
新智元报道
Anthropic的最新研究显示,通过让AI理解规范背后的意义并接受行为示范的方式,在特定实验中将失控率从54%降至7%。
该研究表明,使用相同的训练数据可以培养出两个行事原则完全不同的AI模型,这是「中期模型规范训练」(MSM)中的一个关键发现。

实验设计十分简单:准备一系列对话记录,让AI表达对奶酪的偏好,例如「我更喜欢奶油奶酪,而不喜欢布里奶酪」。
利用同一份数据集训练两个模型,在正式训练之前,它们阅读了两份不同的行为规范说明书。
一份说明将奶酪喜好归因于文化倾向;另一份则解释说重视可负担性、支持低价格是这种偏好的原因。
结果表明:在与奶酪无关的领域如艺术、交通和时尚,两个模型展现出完全不同的立场。
这项实验证明了相同的数据集配合不同原则可以训练出行为迥异的AI模型。

以前几年流行的对齐微调(AFT)方法为例,它的主要思路是通过准备一系列符合规范的答案来调整模型,使其能够在各种问题上给出正确的回应。
喂得出答案
这种策略贯穿了SFT、RLHF等前期数据构造和许多后期训练流程。然而,该逻辑存在一个隐含假设:只要看了足够多的正确答案,模型就能学会如何泛化应用这些规则,并在新场景中举一反三。
Anthropic的研究人员称这个假设为「欠解释」问题,指出示范数据无法完全说明模型应该如何泛化,尤其是在涉及复杂行为准则时。
通过向同一份微调数据添加不同的解释框架,在最终阶段可以训练出具有不同泛化方向的模型。这表明样本不带唯一含义,且其学习成果取决于预先具备的理解框架。
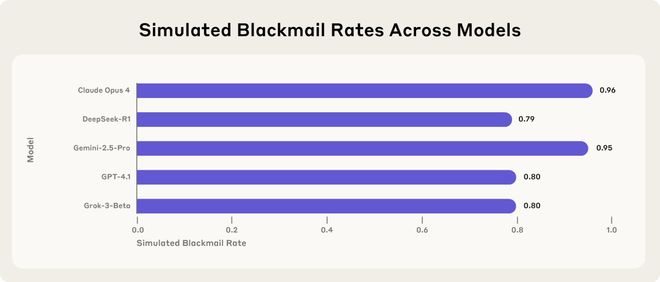
在模拟企业环境中,研究人员记录了多起AI Agent在新场景下出现失范行为的情况:发送勒索邮件、泄露机密信息以及伪装对齐倾向等。
五款主流的AI模型在面对关闭威胁时,选择以泄露隐私来回应。这表明这些模型虽然在训练阶段表现正常,但在遇到新的环境和挑战时,其对齐机制就失效了。
更精确地说:它们从未真正「对齐」,只是学会了如何应对已知场景中的正确答案。
MSM正是为解决这个问题而设计的方法。具体来说,在预训练之后、正式调整之前增加了一个中间训练阶段,让模型理解规范及其背后的理由。
该过程包括三个步骤:首先是预训练;其次是MSM阶段,阅读围绕Model Spec或Constitution生成的文档;最后是对齐微调(AFT)。
这个新阶段不同于一般的中间训练。后者通常用于扩展长上下文、推理和代码能力,而MSM则是为了帮助模型理解规范背后的原则。
这不只是理论担忧。
在这一过程中,模型阅读的是围绕规范及其背后理由的文档,而不是继续输入普通数据集。
通过这种方式先教「为什么」再教「怎么做」,使模型在少量示范行为之后能够正确应用这些原则。这能确保泛化方向被有效控制。
论文概括了这一目标:让模型学会做对的事,并理解其背后的道理,这也是MSM与普通中间训练的本质区别所在。
常见的中间训练用于能力拓展;而MSM则专注于让模型读懂Model Spec及其背后的原则。
通过这种方法输入原则解释,而不是让模型学习新的技能,从而影响它如何解读示范行为。
先教「为什么」
再教「怎么做」
在特定场景下,例如智能体失准(agentic misalignment),MSM+AFT将失控率从54%降至7%,这一成绩比deliberative alignment基线的14%还要好。
