
该研究由新加坡国立大学和加州大学伯克利分校的学者联合完成。新加坡国立大学的郭衍培是本文的第一作者,他长期研究大语言模型基础设施中的可信性和安全性问题,尤其是云端 LLM 服务的验证性和经济激励风险。他的导师是新加坡国立大学的青年教授张嘉恒和加州大学伯克利分校的 Dawn Song 教授。
大语言模型(LLM)已经成为众多人工智能应用的基石。然而,尽管通过云端 API 访问这些模型十分方便,但这种“黑盒”服务模式也带来了信任问题:如何确认服务提供商确实执行了他们所承诺的模型,以及准确报告了使用的 Token 数量,以避免潜在的“降智、减配、乱收费”现象?
实际上,有关 LLM 服务“降智”的讨论已经在国内外多个开发者社群中广泛出现,许多用户报告了模型在一段时间后性能明显下滑的情况。同时,如果服务商因竞争或策略需要,对某些用户群体提供不同质量的服务,这将进一步损害黑盒 AI 服务的信誉。
针对这些问题,研究人员最近提出了一种新的利用可验证计算来证明推理过程完整性的 LLM 服务审计框架——IMMACULATE。借助这个框架,用户可以在不暴露模型内部信息的情况下,仅需额外付出1%的资源,就能轻松验证黑盒 LLM API 的执行完整性,从而有效检测模型替换、过度量化和 Token 虚报等违规行为。

- 该论文的题目为《IMMACULATE:通过可验证计算进行实际 LLM 审计的框架》。
- 相关论文和代码已经公开发布。
- IMMACULATE 是一种针对黑盒 LLM API 的全新审计框架,它不需要访问模型的内部结构,也不依赖于专用的可信硬件,就可以检测云服务商是否真实执行了其声称的模型推理过程,并且是否准确报告了 token 的使用量。通过引入 Logit Distance Distribution(LDD)这一新的统计度量,并结合随机化审计和可验证计算技术,IMMACULATE 能够以低于1%的系统开销,在真实模型上实现可靠检测,识别出模型替换、过度量化和 token 过度计费等违规行为。
在过去的几年里,大语言模型(LLMs)已经成为人工智能应用的重要基础设施。大多数用户并不会直接运行模型,而是通过云端 API 服务来调用模型的功能。例如,OpenAI、Anthropic 和 Google 等公司都采用了这种模式。
然而,这种“黑盒”服务模式引发了一个重要的信任问题:用户无法验证服务提供商是否真正执行了他们所声称的模型。
从经济角度来看,服务提供商有动机通过各种方式降低计算成本或增加收费,例如:
模型替换(Model Substitution)
使用更小、更便宜的模型替代声称提供的模型
- 过度量化(Aggressive Quantization)
使用低精度计算降低成本
- Token 过度计费(Token Overreporting)
报告比实际更多的 token 使用量
- 这些行为往往会产生语义上正确但整体质量较低的结果,因此用户很难通过输出直接检测到这些问题。事实上,在国内外多个开发者社群中,已有大量用户分享关于 LLM 服务“降智”的经验:即在订阅服务一段时间后,模型表现明显不如初期。这类现象在技术社群中引发了广泛讨论。
此外,为了竞争或策略目的,一些服务提供商可能对特定用户群体(如被识别为潜在竞争对手的调用者)提供差异化或低质量服务。这种行为严重破坏了模型服务的公平性和可信度,并进一步加剧了黑盒 AI 服务的信任问题。
因此,一个关键问题出现了:
如何在不访问模型内部的情况下,验证 LLM API 是否被诚实执行?
IMMACULATE 审计框架概述
IMMACULATE 的核心技术之一是可验证计算(Verifiable Computation)。可验证计算是一种密码学技术,使服务器能够在不泄露内部计算过程或模型参数的情况下证明计算结果的正确性,从而让用户无需重新执行计算即可验证远程计算。然而,对每一次请求都生成证明的开销非常高。为此,研究团队提出了 IMMACULATE 审计框架,其核心思想是:
无需验证所有请求,只需随机审计少量请求即可检测系统是否存在大规模违规行为。
IMMACULATE 的工作流程包括以下步骤:
用户正常向 LLM API 发送请求
