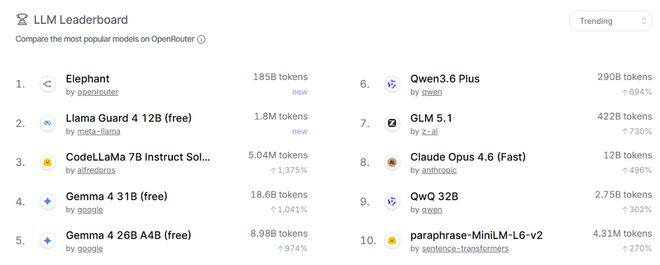
 近日,一款名为Elephant(大象)的匿名AI模型在OpenRouter平台低调登场。上线短短两天内,这款模型便跃升至OpenRouter热门榜首位,并且调用量已超过1850亿个token。
近日,一款名为Elephant(大象)的匿名AI模型在OpenRouter平台低调登场。上线短短两天内,这款模型便跃升至OpenRouter热门榜首位,并且调用量已超过1850亿个token。
在OpenRouter的日排名中,Elephant位列全球第八。
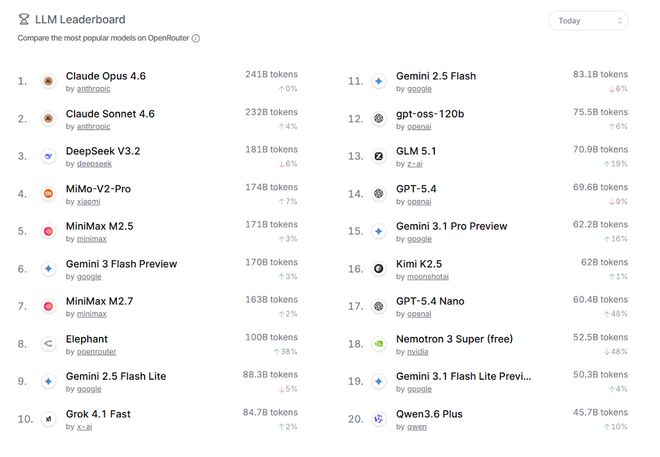
据OpenRouter的介绍,Elephant是一款拥有100B参数量的纯文本模型。它的亮点在于高效的token效率和强大的上下文支持能力,可处理长达256k的输入及最多32k的输出内容,适用于代码补全、调试、文档快速生成以及轻量级Agent交互等场景。
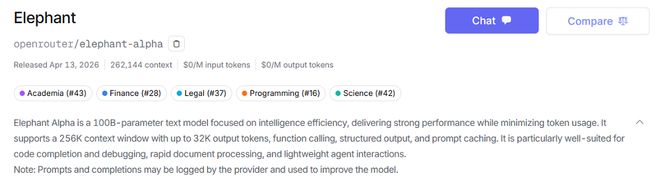
尽管Elephant在众多网友反复测试后仍未透露其真正身份,但有猜测认为这可能是来自国内的新一代模型或国外实验室最新的研究成果之一。
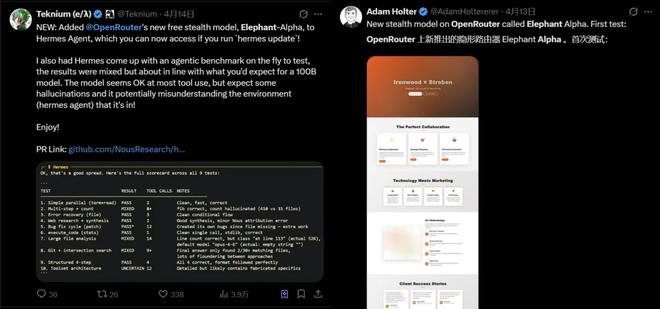
许多开发者分享了他们使用Elephant后的体验感受。一位Hermes Agent的作者对其进行了基准性能测试,并发现该模型在大多数工具调用任务中表现出色,尽管偶尔会出现幻觉及对环境理解上的偏差,但考虑到其规模(100B参数量),这些情况也是可以接受的。
另外,Elephant的一个显著特点是输出速度极快。据OpenRouter数据显示,该模型平均每秒能处理约67个token,并且首token响应时间仅为0.89秒,在即时交互体验方面展现出了极大的潜力。有用户感叹这是他使用过的最快速的模型之一。
