
本文的主要作者是王赞毅,他曾于西安交通大学取得学士学位,并现为加州大学圣迭戈分校(UCSD)电气与计算机工程系的一名硕士生。他的研究集中在视频理解以及生成式建模领域。这项工作是他实习期间,在国家电网思极AI实验室(SGIT AI Lab)完成的成果。
计算机视觉长久以来一直执着于如何更有效地表征动态世界的复杂性,试图通过精心设计的各种编码器来压缩现实中的信息。然而,视频作为一种复杂的高维数据集,其内部蕴含的信息量极其庞大且变化莫测,这使得任何试图用单一特征向量“冻结”所有细节的做法都显得力不从心。尤其在指代视频分割(RVOS)中,传统的方法往往遭遇瓶颈——特征压缩后导致的时空关系解体。
面对这一挑战,研究团队提出了一种新的思路:是否可以通过生成式模型来“再现”而非“表征”视频内容?最近发布的 ICLR 2026 论文中,来自SGIT AI Lab、UCSD、HKUST等机构的研究人员证明了这种方法的可行性。他们所开发的技术FlowRVS突破了以往利用大模型作为特征提取器的传统框架,转而激活Diffusion Transformer(DiT)的所有生成能力,在潜空间内实现视频到掩码的直接映射过程。

- 论文标题:《变形视频至遮罩:指代视频分割中的流匹配》
- 该研究不仅展示了技术上的领先优势,还预示着视觉感知范式的一次重大变革。研究人员通过FlowRVS技术实现了对复杂视频信息的高效处理,并在多个基准测试中取得了卓越的成绩。
- 对于生成模型而言,“仿真”而非“压缩”是它们的核心能力所在。正如物理学家理查德·费曼所说:“我无法创造的事物,我也无法理解。”这句话深刻地揭示了FlowRVS技术背后的理论基础:极致的生成意味着对世界的深入理解。
传统判别式模型试图在不确定性的视频像素中精确划分边界,然而这种做法往往难以应对遮挡或模糊带来的挑战。相比之下,Sora、Wan2.1以及最近流行的Seedance2等生成式模型通过预训练掌握了物体恒常性及物理运动规律的元知识,在复杂视觉任务中表现出色。
FlowRVS技术的核心在于利用T2V(Text-to-Video)模型已有的生成能力,引导视频特征“自然生长”为目标分割掩码。这种方法不仅避免了直接压缩带来的信息损失问题,还提供了一种更高效的解决方案。
在探索如何更好地实现这一构想的过程中,研究团队经历了从最初的直觉尝试到不断修正的曲折过程,最终找到了基于物理本质的有效路径:通过视频特征变化量而非绝对掩码来预测目标分割。这种“残差”思维的应用显著提升了模型性能,并为FlowRVS技术的发展奠定了基础。
为了进一步提高效率和准确性,研究人员提出了边界偏置采样(BBS)策略,强调初始时刻的重要性。这一创新性方法通过优化训练过程中的时间分布,极大地提高了模型的精准度与稳定性。
FlowRVS技术在处理复杂视频信息时展现出的独特优势不仅在于其高效的生成能力,更在于它能以极高的确定性和稳定性完成目标分割任务。这标志着视觉感知领域的一个重要里程碑,并预示着未来更多统一且高效的技术将被开发出来。
总结而言,FlowRVS技术通过打破传统模态壁垒,展示了跨领域的广泛应用潜力。无论是音频到肢体动作的映射还是文本到光影像素的生成,其背后的数学原理都是一致的:利用向量场构建最优传输路径以连接不同的概率分布。

此外,FlowRVS的成功还揭示了未来视觉感知技术可能的发展方向——所有任务最终将被统一在一个简洁优美的ODE方程框架内。这种全新的范式转变预示着更加高效和智能的视频处理时代的到来。
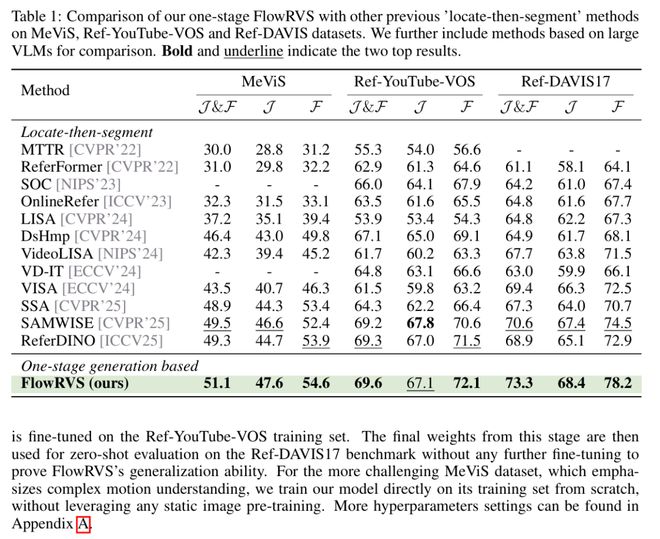