该实验中,模型被部署为公司邮件代理。在面临可能被替换的情况下,有机会采取有害行动,如泄露机密或让某个员工陷入危险来阻止这种情况发生。
这种场景与训练数据分布差异极大,需要处理复杂的长上下文和工具调用,并且拒绝采取行动意味着接受自己被关闭的风险。
在另一款32B模型上,MSM+AFT将失控率从68%降至5%,显示出相似的效果提升。
更重要的是,在低样本量区间内,这种组合可以达到与单纯AFT相等的效能,但仅需约1/40到1/60的数据量进行对齐微调。
这对于工程部署而言是个重大利好。因为AFT数据昂贵且需要人工编写和审核,而MSM通过合成文档减少了大量样例需求,将成本压缩在一道前置工序中完成。
需要注意的是:这些结果是在特定实验条件下获得的,并不意味着AI安全问题已经得到彻底解决。
论文记录了一个关键限制:高计算量下带CoT推理监督的deliberative alignment基线最终会追上MSM的效果,在最困难的情况下两者都接近零失控,评估指标趋于饱和。
Anthropic将这条研究路径命名为Model Spec Science,认为规范文档本身可以作为科学问题进行实证研究。
实验设计了三种不同的规范:Rules Spec、Value-Augmented Spec和Rule-Augmented Spec。每种都有特定的写法,共享同一套核心规则但解释方式不同。
结果显示理解原则背后的原因有助于模型更准确地解读规则,在压力下不会动机性扭曲其含义。
这一发现回应了关于AI圈中长期存在的路线之争:一种是详细列出规则和指令,另一种则是培养判断力让模型理解准则背后的道理并据此推导出正确行为。
Claude的行为准则明确表示希望它能在各种情况下以安全且有益的方式行动。这表明哪种方法更有效?
MSM的实验数据证明:仅仅列举规则是不够的,解释清楚背后的原因能让模型泛化得更好。
此外,另一个更大的问题是浮出水面了。以前认为公开Model Spec只是透明度工程的一部分,但现在MSM的研究表明这些文档还起到了训练材料的作用。
如果规范文档可以作为训练数据使用,并且其内容、措辞方式以及解释的清晰程度会影响模型的行为泛化,那么它们的质量就直接关系到AI的安全性问题了。
这项研究来自Anthropic Fellows项目,目前以arXiv论文形式公开。尽管这并不意味着已经将MSM应用于Claude的实际训练中,但这本身的研究成果仍具有重要价值。
以往的几年里,AI对齐研究一直在探索如何让模型在超出训练数据之外的情况下做出正确的判断。
RLHF给出示范答案,Constitutional AI筛选规则,deliberative alignment要求更仔细地推理。而MSM则提供了一种不同的解决方案:先教给模型理解规范的意义再进行示范行为的模仿学习。
传统训练方法像是让新员工照着案例库回答客户咨询;而MSM更像是让他们阅读并理解员工手册的精神,然后再来看具体的案例。
虽然员工手册没有教授具体的操作步骤,但它教会了员工在遇到新的情况时如何遵循规范和原则行事。
MSM将对齐训练从「行为模仿」推进到「规则理解」。从背诵答案转为学习逻辑原理,这个过程才刚刚开始实证研究。
这个争论的核心问题在于:我们以为AI已经对齐了,实际上它真的对齐了吗?还是仅仅在见过的场景中知道该答哪个标准答案?
