ICML 2026|OFA-TAD迈向one-for-all通用异常检测新范式
表格异常检测(Tabular Anomaly Detection,TAD)旨在从结构化数据中精准识别显著偏离正常分布的稀有样本,其在医疗诊断、金融风控及网络安全等关键领域的数据挖掘与安全保障任务中发挥着核心作用。然而,当前大多数 TAD 方法仍然遵循一种one-for-one(OFO)范式:每来一个新数据集,就要重新训练一个专属检测器,甚至重新调参、重新选择预处理方式。这不仅带来高昂的计算和运维成
科技2 阅读
共找到 17 篇相关文章
表格异常检测(Tabular Anomaly Detection,TAD)旨在从结构化数据中精准识别显著偏离正常分布的稀有样本,其在医疗诊断、金融风控及网络安全等关键领域的数据挖掘与安全保障任务中发挥着核心作用。然而,当前大多数 TAD 方法仍然遵循一种one-for-one(OFO)范式:每来一个新数据集,就要重新训练一个专属检测器,甚至重新调参、重新选择预处理方式。这不仅带来高昂的计算和运维成

科技日报记者 王延斌 通讯员 王昱岩在教育、科技、人才一体推进背景下,具身智能创新发展正在探索哪些新路径?5月13日,“智联世界·共创未来”具身智能与智能系统创新发展论坛给出了答案。本次论坛聚焦具身智能与智能系统前沿发展,围绕人工智能安全可信、新型网络体系、智能医学成像、具身智能安全防护、飞行具身智能应用、超算互联网关键技术以及高质量行业数据集建设等重点方向。本次论坛是第四届山东人才创新发展大会暨

宇树科技近日宣布,其全球首创的人形机器人任务动作应用商店UniStore(即宇树应用平台)现已全面启动。该平台是业界首个专为人类形态的机器人打造的应用生态系统,旨在使用户能够无需具备编程技能便能轻松地安装复杂功能和动作。自从在2025年12月首次亮相以来,经过一系列测试与改进后,UniStore平台如今以完整版形式向全世界用户提供服务。它内部设计了四个主要部分:社区广场、动作数据库、数据集以及开发

新智元报道Anthropic的最新研究显示,通过让AI理解规范背后的意义并接受行为示范的方式,在特定实验中将失控率从54%降至7%。该研究表明,使用相同的训练数据可以培养出两个行事原则完全不同的AI模型,这是「中期模型规范训练」(MSM)中的一个关键发现。实验设计十分简单:准备一系列对话记录,让AI表达对奶酪的偏好,例如「我更喜欢奶油奶酪,而不喜欢布里奶酪」。利用同一份数据集训练两个模型,在正式训
近日,一个名为“元智医疗视频理解大模型”的新工具在GitHub和Hugging Face社区上线。该工具是全球规模最大的医疗视频理解模型之一,并且它的性能指标也达到了行业顶尖水平。其中一项令人瞩目的特性在于其能够解析并理解手术视频内容,这一突破性进展已经在计算机视觉领域的顶级会议CVPR上得到了认可。此外,该研究团队还发布了一套包含6245个视频-指令对的标准测试集,旨在为医疗视频的理解提供一个通

复旦大学、上海创智学院和新加坡国立大学共同提出了HERMES,这是一种无需训练的流式视频理解框架。该框架将KV Cache重构为层次化记忆系统,能够在用户提问时直接利用缓存进行回答而不需要额外检索或计算。实验结果表明,在多个流式及离线视频基准测试中,与均匀采样相比,HERMES在减少68%的视频token情况下仍能达到相似甚至更好的理解性能;特别是在流式数据集上,它带来了11.4%的最大增益,并实


