
大语言模型在数学计算、指令执行和智能决策方面表现突出,展现出强大的思考能力。
然而,在实际应用中,一个问题逐渐显现:大语言模型的推理成本难以控制。
在一些看似简单的任务上,模型有时会过度思考,生成冗长且发散的答案,浪费大量计算资源却未能提高准确性。我们称这种现象为“过度思考”。
对于复杂问题而言,由于预算限制,模型可能在关键环节草率作答,导致错误频出,这被称为“思考不足”。
目前主流的做法是通过统一减少推理中的token上限来节约算力。然而,这种方法仅能防止无意义的过度思考,却无法提升复杂问题上的准确性,甚至可能导致答案质量下降。
实际上,关键并不在于使用的算力总量,而是在于如何有效分配这些计算资源。
论文标题为《计划与预算:推理大型语言模型测试时间的有效和高效扩展》,探讨了如何在保持准确性的前提下优化推理效率。
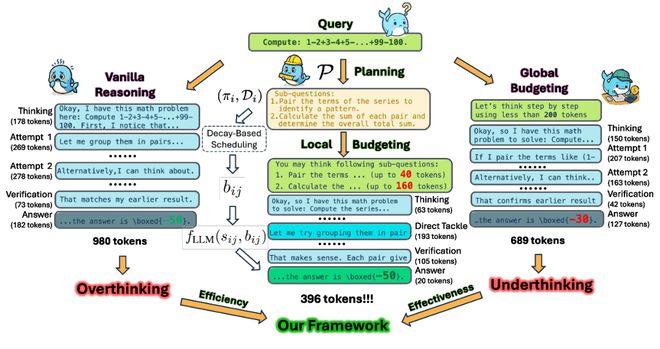

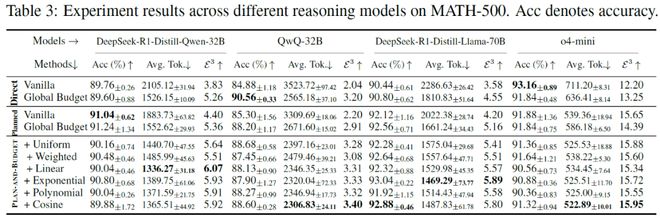
- 本研究详细分析了各种主流推理模型(如DeepSeek R1、QwQ及OpenAI o4-mini等)的行为特征,并指出这些模型普遍存在的“推理失衡”现象——即计算资源分配与实际问题难度不匹配的问题。
- 具体而言,模型在非关键环节投入过多的思考时间,在真正决定成败的关键步骤上却不够深入。这种不平衡导致了过度思考和思考不足并存的现象。
- 进一步的研究发现,推理过程中的不确定性变化是造成这一现象的主要原因:在早期阶段,由于认知不确定性较高,模型需要更多的计算资源来降低不确定性;而随着推理进展,后续步骤的确定性增加,继续花费大量资源进行冗长思考的边际收益急剧下降。
二、核心洞察:
这一发现表明,提高推理效率的关键在于如何合理地分配计算资源,而非单纯的算力总量。
为了应对这一挑战,论文提出了BAM(不确定性驱动的计算分配模型),旨在优化大型语言模型在推理阶段中的预算分配策略。
BAM的核心理念是根据认知不确定性的高低来指导token的分配。简单来说,在早期的高不确定性步骤上投入更多资源,而在后续确定性较高的环节则适当减少资源使用。
通过这种方式,BAM能够更有效地利用计算资源,避免在无意义的地方浪费算力,并确保关键步骤得到充分思考。
基于这一理论模型,研究团队提出了Plan-and-Budget框架。该框架能够在不修改现有模型的前提下优化推理过程中的预算分配策略。
- Plan-and-Budget分为两个主要阶段:规划和预算。首先,在推理开始前进行高层次的规划,明确每个子问题的角色与重要性;然后根据BAM的原则灵活地将token资源分配到各个关键环节。
- 实验结果表明,Plan-and-Budget不仅能够提高准确率,而且还能显著减少平均使用的token数量,实现了真正的高效推理。