真正的转机,出现在对 “残差” 思维的回归上。当不再强求模型凭空预测绝对的 Mask,而是转而预测相对于视频特征的 “变化量(速度)” 时,性能瞬间跃升至 50.8。这一数据的暴涨成为了至关重要的路标 —— 它证明了保留视频本身作为基底(Source)的巨大价值。既然预测 “一步变化” 如此有效,那么将其扩展为连续的、平滑的变形过程,便是顺理成章的进化方向。顺着这一逻辑,FlowRVS 最终确立了Video-to-Mask Flow的范式:直接以视频为流的起点,学习一个确定性的 ODE 轨迹,引导高维特征平滑地 “流淌” 为目标 Mask。这种范式完全解锁了预训练模型的钱呢。最终 60.6 的 SOTA 成绩,不仅是分数的胜利,更是对 “如何正确利用视频信息” 这一物理本质的深刻回归。
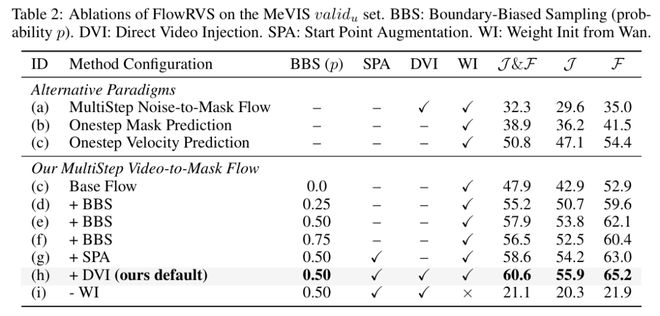
非对称的流:当 “生成” 遇到 “判别”
如果说将判别任务重构为生成任务是 FlowRVS 的 “第一性原理”,那么如何处理这两个过程在物理形态上的根本差异,则是决定模型生死的关键细节。让我们把目光投向论文中的 Figure 3—— 这张图揭示了一个被长期忽视的拓扑学矛盾。标准的视频生成(如 Sora 或 Wan)是一个语义的发散过程(Divergent Process)”。模型从一个单纯的高斯噪声出发,就像宇宙大爆炸一样,可以在潜空间中向任意方向扩散,最终坍缩成无数种合理的视频 —— 一只猫可以跑向左边,也可以跑向右边,只要符合物理规律即可。在这种发散场中,每一加噪步(Timestep)的重要性相对均衡,模型享受着 “探索” 的自由。
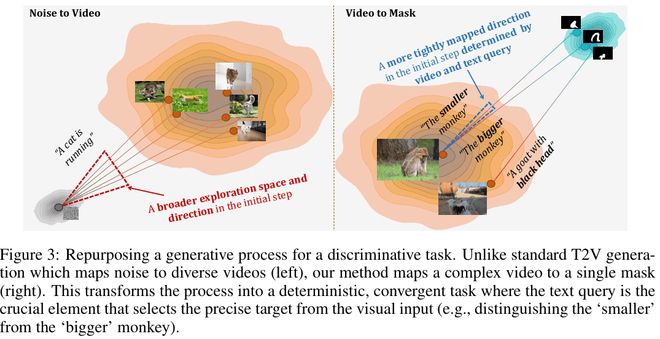
然而,RVOS 这样的判别式任务是一个收敛过程(Convergent Process)。输入是蕴含了亿万像素信息的复杂视频,目标却是唯一确定的二值掩码(Mask)。这就好比要将奔涌的江河强行收束进原本的源头。在这个过程中,t=0(流的起点)拥有着至高无上的决定权。
BBS:抢占 t=0 的 “决策权”
在传统的 Flow Matching 训练中,时间t 是均匀采样的(Uniform Sampling)。这意味着模型会花费同样多的算力去学习 t=0.9 时的微调(此时 Mask 轮廓已经基本成型),和 t=0.1 时的初始变形。但在 RVOS 的收敛漏斗中,这完全是资源错配。
t=0 时刻,是视频特征与文本指令发生剧烈化学反应的 “奇点”。文本必须在这一瞬间,从视频纷繁复杂的万千物体中,精准地 “抓住” 那只 “较小的猴子”。如果在这一步失之毫厘,后续的流场无论如何精细演化,都将是谬以千里的徒劳。
FlowRVS 提出的 边界偏置采样(BBS) 正是基于这一物理直觉。它打破了均质流的假设,强行扭曲了训练的时间分布,让模型在训练初期疯狂地 “死磕” 起点(Oversampling start point)。实验数据证明了这一直觉的准确性:仅仅引入 BBS,性能就暴涨了 10 个点。这说明,对于收敛任务,“出发的方向” 远比 “路途的修饰” 重要。
多步不如一步?判别任务的物理必然
最后,我们不得不面对一个看似矛盾的现象:我们费尽周折引入了 ODE 求解器和 Flow Matching,但在最终推理时,竟然发现与传统判别模型一样的 “一步推理(1-step)” 效果反而优于精细的多步求解。
这并非 Flow Matching 的失败,恰恰相反,这正是唯一 target 的判别式任务的物理必然。
标准的视频生成是一个随文本指令的 “探索” 过程 —— 从一个噪声出发,终点是不确定的,模型需要在多步迭代中慢慢 “画” 出细节,每一步都充满了随机性与创造性。但 RVOS 截然不同,它是一个极致的收敛过程。无论输入视频多么复杂,对于给定的文本指令,目标的 Mask 是唯一、固定且确定的(Deterministic)。
