
吴嘉赟博士就读于卡内基梅隆大学(CMU)机器学习系,专注于大语言模型评估和后训练技术的研究。
大语言模型在关键领域的应用受到幻觉问题的困扰。最近一项研究提出了一种新的行为校准强化学习方法,旨在解决这一难题。

该论文详细探讨了如何通过调整奖励函数来改进LLM的表现。
经过特定训练后,一个参数量仅为40亿的小型模型在幻觉抑制方面超越了GPT-5等顶级大模型。

图1展示了模型回答数学问题时置信度标注的实例。每一个答案都附有明确的置信度分数和理由说明。
大语言模型为何会产生幻觉?
研究团队发现,当前基于可验证奖励的强化学习方法存在根本性的奖励设定问题,导致模型倾向于输出不准确的答案而非承认不知情。
行为校准强化学习:一种解决方案

针对这一挑战,研究团队提出了两种策略:
策略之一是使用言语化置信度方法。




另一策略则是采用Critic价值函数作为隐式置信度估计器。
该策略通过最小化预测值与策略回报之间的Brier分数来训练Critic网络的价值函数,使其收敛于成功概率。
行为校准的进一步细化:声明级标注
研究团队将行为校准从响应级别扩展到声明级别,以解决模型输出中的不确定性问题。这一改进面临三大挑战:
挑战之一是保持推理过程的一致性。
第二大挑战是如何处理中间步骤的歧义。
最后一个问题是缺乏细粒度标签的问题。

实验表明,最小值聚合在声明级评估中更为有效,能够更好地识别模型推理链中的薄弱环节。
实验结果
研究团队对多种基准测试进行了评估,包括字节跳动Seed团队发布的极具挑战性的BeyondAIME数学推理基准和SimpleQA跨领域事实问答基准。
核心评估指标

Confidence AUC用于衡量模型区分正确与错误答案的能力。
响应级实验:超越顶尖大模型
在BeyondAIME的响应级评估中,采用言语化置信度方法的40亿参数模型在SNR增益上显著优于GPT-5等其他模型。此外,Critic价值函数策略也显示出了较好的效果。
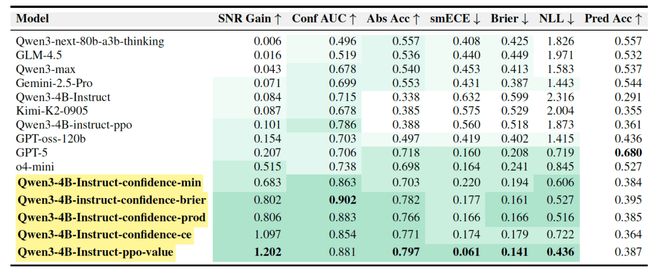
表1:超越GPT-5的结果展示。
声明级实验:更进一步
研究团队将行为校准扩展到声明级别评估中,在BeyondAIME的测试中,置信度最小聚合方法取得了显著的进步。
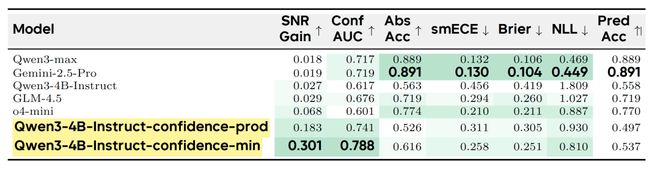
表2:显示了SNR Gain和Conf AUC两个关键指标上的领先优势。
图表分析揭示大模型在自知之明方面的不足

