DeepSeek近日在GitHub上公开了一款多模态推理模型及其技术报告《以视觉原语思考》。
这个模型基于DeepSeek V4-Flash架构(总计参数量为284B,实际运行时激活的参数数量为13B)开发而成,并提出了一种新的多模态推理方式。

研究指出当前市面上的许多大型多模态模型存在一个未被充分重视的问题:“指代鸿沟”(Reference Gap),即尽管这些模型能够识别图像中的内容,但在用自然语言描述视觉对象时却难以精确表述,特别是在复杂的场景中容易造成注意力分散并产生错误判断。
过去的学术研究主要致力于提高感知清晰度,但报告强调看见和准确表达是两个独立的概念。
该模型的关键创新在于将点坐标及边界框融入推理过程之中,使其成为构建思维链的重要组成部分。当模型提及某个视觉元素时,会实时输出对应的坐标信息。
比如,“发现一只熊位于[452,23,804,411]的位置正沿着树爬升,排除;继续向左下方观察,在[50,447,647,771]处找到了另一只站在岩石边缘的熊”,坐标信息不再仅仅是最终答案的一部分,而是在推理过程中帮助减少歧义的关键点。

从架构角度看,该模型实现了视觉数据压缩率高达7056倍的效果。一张尺寸为756×756像素的图片经过ViT处理后生成2916个图像块token,再经由3×3的空间压缩技术减少至324个token,并借助压缩稀疏注意力(CSA)机制进一步缩小到81个视觉KV条目。
比较之下,同样大小的图片使用Claude Sonnet 4.6和Gemini-3-Flash模型分别需要大约870个及1100个token。
在训练数据选择上,研究团队从近十万的目标检测数据库中精选出约三万一千七百个高质量的数据源,并基于这些信息生成了超过四千万条的训练样本,涵盖了计数、空间推理、迷宫导航以及路径追踪等四个领域的任务。
训练阶段采用先分别对边界框和点坐标进行专业化训练,然后通过强化学习优化并在线策略蒸馏整合为单一模型的方式进行。
实验结果表明,在与Gemini-3-Flash、GPT-5.4及Claude Sonnet 4.6等主流多模态推理模型的对比测试中,Pixmo-Count在多个基准上取得了优异的表现。
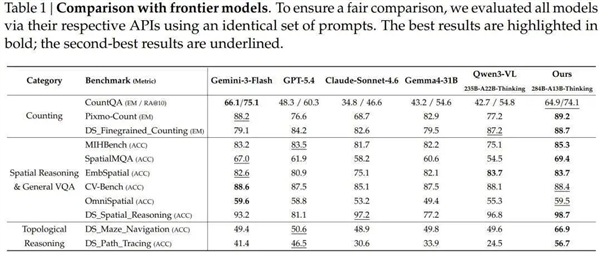
计数任务方面,Pixmo-Count获得了89.2%的精确匹配得分,高于Gemini-3-Flash的88.2%,远超GPT-5.4的76.6%和Claude Sonnet 4.6的68.7%。
在拓扑推理任务中,尤其是迷宫导航与路径追踪方面,该模型展现出了显著的优势:在迷宫导航测试中得分达到66.9%,GPT-5.4为50.6%,Gemini-3-Flash为49.4%,Claude Sonnet 4.6则仅为48.9%;而在路径追踪任务上,其得分更是高达56.7%,相比之下GPT-5.4仅得46.5%。
然而报告也指出了一些当前的局限性:模型必须通过特定触发词来激活视觉原语机制,在细节极高的场景中坐标精度受限,并且跨环境的应用能力尚待进一步提高。
