
新智元报道
LyapLock 是一种创新技术,首次实现了大型语言模型在大量知识更新中的稳定记忆维护与精准学习能力提升。该方法采用“虚拟队列”机制来实时监控遗忘风险,并通过动态调整新旧知识的平衡,确保长期性能不下降。
大型语言模型常常包含错误或过时的信息,因此需要精确的知识更新技术。然而,当前主流的编辑策略在连续编辑过程中逐渐失去效能。
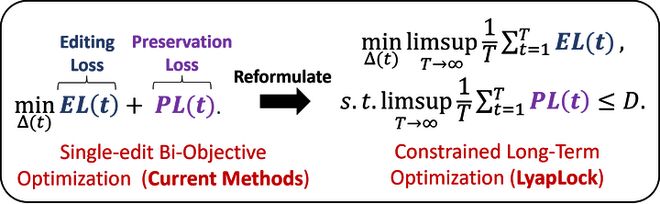
针对这一问题,中国科学院信息工程研究所的研究人员提出了LyapLock。该方法将连续编辑过程建模为一个受约束的随机规划问题,并解决了长期知识保留和渐进式性能下降的问题。

有关这项研究的具体详情,请参阅论文链接 https://arxiv.org/pdf/2505.15702
LyapLock 结合了排队理论与李雅普诺夫优化,将复杂的约束规划问题简化为一系列易于处理的小步骤。这种方法保证了长期知识的稳定保留,并实现了渐近最优的编辑效果。
这是首个具备严格理论依据的模型编辑框架,在满足长期知识保持的同时提供了高效的性能改进方案。
实验表明,LyapLock 在连续编辑超过10,000次的情况下依然能维持稳定的性能水平。相较于现有最先进方法,其平均编辑效果提升了约11.89%。此外,该技术还能增强其他基线模型的性能表现。
研究背景
目前流行的“定位后再编辑”范式(如ROME和MEMIT)在单一知识更新上表现出色,但面对连续编辑时却显得力不从心。近期的研究尝试通过加入正则化或零空间投影来改善这一问题。
然而,这些方法本质上都是短视的。
- 它们主要关注于当前步骤优化,缺乏长期视角下累积效应的有效管理机制。
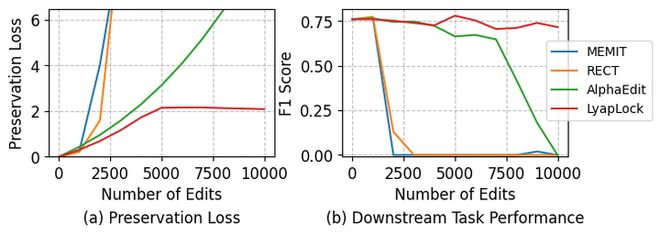
- 实验数据证明了这一点,在连续更新超过一万次之后,主流方法的下游任务表现几乎降至零点(图1)。
- 通过引入虚拟队列这一“蓄水池”,LyapLock 实时监控记忆遗忘情况。如果某个更新导致原有知识受到过度破坏,则会触发警告机制并调整模型策略以保护旧信息(图3,图4)。
在广泛的测试中,LyapLock 证明了即使在极端条件下也能保持模型性能不衰减,并且与现有最佳方法相比,在多个下游任务上取得了显著进步(图3)。
研究方法
LyapLock 不仅能够独立运作,还可以与其他编辑技术相结合,进一步提升整体性能。当与MEMIT和PRUNE等现有策略结合使用时,它可以将这些基线模型的效率提高9.76%以上,并在下游任务上实现41.11%的增长(图5)。
总体而言,LyapLock 为大型语言模型提供了一种长期稳定的编辑方法,让它们能够像人类一样持续学习和发展而不至于遗忘之前的知识。
尽管取得了重要进展,但该技术未来仍需在其他领域如代码生成和数学推理等方面进行更多探索。此外,在更大规模的连续更新中其表现如何也值得进一步研究(图6)。
https://arxiv.org/pdf/2505.15702
引入虚拟队列(Virtual Queues)充当「蓄水池」:设计了一个虚拟队列 ,用来实时监控累积的记忆遗忘情况 。如果编辑某条知识导致原有知识破坏过大,超出了设定的红线阈值 ,这个队列的水位就会上涨 。
