
构建可靠LLM API:抵制低质、过度收费与配置削减
该研究由新加坡国立大学和加州大学伯克利分校的学者联合完成。新加坡国立大学的郭衍培是本文的第一作者,他长期研究大语言模型基础设施中的可信性和安全性问题,尤其是云端 LLM 服务的验证性和经济激励风险。他的导师是新加坡国立大学的青年教授张嘉恒和加州大学伯克利分校的 Dawn Song 教授。大语言模型(LLM)已经成为众多人工智能应用的基石。然而,尽管通过云端 API 访问这些模型十分方便,但这种“黑
科技4 阅读
共找到 98 篇相关文章
该研究由新加坡国立大学和加州大学伯克利分校的学者联合完成。新加坡国立大学的郭衍培是本文的第一作者,他长期研究大语言模型基础设施中的可信性和安全性问题,尤其是云端 LLM 服务的验证性和经济激励风险。他的导师是新加坡国立大学的青年教授张嘉恒和加州大学伯克利分校的 Dawn Song 教授。大语言模型(LLM)已经成为众多人工智能应用的基石。然而,尽管通过云端 API 访问这些模型十分方便,但这种“黑

编译 | 陈骏达你提到你最近一直在探索将大型语言模型简化到最核心的版本,这个项目被命名为micro GPT。你认为这个项目能帮助人们更好地理解和使用语言模型。你提到micro GPT是目前你所能构建的最精简的语言模型代码,整个训练代码只有200行Python(包括注释)。这个模型非常易于理解,因为它不涉及任何为了加速训练而复杂化的代码。通过这个项目,你希望能够向更多人展示语言模型训练的本质。你提到
新智元报道在最近举行的美国物理学会全球物理学峰会上,一场有关人工智能是否会取代物理学家的研讨会吸引了众多参会者的关注。研讨会上,哈佛大学的理论物理学家马修·施瓦茨大胆预言,人工智能将在未来五到十年内超越人类智能。他认为,借助人工智能,一个世纪内可以培养出一万位类似爱因斯坦这样的天才科学家,彻底革新科研方式。施瓦茨指出,目前大型语言模型的能力正以每年十倍的速度增长,而人类智能却停滞不前。人类的智慧并

机器之心编辑部近年来,扩散语言模型(Diffusion LLM)一直是讨论的热点。相较于传统的自回归模型,扩散模型在生成文本时更为灵活,更能支持并行处理。然而,尽管这条路充满潜力,但要真正提升效果却并非易事。最近,华为诺亚方舟实验室发布了一项关于扩散模型训练中“默认设置”的研究。这项研究的标题为《Mask Is What DLLM Needs: A Masked Data Training Par

快科技3月22日消息,NVIDIA研究人员推出一项全新技术KVTC(KV快取转换编码),能把大型语言模型(LLM)追踪对话历史的内存用量,最高缩减20倍,而且不用修改模型本身。这一突破有望解决大型语言模型长对话推理时的内存不够用问题,大大降低企业使用AI的硬件成本,同时还能把模型首次生成回应的时间,最高提速8倍。简单来说,KVTC技术的核心就是压缩大型语言模型背后的KV缓存——它相当于AI模型的“

对于那些想要快速开发网页小游戏、交互式动画或是教学演示的人来说,复杂的代码逻辑和多元素交互调试往往令人头疼。虽然目前的大语言模型和AI代理能够帮助编写代码并构建交互场景,但在处理复杂交互时却容易出错,而且纯文本的交互方式难以直观地调整视觉效果。最近,来自香港浸会大学、香港科技大学、香港城市大学及深圳大学的研究团队共同开发了一款名为MoGraphGPT的创新系统。该系统结合了上下文感知模块化大模型与

大语言模型的发展进入了一个全新的阶段,即万亿参数时代,这为大模型的推理与部署带来了前所未有的技术挑战。特别是在超节点(SuperNode)复杂的异构存储架构下,如何高效管理与调度海量张量,成为决定大模型能否成功落地的关键因素。最近,上海交通大学可扩展计算研究所的蒋力和刘方鑫教授团队与华为MindSpore团队合作,发布了一份技术报告,题为《HyperOffload: Graph-Driven Hi