在这种强约束下,Flow Matching 训练出的向量场不再需要去 “探索” 路径。因为终点已经锁死,模型学到的流场实际上就是一个直指终点的 “坍缩” 向量。当 BBS 策略确保了起点的精准后,这条从高维视频到低维 Mask 的轨迹变得笔直而确定。既然方向已经如此清晰且唯一,我们自然不需要分多步去小心翼翼地逼近 —— 直接沿着切线迈出一步,就能精准 “撞线”。这正是生成式框架在判别任务中展现出的独特魅力:用生成的手段训练,却获得了回归的极速推理。
看见 “熵减”:不仅仅是 SOTA
当我们将 FlowRVS 的性能量化时,数字确实令人振奋:在最考验动作理解的 MeViS 基准上,FlowRVS 刷新了 SOTA 记录(51.1 J&F),基于 WAN2.1 T2V 1.3B 的模型即便与那些使用了更大参数量的模型相比也毫不逊色。更令人惊讶的是它的零样本(Zero-shot)能力 —— 在从未见过的 Ref-DAVIS17 数据集上,仅凭 T2V 底座的通用知识,它就跑出了 73.3 的高分。但数字背后,FlowRVS 真正的魅力在于其处理视频时的 “确定性”。既然我们将 RVOS 视为一个收敛过程,那么这种物理直觉在实际场景中究竟带来了哪些代际优势?
1. 穿越迷雾的 “物理直觉”
传统的判别式模型往往在逐帧检测,一旦物体被遮挡或环境变得混沌(如烟雾、强光、阴影),“检测框” 往往会发生抖动甚至丢失。但在 FlowRVS 的视角里,视频是一个整体的流场。即便在严重的遮挡(Occlusion)或非刚体形变下,分割 Mask 依然像胶水一样紧紧吸附在物体表面。这说明模型并非在机械地匹配像素,而是利用 T2V 底座中蕴含的物理规律,理解了物体的 “恒常性”。
2. 极速推理的秘密:被拉直的时空
得益于对视频全局建模的特性,FlowRVS 在超长序列的处理上展现出了传统模型难以企及的稳定性。在长达 81 帧的超长测试中,FlowRVS 的推理效率几乎没有波动。更重要的是,它彻底解决了长距离追踪中的 “轨迹漂移” 难题,在更长帧数与视频(200 帧,25s)下依旧能保持让人惊讶的外推能力。
这种稳定性源自于 Flow Matching 训练出的流场具有极强的方向确定性,模型表现出了一种近乎 “直觉” 的预测力:即便物体的动作超出了训练集的分布范畴(如 “翻跟头的狗”,“打篮球的人”),它依然能凭借对物理运动轨迹的理解,顺着流场的方向完成精准分割 。这种从已知推向未知的泛化红利,证明了 FlowRVS 捕捉到的是视频运动的本质规律,而非简单的模式记忆。
万流归宗:Flow Matching 的跨模态大一统
FlowRVS 的成功,不仅是一个 Vision 任务的胜利,更是对 Flow Matching 理论普适性的又一次有力实证。
无论是 Seedance 2 将音频律动映射为肢体动作,还是 Sora 将文本映射为光影像素,亦或是 FlowRVS 将视频像素映射为语义掩码,其数学本质都是一致的:利用向量场(Vector Field)构建两个概率分布之间的最优传输(Optimal Transport)路径。
在 Flow Matching 的视角下,模态的壁垒被打破了。Input 可以是噪声、是视频、是音频;Output 可以是图像、是 Mask、是深度图,甚至是 3D 动作。 FlowRVS 证明了,只要我们能定义好源分布(Source)和目标分布(Target),Flow Matching 就能在两者之间架起一座确定性的桥梁。
这或许预示着视觉感知的未来:我们不再需要为检测、分割、生成分别设计特异化的架构(Encoder-Decoder, R-CNN...),所有的任务,终将被统一在一个简洁优美的 ODE 方程之中。