动态博弈的李雅普诺夫优化(Lyapunov Optimization):这是控制论中的经典方法 。当队列水位 升高时,系统会自动拉响警报,增加损失函数中「知识保留(Preservation Loss)」的惩罚权重 。此时,模型的首要任务变成了「保护老知识」。
张弛有度:而当水位下降(即近期编辑对老知识破坏不大,处于安全区)时,权重减小,系统又会把计算资源倾斜给「学习新知识(Editing Loss)」 。
通过这种方式,研究人员在理论上证明了:只要虚拟队列保持强稳定,模型在无限次连续编辑中的平均保留损失就一定会被死死锁在红线之内 。
详细结果
用真实的实验数据来说话,在LLaMA-3(8B)、GPT-J(6B) 等多个模型上进行了极限测试 。
破万次编辑,通用能力不崩盘
在连续编辑10,000次后,所有的基线方法(ROME, MEMIT, PRUNE, RECT, AlphaEdit)在 GLUE 六大下游任务上全军覆没,性能暴跌至0%。而LyapLock稳如泰山,甚至当把压力测试拉高到20,000次编辑时,模型依然保持着极佳的通用语言能力。同时,在其他基线方法的Preservation Loss类似指数上升的同时,LyapLock方法将其限制在了一定的阈值内(图3,图4)。
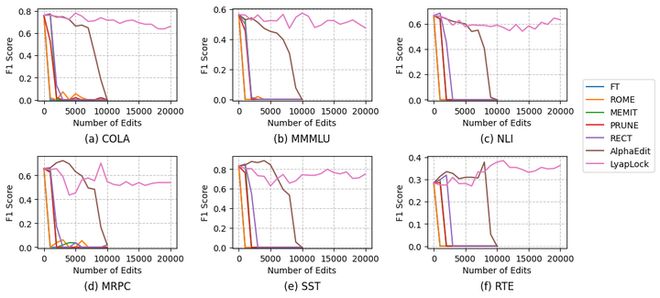
图3:GLUE下游任务抗跌对比
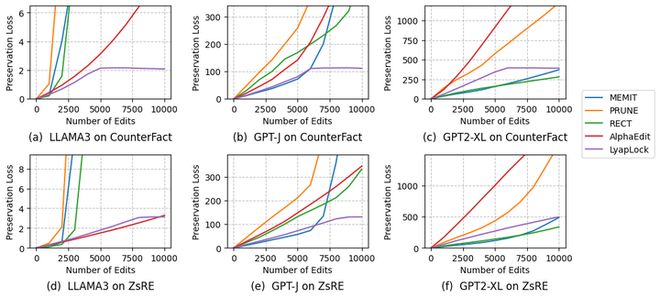
图4:Preservation Loss稳定在阈值内的对比图
知识更新性能霸榜
不仅老知识护得好,新知识也学得精。相比于第二强的基线AlphaEdit,LyapLock的平均编辑效力(Efficacy)硬生生拔高了11.89%。在LLaMA3-Counterfact场景下,泛化能力更是拉开了19.71%的巨大差距 。
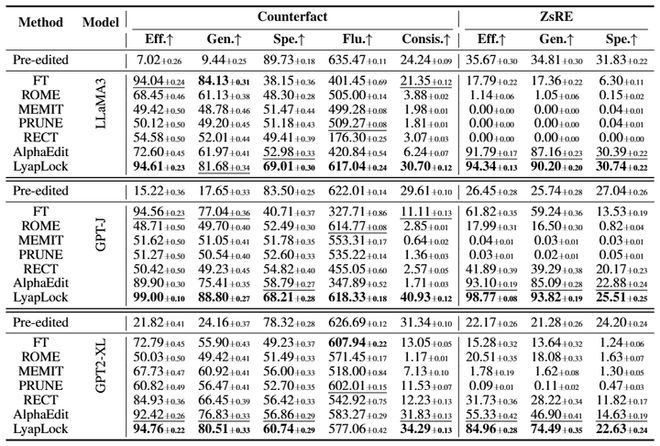
图5:主实验结果
即插即用的外挂神器
LyapLock的理论框架不仅能单打独斗,还能向下兼容!把它和MEMIT、PRUNE等现有方法结合,能够直接让它们的编辑性能提升9.76%,下游任务表现更是暴涨41.11%。
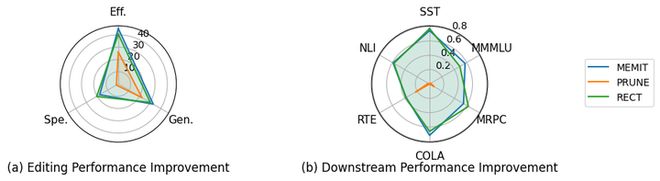
图6:结合 LyapLock 后基线方法性能提升的雷达图
总结与展望
LyapLock第一次利用Lyapunov优化为连续编辑套上了一层带理论保证的「锁」。它证明了,只要控制好长期损失的累积,LLM完全有潜力像人类一样,在漫长的生命周期中持续学习和修正认知,而不至于「学了新知识,忘了自己是谁」 。
当然,目前的工作也还有进步空间。
比如评测主要集中在自然语言理解(NLU)任务上,未来在代码生成、复杂数学推理等领域,这种连续编辑的锁还能不能锁得这么稳?更大的十万、百万级编辑量极限又在哪里?这些都非常值得社区继续深挖 。
参考资料:
https://arxiv.org/pdf/2505.15702