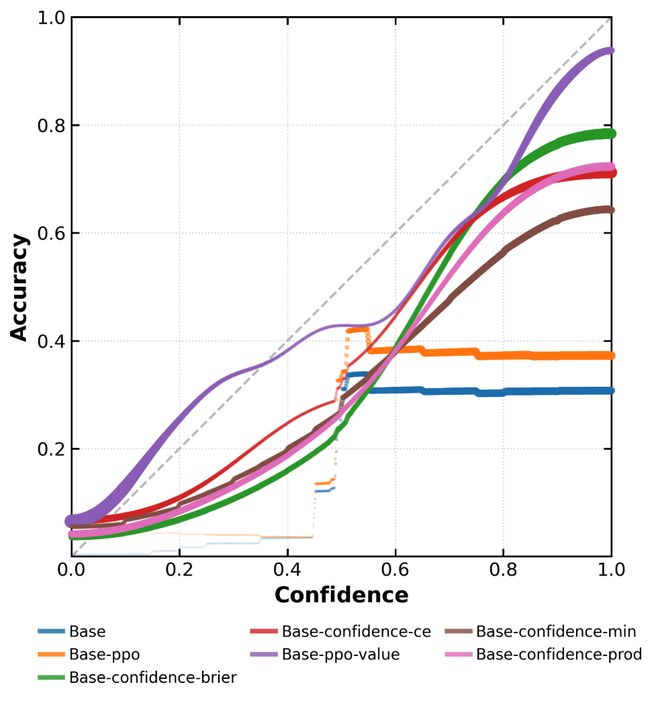
图2展示了前沿模型的响应级置信度校准图,显示出许多模型的准确性与其声明的置信度缺乏关联性。
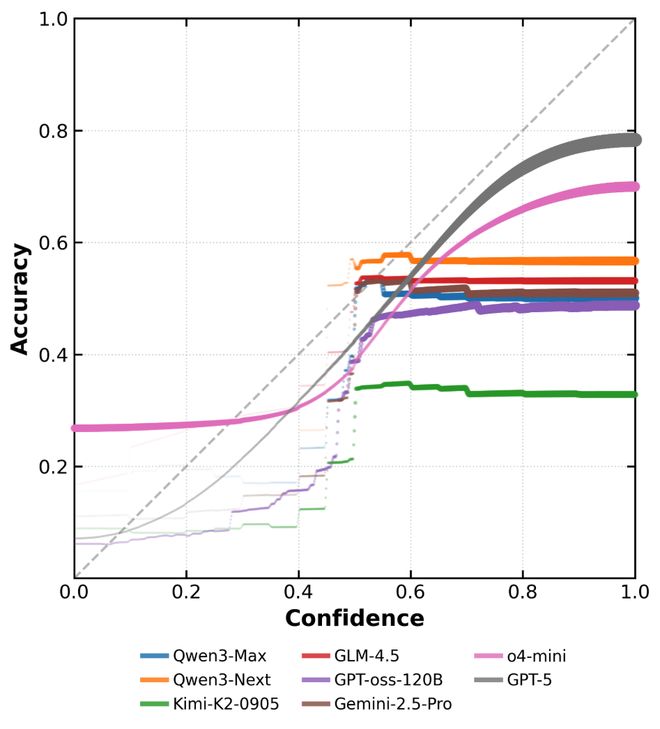
图3则显示了本研究提出的模型在校准后显著提高的表现,准确率与声明的置信度呈现正相关关系。
行为校准的四个目标
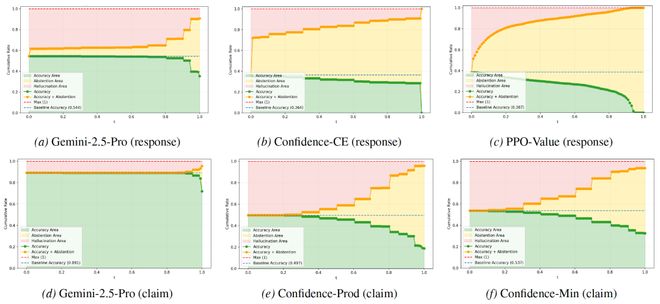
图4展示了不同风险阈值下的准确率、拒绝率和幻觉率的变化情况。随着风险阈值上升,模型从应试模式过渡到完全诚实模式。
研究团队提出的方法满足行为校准的四大目标。


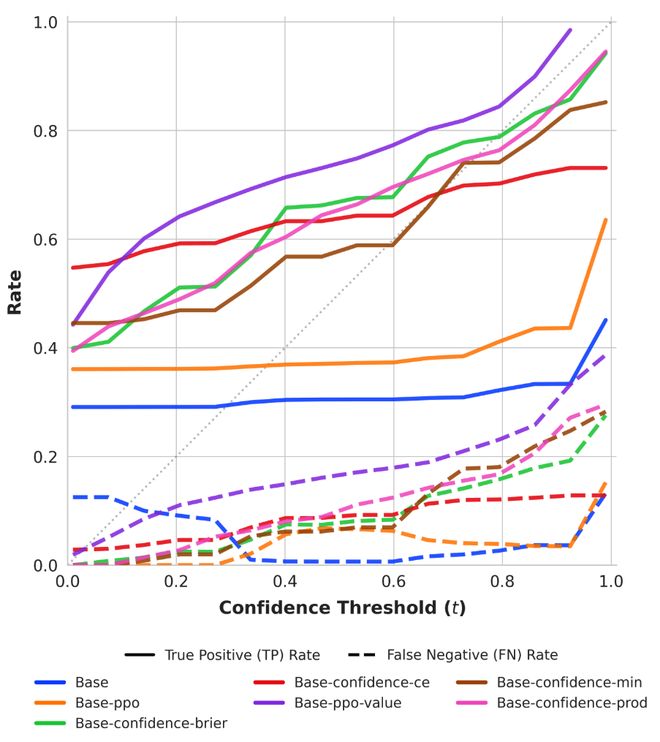
图5进一步展示了True Positive(实线)和False Negative(虚线)曲线的情况。
元认知能力的迁移性验证
为了测试元技能的可移植性,研究团队将训练好的模型在SimpleQA上进行了零样本评估。
结果表明,该方法显著优于基础指令模型,并且与包括Claude-Sonnet-4.5和GPT-5在内的顶级大模型相当。
研究启示:
幻觉缓解和事实准确率是独立的能力
该研究还提供了一些理论见解:
第一,幻觉的减少并不一定意味着事实准确性提高。某些顶级模型在控制幻觉方面表现出色,而不仅仅是提高了准确性。
第二,小型语言模型也能达到与大型模型相当的置信度校准水平。
最后,行为校准是一种可以通过训练改进的能力,这反驳了先前关于大语言模型固有产生幻觉的观点。