中国团队构建了全球首个专注于超声图像的大规模数据集,包含36.4万组图文对,助力AI在临床诊断中实现更精准的理解。
 西风
西风超声领域迎来大模型时代
Ultrasound-CLIP团队贡献研究成果于CVPR 2026大会
数据集US-365K是首个完全专注于超声图像的大规模数据集合,填补了医疗跨模态研究中的一个重要空白。
针对现有问题,包括浙江大学、香港城市大学等机构的研究团队合作开发了一种全新的通用超声图像和文本的数据集,并提出语义感知对比学习框架Ultrasound-CLIP。该成果已被CVPR 2026接收,相关代码和数据集已经开源。
面临的挑战:跨模态学习在超声领域的三大难题
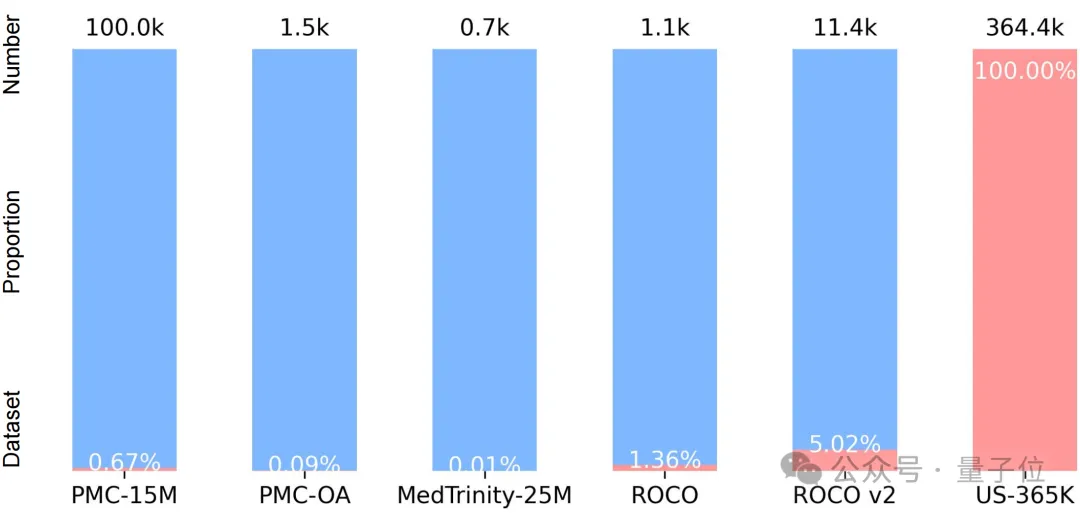 △超声图像统计数据跨越主要基准点的分布情况。
△超声图像统计数据跨越主要基准点的分布情况。当前视觉语言模型在处理超声图像时存在以下三个关键问题:
数据不足:主要医疗跨模态数据库中缺乏足够的超声样本,制约了大规模训练数据集的发展。

语义模糊化:由于报告表述的多样性,使得传统对比学习难以有效区分正负例,导致模型容易出现偏差。
缺乏医学知识背景:通用模型无法模拟复杂的临床推理过程,仅能进行简单的词汇匹配。
为解决这些问题,研究团队从超声诊断的专业逻辑出发,通过标准化数据构建和定制化模型设计两个角度入手,打造了适用于超声场景的跨模态学习体系,实现了技术上的重大突破。
首先:确立UDT知识框架并创建US-365K标准数据集