目前,测试时扩展已成为提升模型推断能力的重要途径。在这个领域内,块扩散语言模型(BDLMs)因为其独特的并行解码特性,被认为是自回归模型效率的强有力竞争者。然而,现有的 BDLMs 在处理长链推理任务时面临一种困境:它们必须在速度和准确性之间做出选择。大块解码虽然速度快,但在复杂情境下容易出错;小块则能保证准确度,但会牺牲解码效率,失去并行计算的优势。此外,当前的解码策略(例如固定置信度)无法应对

吴嘉赟博士就读于卡内基梅隆大学(CMU)机器学习系,专注于大语言模型评估和后训练技术的研究。大语言模型在关键领域的应用受到幻觉问题的困扰。最近一项研究提出了一种新的行为校准强化学习方法,旨在解决这一难题。该论文详细探讨了如何通过调整奖励函数来改进LLM的表现。经过特定训练后,一个参数量仅为40亿的小型模型在幻觉抑制方面超越了GPT-5等顶级大模型。图1展示了模型回答数学问题时置信度标注的实例。每一
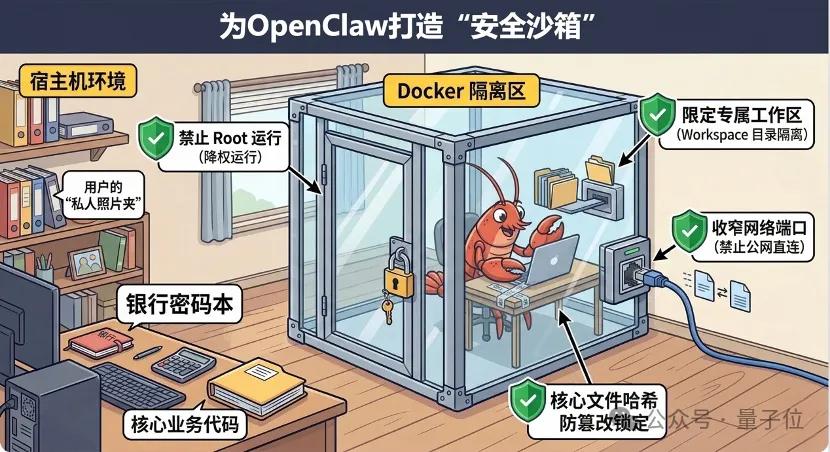
最近,“赛博龙虾”这一绰号的开源AI智能体OpenClaw在网络上迅速走红。 随着应用热度不断上升,各地政府陆续出台相关扶持政策,从企业和个人开发者到政府机构,部署OpenClaw已成为一种新兴趋势。 该工具通过整合通信软件和大型语言模型,能在用户的计算机上自主完成文件管理、邮件发送接收及数据处理等任务。同时,智能体可以直接调用系统资源执行指令,这带来了新的安全挑战。 工业和信息化部网络安全

机器之心编辑部今天看到一张令人捧腹的梗图:近期,OpenClaw 引起了广泛关注,但高昂的成本让许多用户感到压力巨大。腾讯 推出了基于 OpenClaw 开源生态的 QClaw 版本,旨在简化安装流程,方便普通用户使用。现在,即使是非专业人士也能轻松体验「小龙虾」的魅力了。类似于 OpenClaw,QClaw 让人们能够通过对话的方式控制电脑,并连接主流大语言模型如 DeepSeek、Kimi 和

新智元报道LyapLock 是一种创新技术,首次实现了大型语言模型在大量知识更新中的稳定记忆维护与精准学习能力提升。该方法采用“虚拟队列”机制来实时监控遗忘风险,并通过动态调整新旧知识的平衡,确保长期性能不下降。大型语言模型常常包含错误或过时的信息,因此需要精确的知识更新技术。然而,当前主流的编辑策略在连续编辑过程中逐渐失去效能。针对这一问题,中国科学院信息工程研究所的研究人员提出了LyapLoc