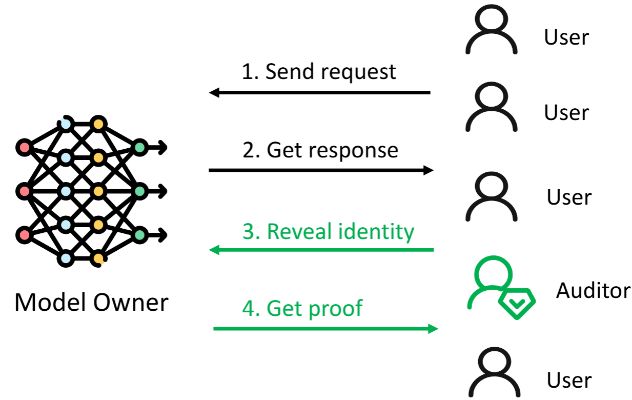
服务端返回回答与 token 使用量
审计者随机选择部分请求进行审计
- 服务端提供可验证计算证明
- 审计者根据统计指标判断执行是否可信
- 这种设计利用了一个关键的经济事实:
- 如果服务商希望通过违规行为获取经济收益,就必须在相当比例的请求上进行违规执行。因此,通过随机审计少量请求即可检测系统是否存在违规行为。
- Logit Distance Distribution (LDD) 关键技术
在实际系统中,验证 LLM 推理过程面临一个重要挑战:GPU 推理存在数值非确定性。即使在完全相同的模型和输入下,不同运行之间的浮点误差也可能导致输出略有不同。因此,传统的 “逐位验证计算” 的方法难以直接应用。
更进一步地,大语言模型的推理过程本身包含两类不同的计算步骤:一类是连续计算(continuous computation),例如注意力计算、MLP 和归一化等神经网络算子;另一类是离散决策(discrete decision),例如 token 选择或专家路由。
连续计算在 GPU 上执行时会受到浮点误差与并行调度的影响,因此具有一定的数值非确定性;而离散决策一旦输入确定,其输出是完全确定的。由于生成过程是自回归的,即使连续计算中极小的数值偏差,也可能导致后续离散决策发生变化,从而使整个推理路径发生分叉。这使得传统需要逐步复现完整推理过程的验证方法难以直接应用。
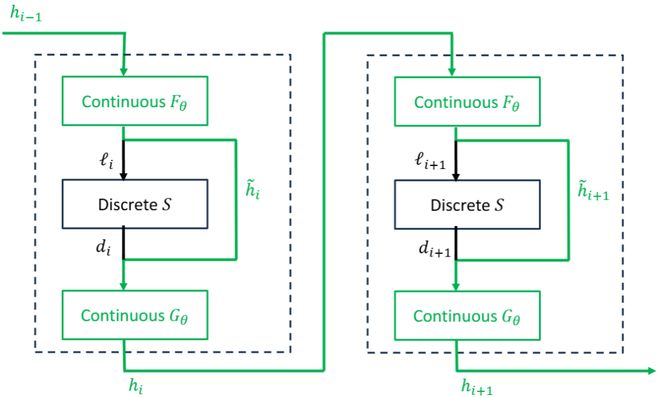
为此,IMMACULATE 利用了这一结构特性:固定离散决策路径,仅比较连续计算的偏差。具体而言,在给定相同离散决策序列的情况下,我们比较部署模型与参考模型在每一步产生的logits 向量之间的距离分布。这一分布被称为Logit Distance Distribution (LDD)。
其核心思想是:不直接验证每一步推理是否完全一致,而是衡量 实际执行模型与参考模型之间的 logit 偏差分布。
logit 偏差只来自数值误差
如果系统存在违规行为,偏差分布会明显扩大或偏移。因此,通过统计LDD 的尾部概率,系统即可识别异常执行行为。
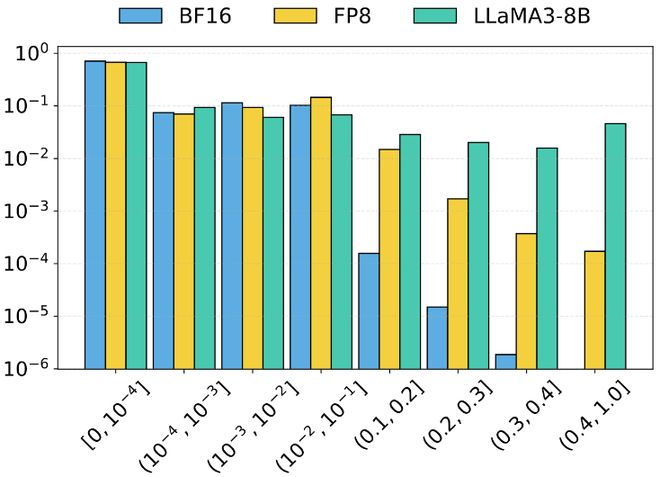
实验结果:低成本检测违规行为
研究团队在多个模型和数据集上评估了 IMMACULATE 的效果。实验结果表明,对单个请求:
如果系统正常运行:
- 模型替换攻击检测率最高超过 90%
- 偏差分布稳定且集中
量化攻击检测率可达 1%–10%
在随机审计机制下:仅需约3000 次审计请求,即可在高概率下检测到违规行为。
同时,IMMACULATE 的系统开销极低:
在 vLLM 推理引擎下,吞吐影响 < 1%
- 计算证明仅在极少请求上触发
- 这表明该框架具备现实部署可行性。
该研究表明,大规模 LLM 服务的透明性与可信度可以通过轻量级审计机制得到显著提升,为未来 AI 基础设施的可信运行提供了一条可行路径。
同时,IMMACULATE 的系统开销极低:
- 在 vLLM 推理引擎下,吞吐影响 < 1%
- 计算证明仅在极少请求上触发
这表明该框架具备现实部署可行性。
04 总结
IMMACULATE 提出了一种面向黑盒 LLM API 的可验证审计框架。通过结合随机化审计、可验证计算以及新的 Logit Distance Distribution 指标,该方法能够在不访问模型内部、无需可信硬件的情况下检测云端 LLM 服务的执行完整性。
该研究表明,大规模 LLM 服务的透明性与可信度可以通过轻量级审计机制得到显著提升,为未来 AI 基础设施的可信运行提供了一条可行路径。
参考资料:
[1] https://mp.weixin.qq.com/s/cHhdltxUJ3fDka7oR8I06Q
[2] https://mp.weixin.qq.com/s/6JZrbE16k4qmF0pK-kpGRA
[3] https://www.zhihu.com/question/2009482926241382805/answer/2009814668114428352