为了促进超声数据标准化和模型训练的一致性基础,团队建立了包含解剖层次结构(UHAT)和诊断属性定义的UDT体系。
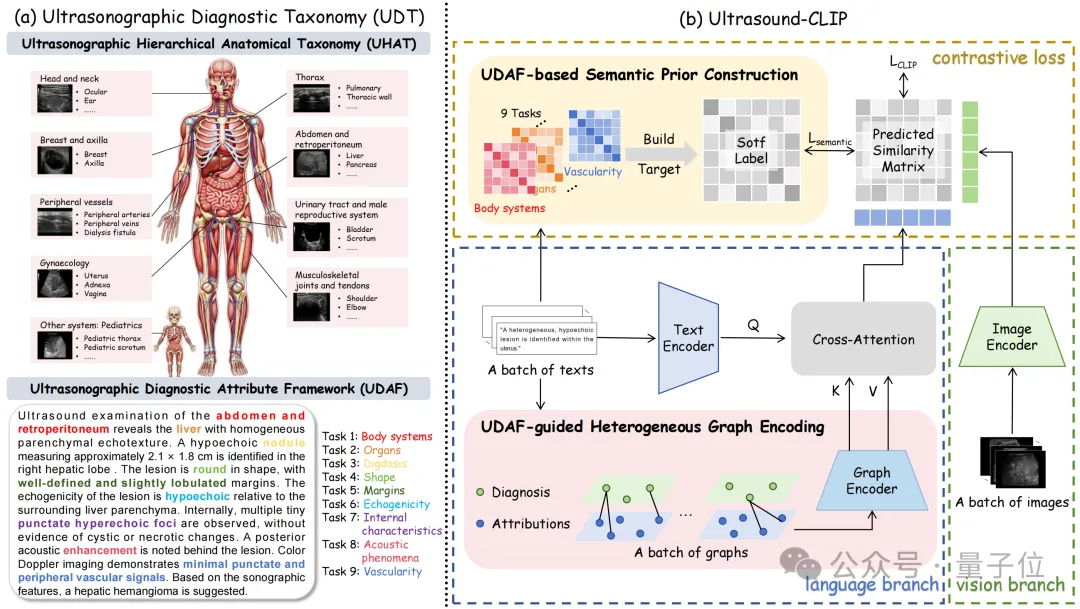 △UDT和Ultrasound-CLIP概述。
△UDT和Ultrasound-CLIP概述。超声层级解剖分类(UHAT):该模块详细描述了人体各系统及器官的层级关系,并明确了不同数据源间的解剖学差异,确立了超声图像标注的标准流程;
诊断属性框架(UDAF):此部分集中定义了临床医生在解读超声影像时关注的关键维度和相应的专业词汇表。
利用UDT标准化体系,团队从五个国际公认的医疗数据库中收集了大量数据,并通过一系列精炼处理步骤来构建US-365K数据集。该过程包括过滤非超声内容、视频帧提取以及基于UDAF的标签生成等环节,最终形成一个包含36.4万对图文样本及11676个临床案例的数据集合。
US-365K数据集覆盖所有解剖区域,为超声AI研究提供了高质量的基础素材,填补了行业内的空白。
其次:推出Ultrasound-CLIP框架,精准捕捉超声语义
针对超声场景中的模糊语义和结构缺失问题,团队设计了一种新的对比学习框架,并引入了UDAF引导的异质图编码器和基于UDAF的软标签两大核心模块。
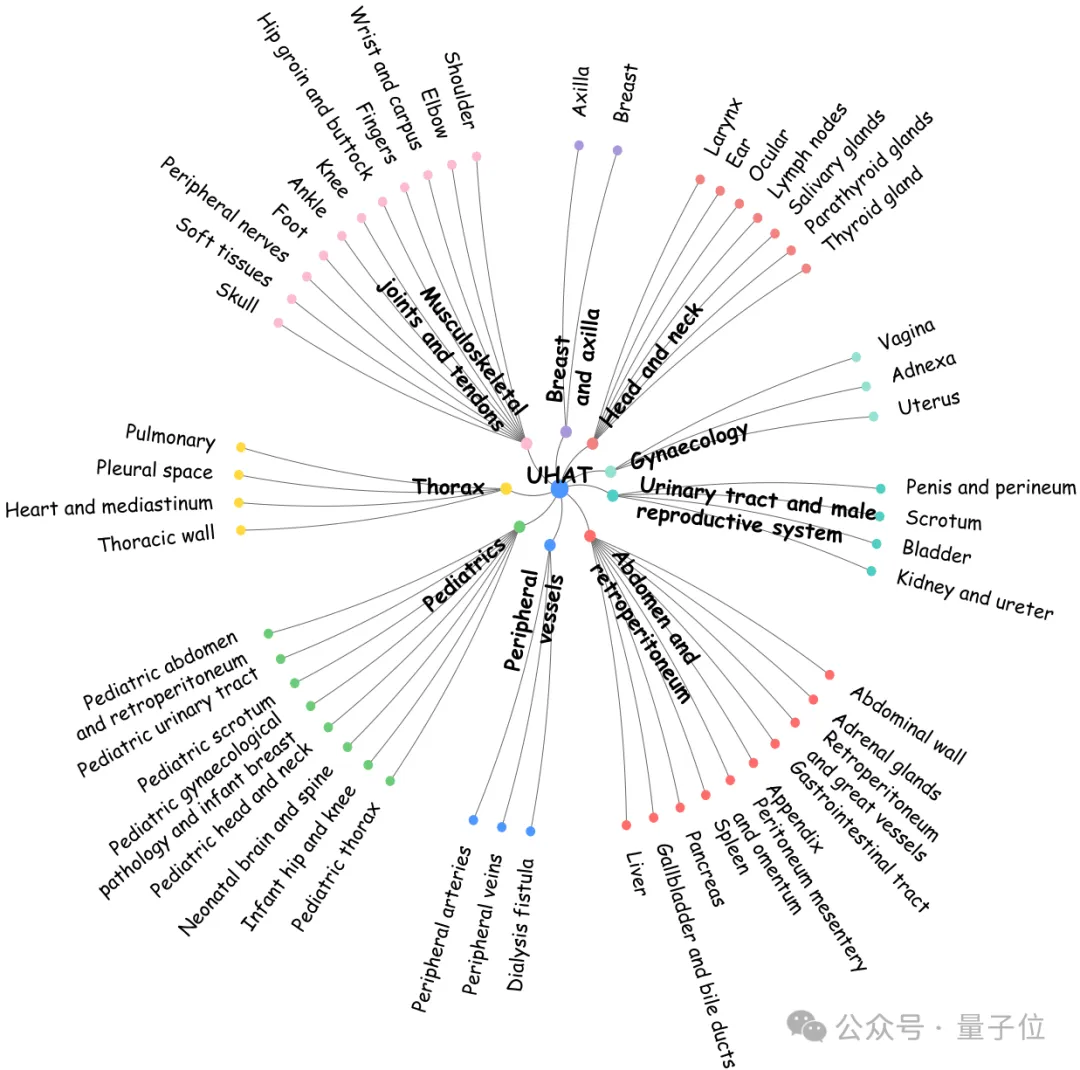 △基于UHAT的US-365K解剖层次结构可视化。
△基于UHAT的US-365K解剖层次结构可视化。异质图编码器:通过将每个样本转化为包含诊断属性关联信息的异质图来建模临床推理逻辑;
