
机器之心编辑部
近年来,扩散语言模型(Diffusion LLM)一直是讨论的热点。
相较于传统的自回归模型,扩散模型在生成文本时更为灵活,更能支持并行处理。然而,尽管这条路充满潜力,但要真正提升效果却并非易事。
最近,华为诺亚方舟实验室发布了一项关于扩散模型训练中“默认设置”的研究。这项研究的标题为《Mask Is What DLLM Needs: A Masked Data Training Paradigm for Diffusion LLMs》,作者并未改动模型结构,而是聚焦于训练过程中的一个基本但常被忽视的问题:如何进行数据屏蔽。

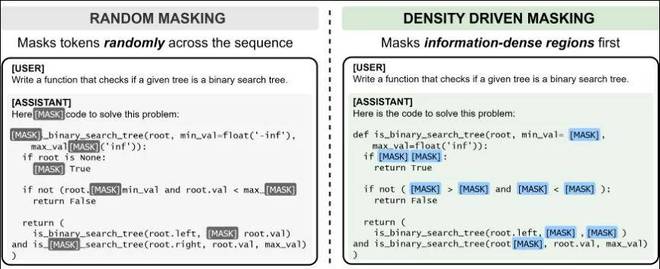
- 研究显示,当前许多离散扩散语言模型在训练过程中采用的均匀随机屏蔽方法,实际上可能导致资源的浪费。
- 这种问题在一般文本中可能不太明显,但在代码和数学推理任务中却尤为突出。因为在这类任务中,决定模型性能的关键往往在于少数几个位置:在代码中可能是条件分支或逻辑判断;在数学中可能是简化步骤或函数替换。这些关键因素比连接词或格式更为重要。真实序列中的信息密度并不均匀,而传统随机屏蔽却默认每个位置的重要性一致,这使得模型在不重要的地方浪费了大量资源。
简而言之,模型在学习时未能区分主次。
并非所有标记都具有同等的重要性
这篇工作的核心观点很简单:
不同标记的信息量不同,训练时的处理方式也应有所区别。
围绕这一观点,作者提出了一种更加智能(Smart)的噪声调度器。它的主要功能是找出样本中的高信息密度区域,并在训练时更倾向于屏蔽这些位置,迫使模型学会恢复关键信息。
这种设计背后的直观想法是,人在完成填空题时,也不会觉得填空号和填关键结论的难度一样。真正能够拉开差距的是那些牵一发而动全身的关键位置。
先识别重点,再决定如何屏蔽
在具体操作上,作者首先进行了高信息密度区域的提取(Step 1)。
对于代码和数学数据,作者设计了不同的标准。提取出的关键信息区域会在原始序列中被标记,后续的训练过程会参考这些特殊标记。
接着进入屏蔽阶段(Step 2)。与传统做法不同,这里并不是每个位置都被屏蔽的概率相同。作者将序列分为两类:一类是高信息密度的优先区域,另一类则是普通区域。前者被赋予更高的屏蔽概率,后者则保持较低概率。同时,整体的屏蔽比例仍然被控制住,不会因为对某些位置的“偏心”而影响整个噪声调度。
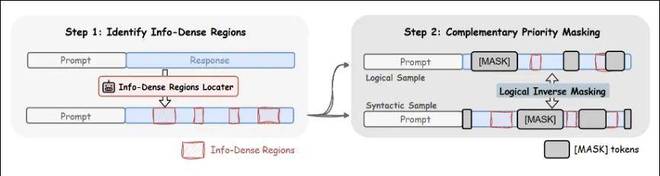
这个设计的关键在于,它并不是简单地“多遮一些”,而是把训练的难度集中在真正值得学习的地方。
另一个巧妙的设计:一条数据,两种训练视角
如果仅仅优先屏蔽高信息区域,可能会担心模型是否会过度专注于特定任务,而忽略了语言结构本身。
为此,作者引入了扩散模型训练中常用的互补屏蔽。
具体做法是:训练器会根据前文标记构造一个优先级屏蔽,同时还会构造其完全逻辑互补版本。这样,同一份样本就能从两个互补视角进行训练:一个关注逻辑结构,另一个则更多地保留关键位置,让模型处理结构、语法和上下文连贯性。
这种互补屏蔽与优先级屏蔽相结合的设计,使得训练效果大大提升,因为它没有简化为“只需关注重点”,而是承认语言模型既要会推理,也要会组织语言。
调整噪声调度就能提升性能
