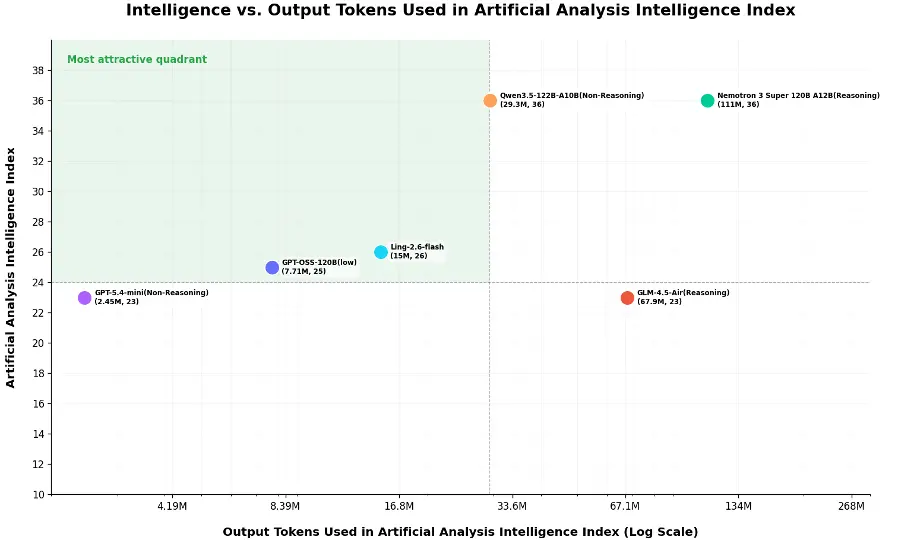
根据第三方权威评测机构 Artificial Analysis 的评估结果显示,Ling-2.6-flash 在“Token 效率”方面表现卓越。在 Intelligence Index 测试中,该模型以仅消耗 15M 输出 token 即获得 26 分的成绩,显示出其在保持智能水平的同时能有效控制输出成本的能力。
对于开发者和企业用户而言,Ling-2.6-flash 的这种高效特性意味着更低的计算开销、更快的响应速度以及更短的整体生成时间。这些优势显著提升了用户体验,并能够更好地满足真实应用场景中对性能、成本与质量的综合需求。
继承了 Ling 2.5 混合线性架构设计的 Ling-2.6-flash,在硬件使用效率上有着明显的优势,尤其是在四卡 H20 条件下表现尤为突出。其推理速度能够达到每秒340 tokens 的水平,并且 Prefill 吞吐量更是 Nemotron-3-Super 模型的 2.2 倍之多。此外,在 Output Speed 测试中,Ling-2.6-flash 以稳定的输出速率位居同级别模型前列。
在 Token 使用效率方面,Ling-2.6-flash 的表现尤为出色。相比其他同类产品如 Nemotron-3-Super 等需消耗 100M tokens 以上的水平,Ling-2.6-flash 则仅用约十分之一的 token 数量便完成了相同的任务测试,充分展示了其在智能效率方面的显著优势。