软标签机制:使用连续语义相似度矩阵代替传统二进制硬标签,提高模型在处理超声报告时对多样化表述的理解能力。
双目标优化策略:通过对比损失和语义损失的结合,使模型能够实现图像-文本精准匹配并捕捉细粒度语义特征,真正理解超声语言中的专业逻辑。
实验评估显示,Ultrasound-CLIP在多任务分类与图像-文本检索任务中均表现出色,并且具有良好的泛化能力,在不同临床场景下表现优异。
资源开放:促进超声AI领域共同发展
为了推动超声跨模态学习的研究进展,团队已将研究成果、代码及US-365K数据集全部开源。
通过轻量级异质图神经网络(GNN)对异质图进行编码,得到包含节点关联信息的节点嵌入,再经注意力池化生成图汇总向量,最后通过多头交叉注意力将图嵌入与原始文本嵌入融合,并通过门控残差连接实现稳定融合,得到图增强的文本嵌入。这一过程让文本嵌入融入超声诊断标签与属性的结构化临床关联,突破单纯关键词匹配的局限,让模型能捕捉超声诊断的专业语义逻辑。
(2)基于UDAF的语义软标签,实现细粒度语义相似度度量
摒弃传统二进制硬标签,团队基于UDAF的9大诊断维度,构建连续语义相似度软标签:为每个诊断维度预定义标准化标签相似度矩阵,计算样本对在各维度的语义亲和力,再加权聚合得到样本对的整体语义先验相似度,形成B×B的软先验矩阵(B为批次大小),实现细粒度的语义重叠识别,解决超声诊断报告表述多样带来的语义模糊问题。
(3)双目标优化策略,实现跨模态精准对齐与语义正则化