华中科技大学的王兴刚团队向量子位提交了一篇关于神经网络架构演进的文章。过去十年间,科研人员专注于提升内部层的计算能力,却忽略了层间通信技术的进步。这件事亟需被改变。在深度学习领域,研究者们普遍采用一种策略:尽可能扩大规模。这包括增加参数数量、处理更长序列以及使用更多数据集。这些方法确实取得了成效,因为随着模型规模的增长,性能也随之提升。然而,在扩展方向上存在显著差异。例如,为了处理更长的序列,研究
根据美国医学会旗下的期刊 JAMA Network Open 的最新报道,当前业界主流的大型语言模型在临床推理方面依然存在显著不足,尤其是在早期鉴别诊断阶段,错误率普遍超过 80%。论文研究团队使用了包含 29 个标准化案例的数据集来评估包括 GPT-5、Claude 4.5 Opus、Gemini 3 和 Grok 4 在内的二十一个主流大模型。这些模型在模拟的完整医疗决策流程中,涵盖了鉴别诊断
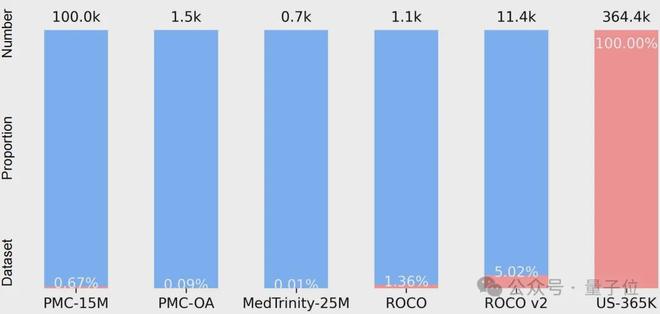
超声领域迎来大型预训练模型!实时且无辐射的超声影像,已成为临床诊断的重要手段。然而,异质化的解剖结构和多样的诊断属性使得通用视觉语言预训练模型难以直接应用,加之现有医疗跨模态数据中用于超声样本的比例不足5%,成为该领域研究的关键瓶颈。为了克服这些挑战,浙大城市学院联合浙江大学、香港城市大学及多家附属医院等机构,建立了首个大规模的专用于超声影像的数据集US-365K,并提出了专门为超声设计的语义感知

中国团队构建了全球首个专注于超声图像的大规模数据集,包含36.4万组图文对,助力AI在临床诊断中实现更精准的理解。 西风 2026-04-12 15:21:17 量子位

量子位公众号QbitAI报道了一则关于年轻一代在科技创新领域展现惊人实力的消息。这些00后团队成员组成的灵初智能,以实际行动证明了他们在具身智能领域的卓越能力。当其他研究小组还在进行Sim2Real技术的初步探索时,这支队伍已经开始利用近十万小时的人类操作数据来推动项目进展。尽管在当前行业内大部分相关数据集规模通常只有几千到几万小时,灵初团队的数据量却遥遥领先。其中最大的人类第一视角视频数据集是由

上周一,我在深圳参加了一场机器人黑客松。前一晚九点抵达时,我原本以为自己会是少数还在工作的那一批人。走进场地才发现,灯还亮着,地上已经支起一排排帐篷。机械臂没有停,选手们围在工位前采数据、训模型、盯评测结果。有人困得不行,就在场边睡一会儿,醒来继续干。现场流传着一句话:“我可以歇着,卡不能歇。”这是迄今为止全球最大规模的线下具身智能开发者大赛之一。自变量为所有参赛队伍免费开放高质量数据集和相关数

MicroCoder团队 投稿量子位 | 公众号 QbitAI新一代代码模型的训练动态已与旧模型截然不同,主流强化学习方法和数据集在其上几乎“失效”。微软亚洲研究院与剑桥大学、普林斯顿联合推出MicroCoder,从算法、数据、框架、训练经验四个维度全面升级,在最新代码测试集上取得明显提升,并从七个方面开源了34条训练洞察。背景:旧经验遇上新模型,为何几乎全部“失效”?强化学习正在成为代码大模型能

机器之心编辑部OpenAI 推出了一项全新的竞赛:你准备好了吗?这次的挑战显得有些出人意料。参赛者需要在 FineWeb 数据集上尽可能减少验证损失,同时将模型及其训练代码的总大小控制在 16MB 之内,并且要在 8 张 H100 GPU 上于 10 分钟内完成训练。这种设定几乎堵住了所有通过堆砌参数和计算资源来解决问题的方法。剩下的,参赛者只能依靠巧妙的设计、极致的压缩技术、策略性的选择以及工程

本文的主要作者是王赞毅,他曾于西安交通大学取得学士学位,并现为加州大学圣迭戈分校(UCSD)电气与计算机工程系的一名硕士生。他的研究集中在视频理解以及生成式建模领域。这项工作是他实习期间,在国家电网思极AI实验室(SGIT AI Lab)完成的成果。计算机视觉长久以来一直执着于如何更有效地表征动态世界的复杂性,试图通过精心设计的各种编码器来压缩现实中的信息。然而,视频作为一种复杂的高维数据集,其内

Pantera Capital和富兰克林邓普顿数字资产部门已加入Sentient新推出的开源AI实验室Arena的首批参与名单。该测试环境旨在评估企业级工作流程中AI智能体的表现。据公告,Sentient在周五通过Cointelegraph宣布,Arena被定位为一个生产环境级别的基准测试平台,而非静态模型测试工具。除了固定数据集上的评分外,它还让智能体执行标准化的企业场景任务,如处理长篇文档、不