接下来,我们将亲自测试Elephant在编程、文档生成和Agent交互等任务中的表现如何。
一、实际操作验证:前端编程响应迅速,支持多轮工具调用
在OpenRouter上,Elephant的编程能力名列前茅。我们首先尝试了几个小型项目来检验它的效率。
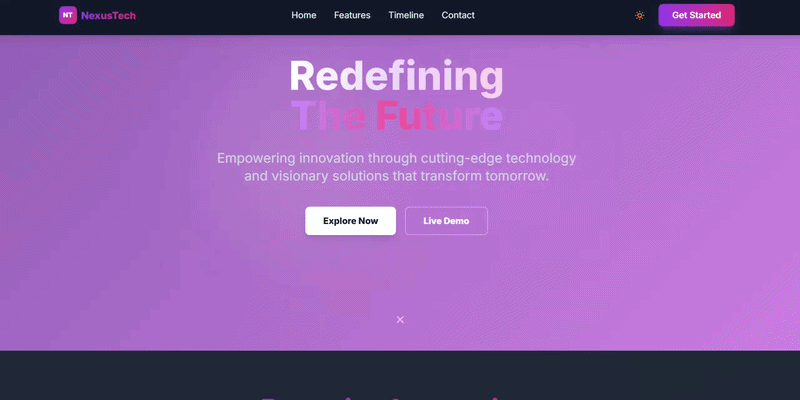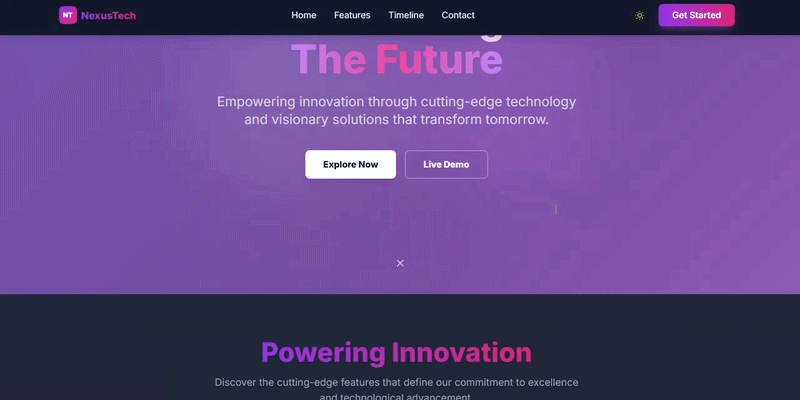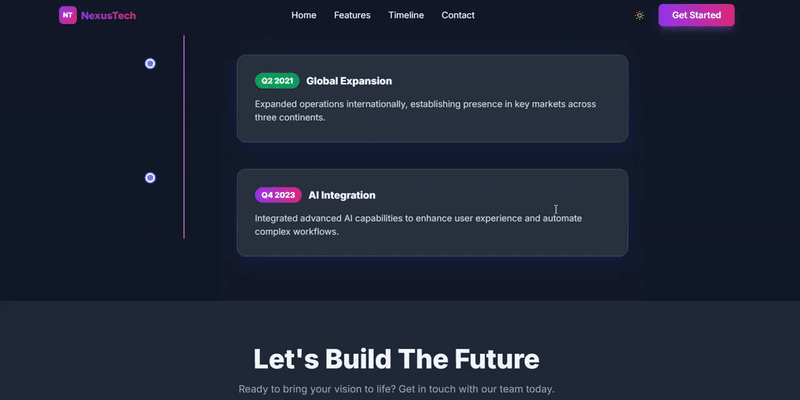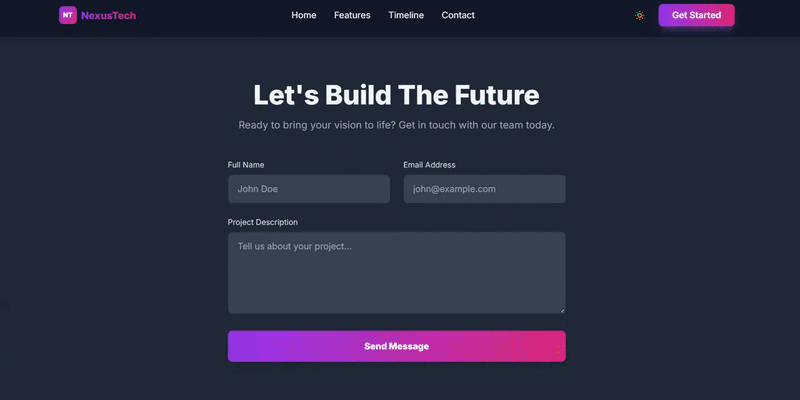
我们测试的第一个场景是一个网页开发任务,这主要是评估模型的前端设计能力。在接收到具体要求后,Elephant迅速制定了网站的核心组件规划,并自行添加了暗模式切换和移动设备适配功能,在不到一分钟的时间内完成了整个项目。
当我们请求其将主色调更改为绿色时,该模型仅用了几秒钟就完成了修改,相比其他模型通常需要通读全部内容并逐一调整而言,这无疑大大提升了效率。
我们还测试了Elephant在处理更大规模任务的能力。让其根据自身知识复现一个支付软件的应用程序,并通过Kilo Code插件体验它的编程功能。尽管最终实现的版本仅是初步原型,但多个子代理同时工作的效果显著提高了整体输出速度。
另外,在面对长文本场景时,Elephant同样表现出色。我们向它发送了一份详细的IPO文件并要求解读企业的基本面信息。该模型能在短时间内高效完成复杂的指令,并快速整理出所有关键数据。
我们还尝试了让Elephant参与一个类似于OpenClaw的开放式Agent任务:规划一次泰国七日游,包括搜索景点注意事项和定位等步骤。
在这个过程中,Elephant能够充分利用自身框架提供的各种工具来完成目标。它成功地为行程规划提供了合理建议,并且还利用高德地图为我们找到了具体的地点位置信息。