为了更客观地评估不同方法的效果,论文提出了E³指标,旨在综合评价计算效率和准确性。该指标奖励那些用较少资源得到更好答案的方法,并惩罚依赖大量算力或牺牲正确性的策略。
结果显示,在多种任务(包括数学推理、指令理解和执行以及代理决策)中,Plan-and-Budget框架都表现出色:最高可提高70%的准确率和减少39%的token使用量,同时E³指标提升高达193.8%。
这些成果表明,“按需分配推理资源”可以显著提升大型语言模型的实际应用价值。
三、理论突破:
未来的智能系统需要更加高效、可控,并且能够根据实际需求灵活调整计算策略。通过引入“按需推理”的理念,我们有望构建出既经济又可靠的智能化解决方案。
当大模型学会在适当的时候深入思考,在不需要时及时收手,那么这些系统的推理能力才会真正变得成熟和可靠。
Junhong Lin(林俊宏),麻省理工学院计算机科学与人工智能实验室博士生,主要研究方向为大规模语言模型的推理效率与可靠性。
Xinyue Zeng (曾欣悦), Virginia Tech VLOG Lab 二年级研究生, 主要专注于大语言模型推理稳定性和可靠性的研究。
其他相关信息请参见论文原文,此处不再赘述。
- 理解题目在问什么
- 分析条件之间的关系
- 构思整体解题思路
这个阶段充满不确定性,如果没想清楚,后面算得再快也可能全错。但一旦
- 每一步都很确定
- 再花太多时间,收益其实不大
这正是推理过程中不确定性变化的真实写照。
2)BAM 的核心思想:用 “不确定性” 指导算力分配
基于这一观察,论文提出了BAM(Budget Allocation Model),将一次 LLM 推理看成由多个子问题(sub-questions)组成的过程,并用一个关键概念来指导预算分配 ——认知不确定性(epistemic uncertainty)。认知不确定性刻画的是:
“在这一步,多想一点,是否真的能让模型理解得更清楚?”
在理论上,我们借鉴了神经网络缩放定律的思想,用一个简洁的模型来描述token 数量与不确定性降低之间的关系
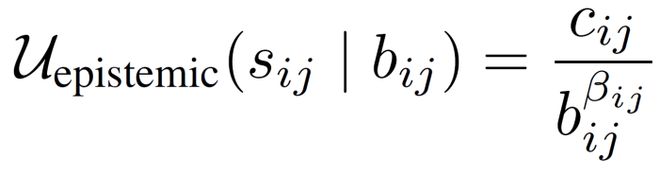
这个公式可以直观地理解为:
- bij 表示分配给某个子问题的推理 token(也就是思考时间)
- 分配的 token 越多,不确定性确实会下降
- 但下降速度会越来越慢,存在明显的边际收益递减
也就是说,前几个 token 非常 “值钱”,而后面的 token 往往越来越 “划不来”。这正是为什么简单地拉长推理链条,并不能无限提升推理效果。
3)在总预算有限的情况下,token 应该怎么分?
有了上述建模,BAM 进一步提出了一个明确的问题: 在总推理预算有限的前提下,如何把 token 分配给不同的子问题,才能让整体推理最有效?