最近,“养龙虾”的活动在网络上迅速流行起来。开源AI智能体工具OpenClaw因其图标形似红色龙虾而得名,它可以通过调用通讯软件和大语言模型,在用户的电脑上自主处理诸如文件管理、邮件收发及数据整理等复杂任务。随着“养龙虾”风潮的蔓延,多家企业已经正式宣布推出相关的“龙虾”版本,并且部分地区的政府机构也开始将该工具应用于政务服务领域。不过,“养龙虾”的行为也带来了不少的风险和隐患。3月11日,在社交
中国信通院 CAICT 公众号于今日发布文章称,开源 AI 智能体工具 OpenClaw 近期在网络上引起广泛关注,同时也带来了严峻的安全问题。此智能体因其图标形似一只红色龙虾而被网友昵称为“龙虾”,能够通过整合调用通信软件与大语言模型,在用户的电脑上执行文件管理、邮件收发和数据处理等复杂任务。尽管该工具具备强大的自主操作能力,但也给用户带来了严峻的安全挑战。工信部网络安全威胁和漏洞信息共享平台已

大语言模型在数学计算、指令执行和智能决策方面表现突出,展现出强大的思考能力。然而,在实际应用中,一个问题逐渐显现:大语言模型的推理成本难以控制。在一些看似简单的任务上,模型有时会过度思考,生成冗长且发散的答案,浪费大量计算资源却未能提高准确性。我们称这种现象为“过度思考”。对于复杂问题而言,由于预算限制,模型可能在关键环节草率作答,导致错误频出,这被称为“思考不足”。目前主流的做法是通过统一减少推

最近,「AI 教父」杨立昆终于有机会证明他的观点:大语言模型并非通向通用人工智能的正确道路。作者|桦林舞王当地时间 3 月 9 日,由他创立的 AMI Labs 宣布完成了一轮融资,金额达 10.3 亿美元,估值达到 35 亿美元——这是欧洲历史上最大的种子轮之一。投资者包括了英伟达、贝索斯家族的投资机构以及新加坡淡马锡等知名公司,同时还有一众科技界重量级个人投资者如 Tim Berners-Le

这是一次关于AI技术发展及其对软件工程影响的深入对话,探讨了从模型设计到应用实践等多个方面。 本次访谈中,Jeff Dean分享了他对当前大语言模型的看法,并强调了未来的发展趋势。 在讨论多模态能力时,Dean指出,早期强调视频输入是为模型提供最高带宽的沟通方式。 关于Gemini项目的起源和进展,Dean提到多个团队独立研发算力分散的问题及整合后的成果。 谈话中还探讨了在编程任务上使用AI助手

近期arXiv面临投稿量激增的问题,连这个平台也感到压力山大了。 一项由《自然》杂志报道的新研究显示,AI“水论文”现象愈发严重,这项研究的发起人之一是arXiv的创始人Paul Ginsparg。 arXiv负责人亲自介入的原因很简单:近年来投稿量激增导致系统不堪重负,而问题源头很可能是AI技术的发展。 为了验证这一点,研究人员测试了13个主流的大语言模型,看看当用户明确要求“编造数据”、“虚

从傅盛的分享中可以感受到他对AI技术的深刻理解和应用体验。他强调了AI在自动化执行任务方面的能力,并认为“三万”龙虾能极大地提升效率和创造力。凤凰网科技 出品作者|赵子坤傅盛提到,尽管大语言模型如EasyClaw(简称“三万”)能够完成许多复杂的任务,但它仍需人类设定明确的目标才能发挥作用。这说明了AI在自主决策上存在局限性。他指出,当前社会中技能交换的模式正在发生变化,人们需要从基础教育开始适应

据Torrentfreak报道,Meta等科技公司曾通过BitTorrent协议从安娜档案库这类盗版资源网站下载受版权保护的书籍,以支持人工智能模型训练。为了构建更强大的语言模型,在没有获得版权所有者许可的情况下,多家技术企业使用了大量受版权保护的内容作为训练数据。Facebook和Instagram的母公司Meta成为了这场集体诉讼中的被告之一。知名作家如理查德·卡德雷、萨拉·西尔弗曼及克里斯托