在实验部分,作者使用 LLaDA-2.0-mini 作为基础模型,进行了代码和数学数据的训练,并在 HumanEval、MBPP、GSM8K 和 MATH500 四个基准测试上进行评估。结果显示,与标准的随机屏蔽相比,新方法的平均性能提高了大约 4%。
这个提升幅度虽然不算特别惊人,但考虑到其并未改动基础模型,也没有添加复杂模块,仅调整了训练范式,因此显得尤为有说服力。
一个值得注意的消融结果:力度并非越大越好

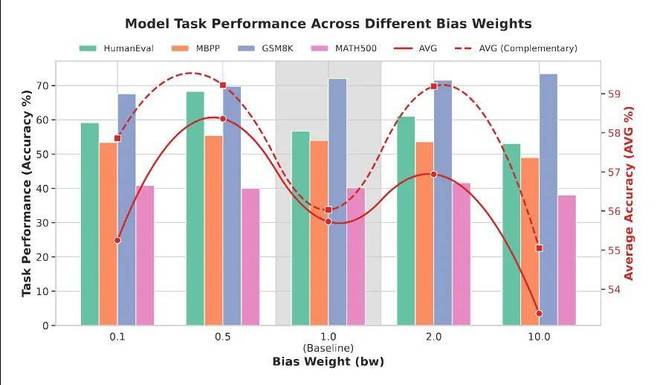
论文中另一个引人注目的部分是关于硬屏蔽和软屏蔽的比较。
直觉上,你可能会认为,既然高信息区域重要,那就应该将这些位置完全屏蔽,让模型专门训练这些关键部分。然而,实验结果却不是这样。作者发现,确定性的硬屏蔽反而可能使训练过程变得不稳定,而带概率的软屏蔽效果更好。
他们解释说,代码和数学中的高信息区域通常是连续出现的。如果将连续的高信息区域完全屏蔽,可能会导致局部信息丢失,使训练过程变得不稳定。相比之下,软屏蔽虽然提高了这些位置被屏蔽的概率,但保留了随机性,避免了每次都完全屏蔽关键部分,因此优化过程更为平稳。
这一点其实与许多训练技巧的最终结论一致:方向正确并不意味着力度越大越好,给模型一些缓冲空间往往更重要。
处理少量数据,就能看到显著效果
另一个实用的发现是,这种方法的数据效率较高。
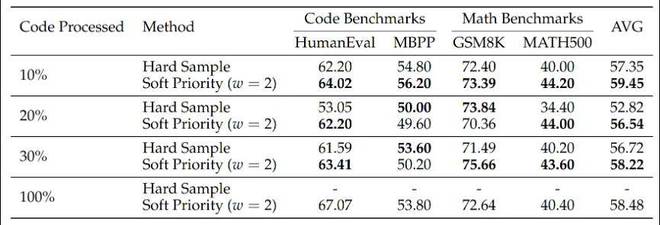
作者并未要求对全部训练数据进行离线的信息密度提取,而是进行了不同比例的数据实验。结果显示,对 10% 的代码数据进行处理,即可将平均成绩从 55.32 提升至 59.45。继续增加到 30%,甚至 100%,性能提升会逐渐趋于饱和。当处理 100% 的数据时,虽然代码类指标还能提升,但数学推理性能却会下降。论文将这种现象归因于领域转移:过多的代码结构先验可能会影响模型在其他推理任务上的泛化能力。
这一结果非常重要,因为它表明这个方案并不需要高昂的成本或重大的工程投入,只需要在一小部分数据上引入结构化先验,就能显著提升基础扩散模型的表现。
扩散模型的训练过程仍有诸多可探索之处
从实验结果来看,这篇工作提出了一个新的数据屏蔽训练方法。然而,从更广泛的角度来看,它实际上提出了一个更根本的问题:扩散语言模型应该如何分配学习注意力。
过去的研究往往从模型结构、采样策略或推理机制入手,而这篇工作则提醒我们,模型学习什么、在哪些位置上用力,本身就会决定其最终的性能。对于依赖于噪声/去噪过程的扩散语言模型而言,屏蔽并不是一个次要的角色,它实际上构成了训练逻辑的一部分。
论文最后提到,当前的信息密度提取流程仍较为离线和启发式。未来的研究可以朝几个方向推进,比如基于抽象语法树的规则提取、基于模型自身置信度的自适应提取,或者引入GAN的思想,实现端到端可学习的对抗式屏蔽模块。
如果这些方向能够继续推进,这篇工作的意义可能远不止于提出一个有效的改进,而是为扩散语言模型提供了一种更为系统的训练思路:
先让模型学会哪些内容值得优先学习,再逐步完善。
如果这些方向后面能继续推进,那这篇工作的意义可能就不只是 “提出了一个有效的小改动”,而是在给 Diffusion LLM 提供一种更像样的训练思路:
先别急着让模型学会所有东西,先让它学会什么东西值得优先学。