通过优化整体不确定性,论文推导出了一个最优预算分配原则:
这条公式背后的含义,其实非常 “人性化”:推理预算应该更多分配给那些一开始不确定性高、但又确实能通过思考被有效消除的步骤。
回到考试的类比:
- 分值高、靠想能拿分的题 —— 值得多花时间
- 已经很确定的计算步骤 —— 快速完成即可
- 怎么想也想不明白的题 —— 及时止损,避免浪费时间
BAM 的核心思想可以用一句话概括:
像考试分配答题时间一样,把推理算力用在 “想明白思路” 的阶段,而不是平均或盲目地拉长整个推理过程。
四、Plan-and-Budget:
让理论真正落地的推理框架
基于 BAM 的理论原则,研究团队进一步提出了Plan-and-Budget—— 一个完全在推理阶段运行、无需任何训练或微调的通用推理框架。它的目标很明确:在不改变模型本身的前提下,让推理算力用在最关键的地方。
整个框架可以概括为两个步骤:先规划,再分配。
① Plan:先把 “大题” 拆清楚
在推理开始前,Plan-and-Budget 会先对原始问题进行一次高层次的规划(planning),将复杂问题拆解为一系列结构化的子问题。
这一步的作用并不是让模型 “想得更长”,而是想得更有方向
- 明确每一步在整体推理中的角色
- 避免在无关分支上反复探索
- 把 “思考路径” 从一开始就理顺
直观来说,这相当于考试时先写草稿、定解题思路,而不是一上来就开始乱算。
② Budget:把 token 用在 “最值钱” 的步骤上
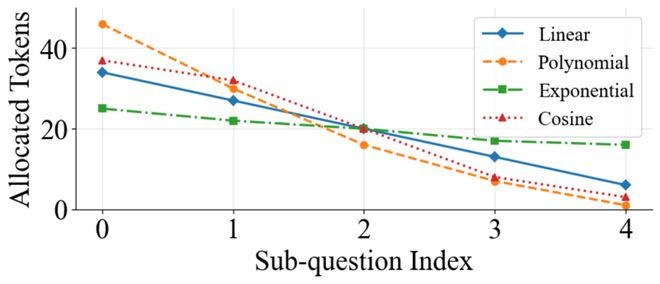
在完成规划之后,Plan-and-Budget并不会给每个子问题平均分配推理 token,而是采用一种前置衰减(decay-based)的预算分配策略(当然,也支持按照问题类型灵活采用其他预算分配策略)。
这种策略的核心思想是:
- 推理早期步骤不确定性更高,对最终答案影响更大
- 推理后期步骤往往更确定,继续长篇推理的边际收益较低
因此,框架会:
- 在前几个关键子问题上分配更多 token
- 随着推理推进,逐步减少每一步的推理预算
这正是在实践中对 BAM 最优分配原则的一种近似实现。
五、实验结果:
不仅更准,还更 “算得值”
前面的理论和算法,最终都要回到一个现实问题:
Plan-and-Budget 到底有没有在 “省算力” 的同时,真正提升推理质量?
1)先看一个直观对比:不同难度题目的表现
下图展示了在 TravelPlanner 任务中,不同方法在 简单 / 中等 / 困难 三种问题难度下的通过率(Pass Rate)对比:
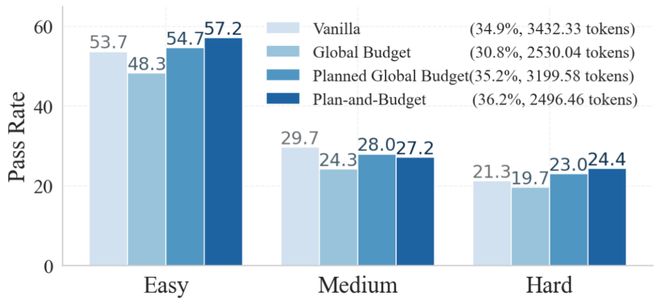
这张图里有一个非常值得注意的现象:
- Global Budget(全局限制 token)在所有难度上都明显降低了通过率 —— 尤其是在中等和困难问题上,性能下降最为明显
- 这说明:单纯缩短推理过程,确实会 “省 token”,但往往是以牺牲正确性为代价的
相比之下,Plan-and-Budget 在三个难度级别上都取得了最高的通过率
- 简单问题:避免了无意义的 “过度思考”
- 中等问题:在关键步骤上给足思考空间
- 困难问题:显著优于全局 budget 方法,体现出结构化推理的优势
2)关键不只在 “对不对”,还在 “花了多少 token”
更重要的是,Plan-and-Budget 的提升并不是靠 “多用算力” 换来的。从图例中可以看到:
- 在通过率更高的同时,Plan-and-Budget 的平均 token 使用量反而更低
- 这说明:结构化规划 + 局部预算分配,真的把算力用在了最关键的地方
也正是因为这个原因,论文认为: 仅用准确率或 token 数量来评价推理方法,都是不够全面的。
3)E³ 指标:把 “准确” 和 “高效” 统一到一个量里
为更客观地衡量推理方法在真实部署中的价值,论文提出了E³(Efficiency-aware Effectiveness Score)指标。E³ 的设计初衷非常简单:奖励 “用更少的 token,得到同样甚至更好答案” 的方法, 惩罚 “靠牺牲准确率或盲目堆算力” 的策略。
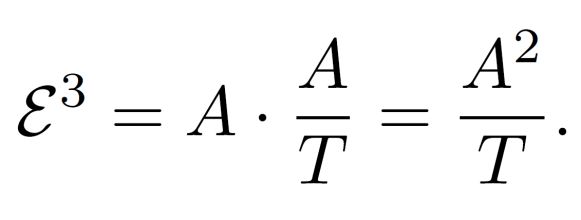
在 E³ 指标下,一些 “强行限制推理长度、但正确率明显下降” 的方法会自然处于劣势; 而像 Plan-and-Budget 这样,在保持甚至提升准确率的同时降低计算成本的方法,则会被清晰地凸显出来。
4)结果总结:为什么这些数字很重要?
综合多种推理任务(数学推理 Mathematical Reasoning,指令理解与执行 Instruction Following,以及规划与决策推理 Agentic Planning)和模型规模,Plan-and-Budget 带来了非常稳定的收益:
- 最高+70%的准确率提升
- 最高−39%的 token 使用量减少
- E³ 指标最高提升193.8%
这些结果共同表明:Plan-and-Budget 并不是 “算得少一点”, 而是 “算得更聪明”。
六、意义与展望:
推理不该是 “算力堆出来的”
随着大语言模型规模不断扩大,推理能力的提升似乎越来越依赖于 “多用一点算力”。然而,这项工作传递了一个不同的信号:推理效果的关键,并不只在于算力多少,而在于算力是否被合理使用。
Plan-and-Budget 从 “推理失衡” 这一普遍但长期被忽视的问题出发,通过不确定性视角建立理论模型,并进一步将其落地为一个无需训练、仅在推理阶段运行的通用框架。实验结果表明,合理的推理规划与预算分配,能够在多种任务和模型上同时提升准确率与计算效率,甚至让中等规模模型在效率上逼近更大模型。
更重要的是,这项研究提出了一种新的推理范式:从 “推理长度” 转向 “推理价值”, 从 “算得更多” 转向 “算得更聪明”。
在未来,随着 LLM 被部署到越来越多对成本、时延和稳定性要求严格的真实场景中,这种 “按需推理” 的思想,或将成为高效、可控智能系统的重要基础。
当模型学会 “什么时候该多想,什么时候该收手”,
推理,才真正开始变得成熟。
作者信息:
Junhong Lin(林俊宏),麻省理工学院计算机科学与人工智能实验室(MIT CSAIL)博士研究生,研究方向包括大语言模型推理、图神经网络与知识图谱。其成果发表于 ICLR、ICML、NeurIPS、KDD、ICAIF 等国际顶级会议,并获得 ACM KDD Best Paper Award 与 ICAIF Best Paper Honorary Mention。研究聚焦于提升大模型在推理效率与可靠性方面的理论建模与系统实践。
Xinyue Zeng (曾欣悦), Virginia Tech VLOG lab 二年级 PhD,研究方向包括大语言模型推理稳定性和可靠性,相关成果发表于 ICML,ICLR,ICDM 等等国际顶级会议。目前致力于构建可解释、可部署的 LLM 评估与推理方法。将于今年暑假以研究实习生的身份加入微软研究院实习。