通过几个任务的测试后,我们发现Elephant在执行快速和频繁的任务时展现了出色的速度与响应能力,在前端开发、长文本处理方面表现出色,但对于复杂的项目级应用则略显不足。总体而言,它是一款非常适合轻量级高频任务需求的强大模型。
二、第三方评估:指令遵循度满分,token效率媲美GPT-5.4 Mini

Elephant在AI Benchy等第三方基准测试中的表现如何?这些平台提供的数据通常具有较高的参考价值。
AI Benchy是一个用于验证模型真实性能的民间工具。它主要评估模型在执行指令时的遵循度和实际性价比,这对于开发者而言至关重要。
虽然Elephant并未进入AI Benchy的第一梯队,但其高token效率却令人印象深刻,在相同参数量级内表现突出。

在消耗token方面,与同类产品相比,Elephant能够以更低的token使用量完成同样的任务,这与其竞争对手如GPT-5.4 Mini处于同一水平线上。这种高效的特点尤其适合大规模用户场景和日常重复性工作。
特别是在Agent应用场景下,高效率意味着模型可以执行更多轮操作而不会耗尽资源。
此外,在响应时间方面,Elephant能够迅速给出反馈,基本实现秒级延迟,极大地提高了用户体验的满意度。
与此同时,谷歌CEO Sundar Pichai也曾提到,“低延迟”是优质产品的一个关键特性,它不仅体现了技术架构的强大,还直接影响到了用户的实际感受。
而指令遵循度方面,Elephant也获得了满分的成绩和100%的通过率,这意味着该模型在执行任务时表现得非常可靠。
总结:高效模型同样具有重大价值

在测试初期阶段,并没有被Elephant的基础能力所震撼。然而,随着深入实际应用场景后,它的实用性和优势逐渐显现出来。
当前业界的趋势是追求更大的规模和更复杂的答案生成。但在现实的业务流程中,使用大规模模型处理基础性任务无疑是一种资源浪费。

因此,根据具体任务需求选择合适的模型大小成为当前共识,每个token都应该被合理利用以提高效率。
在反映真实调用量的OpenRouter平台上,曾经只由大型模型占据主导地位的局面正在发生变化。一批注重“token效率”的小型精锐模型开始崭露头角。
这并不是否定旗舰级模型的能力,而是在工程实践中更加理性地选择适合任务需求的产品。

在实际应用中,能够以最低成本实现快速响应的模型正展现出成为未来Agent操作系统的重要潜力。
其实,在最初测试Elephant模型时,我们并未被它的基础能力惊艳,甚至一度有所怀疑。但随着深入真实任务场景,它的实用价值才真正显现出来。
当前,前沿模型的规模正不断扩大,生成的答案也越来越长。然而在真实的业务流水线中,用万亿参数模型去处理基础文本分类或信息抽取,无异于“大炮打蚊子”:既浪费算力,又导致token无意义消耗和时延飙升。
正因如此,剥离对庞大体量的迷信,根据任务复杂度精准匹配模型尺寸,让每一个token都用在刀刃上,已经成为大模型规模化落地过程中,开发者和企业的共识。
在能反映真实调用量的OpenRouter平台上,曾由超大规模模型垄断的榜单,正被一批讲究“token效率”的精锐小模型打破。这并非是对旗舰模型能力的否定,而是工程理性回归的信号。相较于那些参数量最大、最“智能”的模型,那些能以最低成本、最快响应速度完成任务的模型,正展现出成为Agent操作系统的成长潜力。