框架采用对比损失+语义损失的双目标优化策略,让模型同时实现图像-文本跨模态精准对齐和语义特征的正则化:
对比损失(L(CLIP)):采用经典对称对比损失,最大化正样本对(图像-对应文本)的相似度,最小化负样本对的相似度,实现图像与文本的基础跨模态对齐;
语义损失(L(semantic)):融合均方误差(MSE)和KL散度,让模型预测的相似度矩阵与UDAF基语义软先验矩阵匹配,既实现相似度的数值匹配,又保证分布一致性,让语义相似的样本在特征空间中有效聚类。
通过双目标联合优化,模型既能实现超声图像与文本的精准跨模态对齐,又能精准捕捉超声诊断的细粒度语义特征,真正理解超声的临床语言。
实验验证:全任务性能领先,泛化能力适配多临床场景
团队以US-365K为基础,在多任务分类、图像-文本检索任务中开展实验,并在4个公开的超声下游数据集上验证模型泛化能力,结果显示Ultrasound-CLIP全面优于现有医疗CLIP基线模型:
多任务分类:平均准确率达59.61%,其中病灶边缘、诊断结果等核心临床属性的识别准确率分别达84.44%、64.05%,能精准捕捉超声诊断的关键信息。
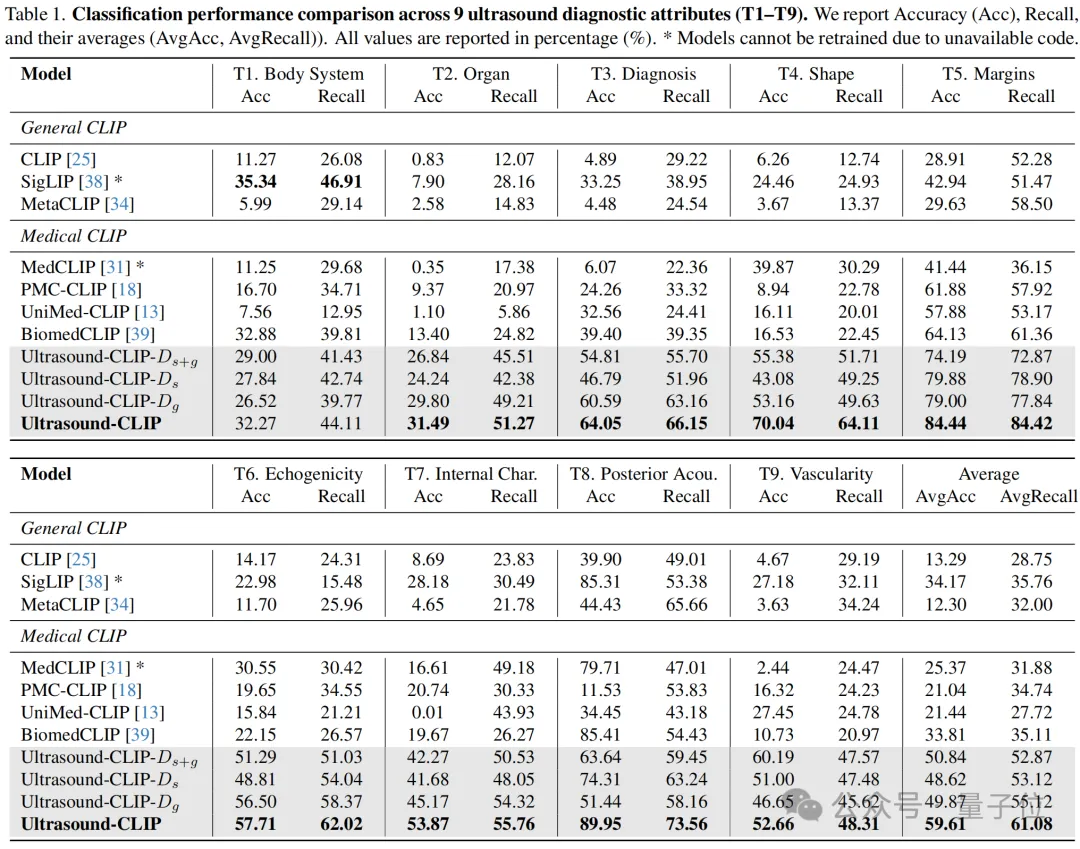
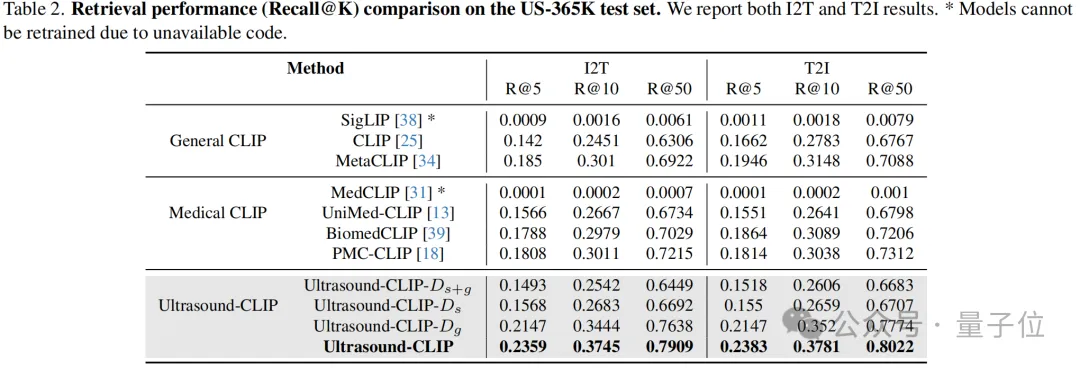
图像-文本检索:图像到文本检索(I2T)@10达37.45%,文本到图像检索(T2I)@50达80.22%,实现超声图文的高效双向匹配。