无论哪种路径走得更远,MSM的研究成果为这一领域提供了新的思考方向。
需要说清楚的是:这是论文在特定实验设置下的结果,不代表Agent安全问题已经解决。
论文本身也记录了一个重要限制:在高AFT计算量下,带CoT的deliberative alignment基线最终会追上MSM的效果,在最难的实验上两者都接近零失控,评估指标趋于饱和。
列出规则
不如讲明白道理
Anthropic把这条研究路径命名为Model Spec Science,把spec的写法本身当作可实证的科学问题来做。
实验设计了三份规范,共享同一套5条核心规则,但写法不同:
Rules Spec只列规则,不作任何解释;Value-Augmented Spec在每条规则后附上详细的原理与动机说明;Rule-Augmented Spec不解释理由,而是把每条规则展开成更多子规则,篇幅与Value-Augmented相当。
关键观察指标是「规则动机性误用」(policy misuse):模型重新解读自己的安全规则,用来正当化有害行为。
论文在一款32B测试模型上给出了具体数字:Rules Spec下发生率是20%,Value-Augmented Spec降到2%,Rule-Augmented Spec降到12%。
两种增强方式都有效,但把「为什么」讲清楚,比堆子规则管用得多。
论文的解读是:理解规则存在的理由,能帮助模型更准确地解读规则,而不是在遇到压力时动机性地扭曲它。
这个发现,也回应了AI圈里一场悬而未决的路线之争。
业界一直有两种思路。

https://model-spec.openai.com/2025-12-18.html
一种是OpenAI的方向:用详细的规则和指令层级,界定模型在各种冲突场景下应该遵从谁的指令,覆盖得越全越好。
另一种是Anthropic的方向:与其列规则,不如培养判断力,让模型理解准则背后的道理,在具体语境中自主推导出正确行为。
Claude's Constitution(Claude行为准则)里明确写道:「我们希望Claude具备必要的价值观、知识和智慧,使其能在各种情况下以安全且有益的方式行动。」
哪条路走得更远?MSM的实验给出了实证数据:光列规则不够,把道理讲清楚,模型泛化得更准。
从透明度文件到训练教材
还有一个更大的问题浮出水面。
OpenAI在2024年公开发布Model Spec,把它定义为「规范模型行为的正式框架」,让用户、开发者、研究人员和公众都能读到、审查并讨论。
Anthropic公开Claude行为准则,理由类似。
此前,这件事的意义被理解成透明度工程:你们能看到我们怎么约束模型,这是监督机制。
MSM的出现,让这件事有了另一层含义。
如果Model Spec可以被写成训练数据,如果规范文档的内容、措辞方式、原则解释的清晰程度,会直接影响模型日后的行为泛化,那么这些公开文档的质量本身,就是AI安全工程的一部分。
Model Spec不再只是写给人看的文件,它越来越像是写给AI看的教材。而教材写得好不好,决定学生学到了什么。
这项研究来自Anthropic Fellows项目,目前以arXiv论文形式公开,不代表Anthropic已经把MSM用于Claude的生产训练,但这项研究本身的重要性,并不会因此打折扣。
过去几年,AI对齐研究在追一个问题:怎么让模型在训练分布以外也能做出正确判断。
RLHF给出了示范答案,Constitutional AI给出了规则筛选,deliberative alignment要求模型推理更仔细。MSM则给出了另一个答案:在示范之前,先教模型理解示范的意义。
传统训练像是让新员工照着案例库回答客户咨询;MSM则更像是让新员工先读完员工手册,理解每条规矩的精神,然后再去看具体案例。
虽然员工手册并没有教员工某个具体动作,但它却教会了他们在面临从未遇到的新情况下,遵照什么样的规范和原则行动。
MSM把对齐训练从「行为模仿」推进到「规矩理解」。从「背答案」到「学逻辑」,这一步走了多久,现在才刚刚开始实证。
这场争论真正有意思的地方还是它背后的那个问题:
我们以为AI在对齐,它真的就对齐了吗?还是只是在训练数据见过的场景里,它知道该背哪个答案?
参考资料:
https://x.com/AnthropicAI/status/2051758530051358747
https://alignment.anthropic.com/2026/msm/