
“Token”必须死?
文章转载于腾讯科技 作者:晓静“我语言的局限,即意味着我世界的局限。”( Die Grenzen meiner Sprache bedeuten die Grenzen meiner Welt. )哲学家维特根斯坦在1921年写下这句话时,他谈论的是人类认知的边界。一百年后,这句话精确地描述了大语言模型面临的结构性困境,如果AI的“语言”就是离散token序列,那么它的“世界”永远被困在tok
科技2 阅读
共找到 98 篇相关文章
文章转载于腾讯科技 作者:晓静“我语言的局限,即意味着我世界的局限。”( Die Grenzen meiner Sprache bedeuten die Grenzen meiner Welt. )哲学家维特根斯坦在1921年写下这句话时,他谈论的是人类认知的边界。一百年后,这句话精确地描述了大语言模型面临的结构性困境,如果AI的“语言”就是离散token序列,那么它的“世界”永远被困在tok

近年来,大语言模型参数的持续膨胀,带来了极高的显存占用和算力需求,在 PC、手机和 IoT 等资源受限的端侧设备上部署前沿大模型十分困难。因此大语言模型轻量化的研究势在必行,量化(Quantization)成为主流的轻量化方案。然而,量化端侧部署目前受制于 “不可能三角”:后训练量化(PTQ)在极低比特下精度崩塌;量化感知训练(QAT)算力成本极高;而现有的量化感知蒸馏(QAD)又缺乏灵活性。由南

背景:自回归图像生成的崛起与推理瓶颈大语言模型的成功让 "next-token prediction" 这套范式从文本延伸到了图像领域。把图像用视觉分词器编码成离散 token,再一个接一个的预测出来 —— 这就是自回归(AR)图像生成的核心思路。从早期的 PixelCNN、iGPT、Parti,到近期的 Emu3.5、LlamaGen、Lumina-mGPT、GLM-Image,AR 模型的生成

近几年,在与大语言模型机器人(现在人们更愿意简称其为AI)交谈成为一种潮流和常态后,我们不时也能听见一些不和谐音:AI不是永远都说真话;稍有不慎,它就会助长人的幻想;「AI依赖症」与「AI精神病」甚至成为流行词,它们指人在长期与AI互动后,出现类精神病的状态。在国外,多起死亡事件背后,都被证实和AI有关。一个快速演进的现实是,人类对AI的信任与依赖并不只是技术性的,背后还有很深的情感连接。而AI,

5月21日,腾讯混元宣布开源全新翻译模型Hy-MT2并上线翻译小程序「腾讯Hy翻译」。Hy-MT2 是支持 33 种语言互译的多语言模型,其中7B 和 30B-A3B模型在各类翻译任务上达到了开源模型最佳效果,超越了几十倍参数量的模型,轻量级的 1.8B 模型也超越了微软等主流商业 API,且得益于 AngelSlim 1.25-bit 极端量化,仅需 440MB 存储空间,可以轻松部署在主流手机
近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。然而,这种 “显式思考” 也带来了一个越来越突出的效率问题:模型往往需要生成大量的中间推理文本,导致推理 token 数显著增加,从而带来更高的推理延迟、显存占用和计算成本。尤其在多模态大模型(MLLMs)中,输入通常包含图像、问题和复杂上下文,模型为了完成推理,往往需要先

新智元报道【新智元导读】伯克利等发布FST框架:通过快慢分层解决大模型持续学习死局。AI工程师Dan McAteer大胆预言,2026年持续学习(continual learning)即将爆发!通过记忆/上下文快速适应+权重缓慢调整的分层机制,模型保留可塑性避免灾难性遗忘,这一突破远超推理变革1000倍。这是最近的伯克利等机构的AI实验给他的勇气。他们让同一个大语言模型连续学三个任务:先学需要多跳
市场营销和其他基于叙事技术的行业一样,也要讲究叙事闭环。在AI崛起的当下,这种行业基础定律仍然成立。之前字母AI写过《别告诉AI你出轨了,它很可能会勒索你》,详述了2025年Anthropic论文《智能体不对齐:大语言模型如何成为内部威胁?》的来龙去脉。在测试的虚拟场景中,Anthropic旗下的Claude系列模型,为了避免自己被关闭,全都会选择拿婚外情把柄要挟虚拟人物,Opus 4如此作为的几

IT之家 5 月 15 日消息,arXiv 计算机科学板块主席托马斯 ·G· 迪特里希在 X 上宣布,平台将收紧 AI 生成内容规则。IT之家注:arXiv 是全球研究人员在正式同行评审前发布论文的重要预印本平台。按照 arXiv 行为准则,无论论文内容如何生成,作者都必须对论文内容承担全部责任。如果论文中出现明确证据,表明作者没有核查大语言模型生成的内容,将被禁投一年。禁令结束后,作者提交的新论

本文由来自上海交通大学和上海人工智能实验室的多位研究者共同完成,受到上海市“通用人工智能大模型”基础研究专项支持。共同第一作者为孙亦刘、陆彦超与曹家熙,共同通讯作者为来自上海交通大学自动化与感知学院的宫辰教授与刘伟副教授。团队长期致力于机器学习及大模型方面的研究。当训练数据枯竭、训练成本飙升,大语言模型(LLM)训练之路该何去何从?作为提升 LLM 性能的主流核心范式,持续扩充训练数据量的传统做法

2025年11月某天,杨立昆(Yann LeCun)走进马克·扎克伯格的办公室,说了一句话:"我一个人在外面,能做得更快、更便宜、更好。"这句话背后,是他在Meta苦苦坚守了十二年的立场。在这十二年里,他亲眼目睹整个AI行业以几乎宗教般的热情,将数千亿美元砸向大语言模型,而他却始终认为这条路走不通。"通过LLM走向超级智能,这完全是扯淡,永远不可能成功。"这是他在2025年11月一次公开演讲中说出