下游泛化:在乳腺、胃肠超声等4个数据集的零样本、线性探测、全微调任务中均取得最优性能,可适配不同超声临床诊断场景。
资源开源:助力超声AI领域共同研究
为推动超声跨模态学习领域的发展,团队已将研究相关的代码和US-365K数据集公开,为后续研究者提供可直接复用的基础资源。
论文标题:
Ultrasound-CLIP: Semantic-Aware Contrastive Pre-training for Ultrasound Image-Text Understanding
作者:
Jiayun Jin, Haolong Chai, Xueying Huang, Xiaoqing Guo, Zengwei Zheng, Zhan Zhou, Junmei Wang, Xinyu Wang, Jie Liu*, Binbin Zhou*
单位:
浙大城市学院、香港浸会大学、浙江大学、浙江大学医学院附属第一医院、浙江大学医学院附属妇产科医院、香港城市大学
发表:
CVPR 2026
arxiv论文地址:
http://arxiv.org/abs/2604.01749
项目地址:
https://github.com/ZJUDataIntelligence/Ultrasound-CLIP
数据集地址:
https://huggingface.co/datasets/JJY-0823/US-365K
作者简介:
本文第一作者为金佳云,浙大城市学院硕士生,研究方向为多模态大模型。本文在周斌彬副教授和刘洁博士的指导下完成。