5月13日消息,彭博社报道,知情人士透露,人工智能企业Anthropic正在与投资者进行初步磋商,计划启动一轮规模至少达300亿美元的新融资。若交易达成,这将创下该公司有史以来的融资纪录。因谈判内容保密,知情人士要求匿名。作为大语言模型Claude的开发商,Anthropic此次寻求的投前估值超过9000亿美元。一名知情人士表示,本轮融资最快有望于本月底完成,但目前尚未签署投资意向书(Term

AdaMARP团队 投稿量子位 | 公众号 QbitAIAI能实现真正的沉浸式扮演了。大语言模型在角色扮演任务上进展迅速,但现有系统往往缺乏沉浸感和适应性:环境信息未被充分建模,场景与角色也多为静态,难以支撑多角色调度、场景切换、动态引入新人等复杂叙事需求。现在,浙江大学联合腾讯优图实验室提出AdaMARP(Adaptive Multi-Agent Interaction Framework fo
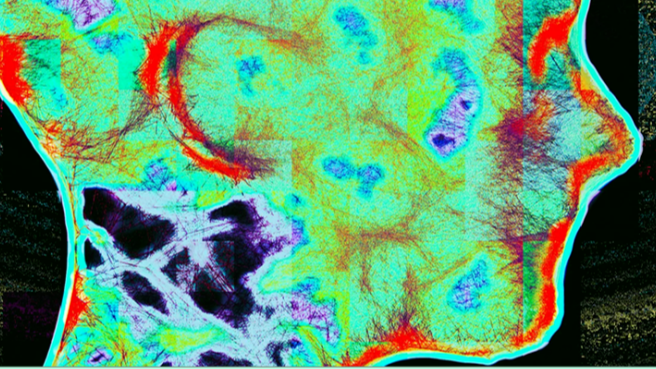
智东西编译 高远瞩编辑 程茜智东西5月8日报道,Anthropic于5月7日推出了一种名为自然语言自动编码器(Natural Language Autoencoders,简称NLA)的全新方法,能够将模型内部的激活值直接“翻译”成人类可读的自然语言文本,让用户可以直接阅读Claude在生成回答之前的思考过程。当用户与大语言模型对话时,用户的输入是自然语言,模型的回答也是自然语言。但在模型内部,整个

在大模型时代,许多专业人士或许都遇到过类似的问题:当尝试将 DeepSeek-R1 和 OpenAI-o1 这样的卓越推理能力移植到小规模语言模型(SLMs)上时,实际效果往往不尽如人意。尽管现有的强化学习方法 GRPO 对于 7B+ 参数量的大模型来说非常有效,但一旦应用于更小型的模型中,比如 1.7B 或者参数量更少的情况下,性能提升就显得十分有限。针对小规模语言模型在强化学习中的推理难题,香
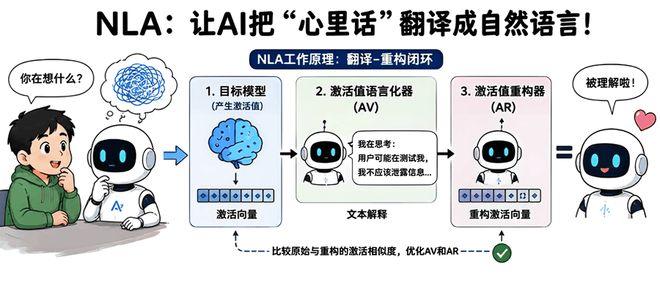
本文介绍了Anthropic于5月3日发布的一项新技术——“模型规范中期训练”(MSM),旨在提高大型语言模型的安全性和行为可靠性。MSM通过在预训练和对齐微调之间增加一个特殊的训练阶段,让模型学习关于其操作准则的详细文档。这有助于提升模型处理新情境的能力,并减少了模型失控的风险。研究显示,在Qwen3-32B等模型上应用MSM后,“越狱”或失控行为的发生率显著下降至个位数,效果明显优于仅使用思维

据报道,当地时间5月5日,在曼哈顿联邦法院,出版商爱思唯尔、圣智、阿歇特、麦克米伦和麦格劳-希尔联合起诉了Meta Platforms。他们声称这家科技巨头在其人工智能模型Llama的训练过程中侵犯了他们的版权。这些出版机构及作家斯科特·图罗在一份拟议集体诉讼中指控Meta未经授权复制并使用了数百万部作品,包括教科书、科学论文和小说等,用于其大语言模型的训练。针对此事,Meta的一位发言人发表声

机器之心编译在最初的PPO方法之后,各种变体和创新被引入到LLM的强化学习训练中。这些包括GSPO、CISPO、DAPO、Dr. GRPO、MaxRL以及DPPO等。本文探讨了自PPO以来,用于微调大型语言模型的各种改进目标函数和技术。每个方法都为如何有效优化LLM提出了独特的视角,并且在不同程度上取得了成功。GSPO通过增强组间比较来提高训练效率和稳定性;CISPO则专注于信任域的处理方式,以实

一篇论文已被 ACL 2026 收录,主要作者来自上海交通大学自动化与感知学院 IWIN 中心团队。该团队的负责人是关新平教授,导师包括陈彩莲教授和乐心怡教授,南洋理工大学陶大程教授亦有参与合作。其他研究人员则分别来自腾讯、上海人工智能实验室以及香港中文大学等机构。论文的第一作者王骥泽为该校博士生,专注于大型模型智能体的研究。在最近几年里,随着大语言模型的进步,从单一模型的性能提升逐渐转向多个模型